HPLT 3.0: Very Large-Scale Multilingual Resources for LLM and MT. Mono- and Bi-lingual Data, Multilingual Evaluation, and Pre-Trained Models
-
ArXiv URL: http://arxiv.org/abs/2511.01066v2
-
作者: Veronika Laippala; Jörg Tiedemann; Bhavitvya Malik; Laurie Burchell; Barry Haddow; Mikko Aulamo; Andrey Kutuzov; Sampo Pyysalo; Vladislav Mikhailov; Risto Luukkonen; 等22人
-
发布机构: Charles University; Edinburgh University; Prompsit Language Engineering; The Common Crawl Foundation; University of Helsinki; University of Oslo; University of Turku
TL;DR
本文发布了HPLT 3.0,一个包含近200种语言、总量达30万亿token的开源、大规模、高质量多语言文本数据集,并提供了完整的开源数据处理流程、多语言评估框架及预训练模型,旨在推动LLM和MT研究的普及化。
关键定义
- HPLT 3.0: 本文发布的核心资源,是一个大规模(30万亿token)、高质量、多语言(近200种语言)的文本数据集,专为大型语言模型(LLM)的预训练而设计。它源自网络爬虫数据,并经过精细处理、标注和过滤。
- WDS (Web Docs Scorer) Levels: 一种对文档质量进行综合评分的机制。该分数整合了文本长度、语言分布、非常见信号等多种启发式规则,用于衡量文档的质量。在HPLT 3.0中,文档根据WDS分数被分箱(binning),以便用户可以根据质量需求进行灵活的数据采样。
- HPLT-E: 本文开发的一个自动化、大规模的多语言评估框架。它旨在系统性地比较和优化不同数据准备策略对模型性能的影响,覆盖9种语言、127项任务,并通过多提示(multi-prompt)设计来减轻模型对提示的敏感性。
相关工作
当前,用于预训练大型语言模型(LLM)的海量文本数据集是人工智能时代的“原油”。然而,从原始网络数据中“提炼”高质量数据集的过程通常需要巨大的计算资源和技术实力,这导致该领域多由大型企业主导,且成果往往集中于英语。虽然已有如C4、FineWeb、MADLAD-400等公开数据集,但高质量、超大规模且覆盖广泛语言的开放资源仍然稀缺。
本文旨在解决这一瓶颈问题,通过发布迄今为止可能是最大的公开多语言预训练数据集HPLT 3.0,以及完全开源的数据处理流程、评估工具和预训练模型,致力于“民主化”当前的LLM和机器翻译(Machine Translation, MT)研究格局,特别关注对非英语语言的支持。
本文方法
本文的核心贡献是构建并发布了HPLT 3.0数据集及其一系列配套资源。整个方法论涵盖了从原始数据收集到最终模型评估的全过程。
数据来源
本文的数据基础极大扩展了前序工作HPLT 2.0的范围。原始数据来自两个主要来源:
- 互联网档案 (Internet Archive, IA): 使用了2012-2020年间约3.3 PB的“宽泛爬取”数据。
- 通用爬取 (Common Crawl, CC): 结合了2014-2025年间的57个CC完整快照,特别是2020年之后的所有可用数据,原始数据量是HPLT 2.0的五倍。 总计处理的原始网络档案数据量约为7.2 PB。
数据处理流程
本文对HPLT 2.0的开源处理流程进行了升级和扩展,关键步骤如下图所示:
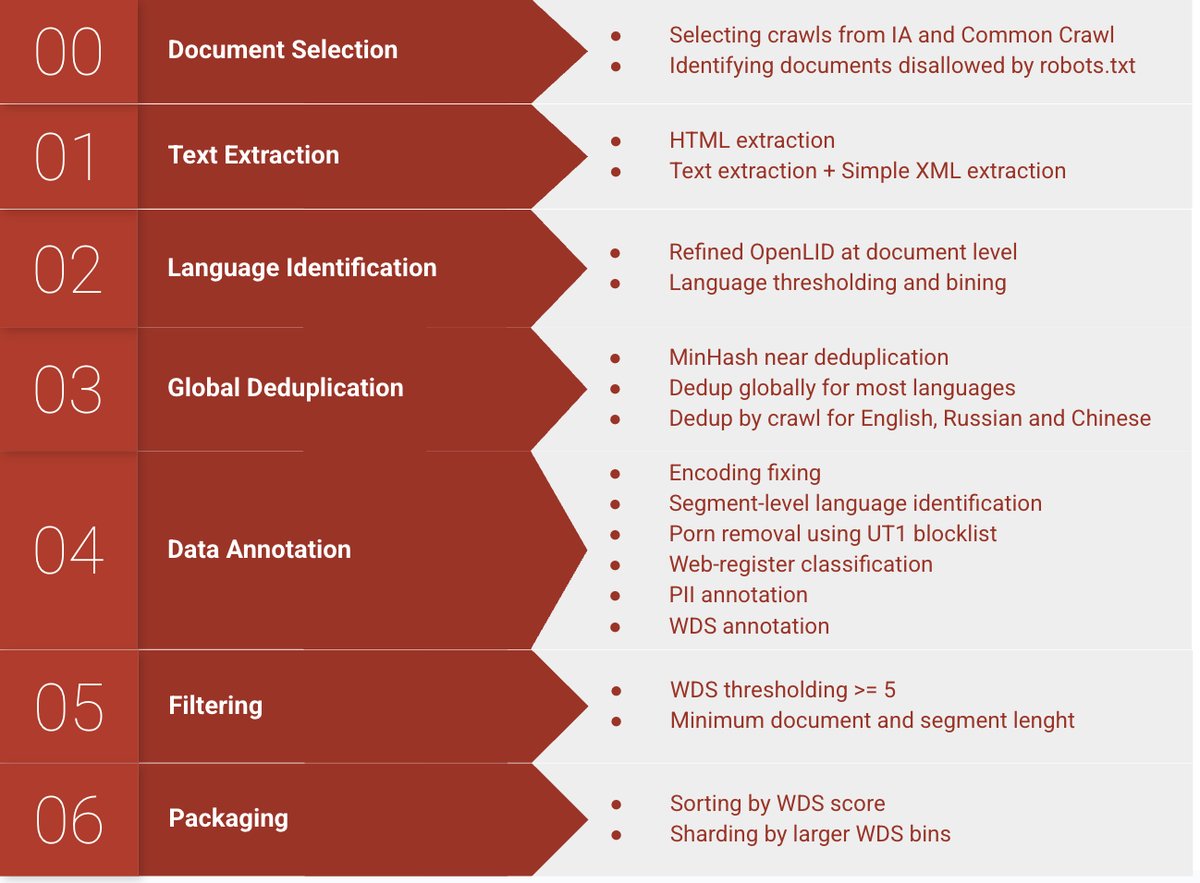
创新点
- 文本提取: 沿用\(Trafilatura\)框架,但通过数据驱动的方式全面优化其超参数,优先保证提取质量而非速度或召回率。
- 语言识别: 采用更新的\(OpenLID-v2\)模型,对齐了Flores评估集的语言标签,并增加了对多种语言的训练数据。输入预处理流程被简化为语言无关的流程(标准化空格、小写化、移除数字和非单词字符),增强了对网络文本中非标准拼写的鲁棒性。
- 去重: 实施了基于\(MinHash\)的全局近乎去重策略,应用于除英语、俄语和中文之外的所有语言(这三种语言因计算效率考虑仍采用按爬取批次去重)。这与HPLT 2.0的按批次去重相比,显著提升了数据集的文本多样性。
- 注解: 引入并