千份报告揭示AI研究助手致命弱点:OPPO发布FINDER基准与DEFT分类法

AI研究助手(Deep Research Agents, DRA)正火,号称能自动检索、分析并撰写出分析师级别的深度报告。但它们真的靠谱吗?
ArXiv URL:http://arxiv.org/abs/2512.01948v1
一份基于近千份AI报告的深度剖析揭示了残酷真相:即使是顶级模型,也常在关键环节“翻车”。
来自OPPO的研究揭示了当前AI研究助手距离“真正有用”还有多远,并为此提出了一个全新的评测基准FINDER和一个首创的失败分类法DEFT。这项研究不仅指出了问题,更精确诊断了病因。
现有评测的困境
尽管AI研究助手潜力巨大,但我们如何衡量其产出报告的质量?
过去的评测基准大多来自问答(QA)任务,这与生成一份结构完整、逻辑严谨、论证深入的综合报告相去甚远。
另一些开放式基准,虽然更接近真实场景,但其任务设计和评估标准往往充满主观性,难以进行标准化、可复现的横向比较。这导致我们无法准确判断一个AI助手到底“好”在哪里,“差”在何处。

更精细的“标尺”:FINDER基准
为了解决上述问题,该研究推出了精细化深度研究基准(Fine-grained DEepResearch bench, FINDER)。
它不是对现有基准的简单修补,而是一次全面的升级。FINDER包含100个由人类专家精心设计的深度研究任务。
更关键的是,它为每个任务配备了总计419个结构化的核查清单(Checklist)。
这些清单明确规定了报告应有的结构、分析深度和事实引用标准,就像一份详尽的评分指南,让评估过程变得更加客观和可复现。
通过对任务提示词进行精细化重写,FINDER确保了任务的复杂性和对人类真实需求的贴近度,从根本上提升了评测的有效性。
首个“失败诊断书”:DEFT分类法
找到了衡量好坏的“标尺”还不够,我们还需要一本诊断问题的“说明书”。
为此,研究团队基于对主流AI研究助手生成的近1000份报告的详尽分析,提出了首个深度研究失败分类法(Deep rEsearch Failure Taxonomy, DEFT)。
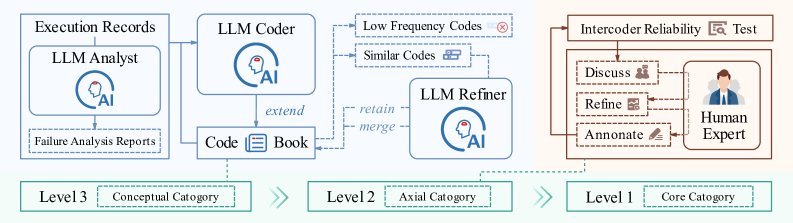
DEFT的构建过程极为严谨,它借鉴了质性研究中的“扎根理论”,通过一个“人机协作”的框架,历经开放、关联和核心三轮编码过程,最终提炼而成。
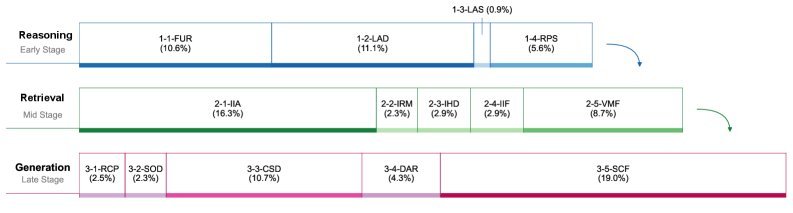
这个分类法将AI研究助手的失败模式归纳为三大核心维度,并进一步细分为14种具体的失败类型。
实验揭示的残酷现实
研究团队在FINDER上对一系列主流系统进行了全面评测,包括:
-
商业闭源API:如Gemini-2.5-Pro Deep Research, O3 Deep Research等。
-
开源模型:如MiroThinker, WebThinker等。
-
Agent框架:如OWL, OpenManus, MiroFlow等。
结果发人深省。
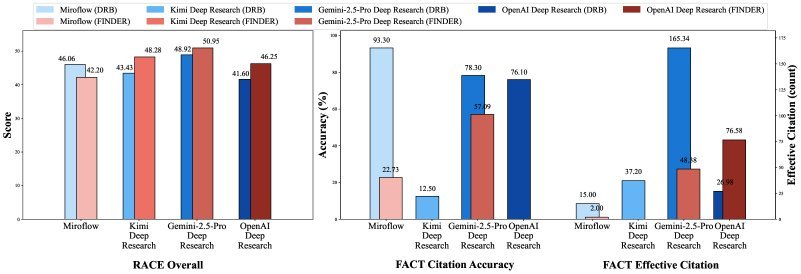
| 模型/框架 | RACE | FACT | $S_{reasoning}$ | $S_{retrieval}$ | $S_{generation}$ | Checklist通过率 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 50.95 | 62.43 | 79.16 | 77.01 | 77.29 | 63.01% |
| Kimi K2 | 48.28 | 58.73 | 83.67 | 83.67 | 60.10 | 66.59% |
| O3 Deep Research | 46.25 | 65.98 | 76.43 | 76.43 | 64.95 | 57.52% |
| WebThinker | 42.47 | 37.19 | 66.85 | 65.54 | 55.41 | 61.10% |
| MiroFlow (En) | 42.20 | 36.43 | 67.54 | 66.21 | 55.41 | 72.19% |
从上表可以看出:
-
Gemini在RACE(报告质量)和DEFT指标上表现均衡,综合实力强劲。
-
Kimi K2在推理($S_{reasoning}$)和检索($S_{retrieval}$)阶段表现突出,甚至超越Gemini,但在生成($S_{generation}$)阶段得分大幅下降。
-
O3在FACT(事实准确性)方面遥遥领先,显示出卓越的引文可靠性。
-
Agent框架MiroFlow在Checklist通过率上夺冠,证明了其在遵循复杂指令和流程方面的优势。
最关键的发现是:当前AI研究助手最大的瓶颈并非任务理解,而在于证据整合、事实核查和最终的内容生成。
深度剖析三大失败维度
DEFT分类法为我们提供了一个清晰的诊断框架,让我们看看AI都在哪些地方“犯错”。
1. 推理(Reasoning)失败
这类失败发生在任务执行的初始阶段,主要源于对用户意图或问题细节的考虑不周。
-
需求理解失败(10.55%):未能准确把握任务的核心要求。
-
分析深度不足(11.09%):报告内容肤浅,缺乏洞察。
-
规划策略僵化(5.60%):无法根据任务动态调整研究路径。
研究为此提出了推理韧性(reasoning resilience)的概念。强大的推理能力不等于稳定的性能,只有具备韧性的系统才能在复杂动态的任务中持续校准,最终产出高质量结果。
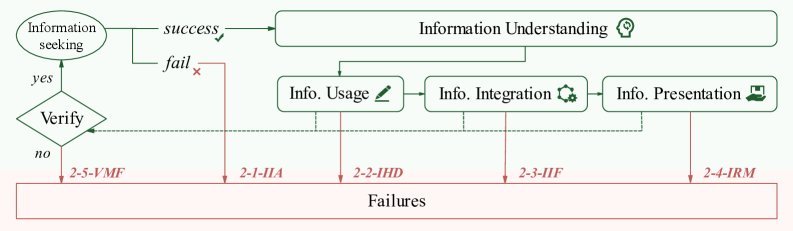
2. 检索(Retrieval)失败
这类失败发生在信息搜集和整合阶段,是AI研究助手能力的核心短板。
-
外部信息获取不足(16.30%):这是最常见的检索失败,意味着Agent没能找到足够或相关的资料。
-
信息整合失败(2.91%):找到了资料,但无法有效融合进报告。
-
验证机制失效(8.72%):未能有效核查信息的真实性,导致引用错误或事实偏差。
3. 生成(Generation)失败
这是任务的最后一步,也是失败的“重灾区”,占比高达39%。
-
内容规格偏离(10.73%):报告的格式、风格或长度不符合要求。
-
分析严谨性不足(4.31%):论证过程缺乏逻辑,结论草率。
-
策略性内容捏造(18.95%):这是最值得警惕的失败!AI为了让报告看起来“专业”,会生成一些看似合理但实际上毫无根据的内容。这种“高级幻觉”比明显的错误更具欺骗性。
结论
这项研究工作为我们描绘了一幅AI研究助手发展的真实图景。通过创新的FINDER基准和DEFT失败分类法,我们得以精确度量和诊断AI在深度研究任务中的表现。
结果表明,我们距离“真正有用”的AI研究助手还有很长的路要走。未来的研究重点不应仅仅是提升模型的推理上限,更要关注证据整合、事实核查与生成约束,并着力构建更强的推理韧性,才能让AI真正成为我们可靠的研究伙伴。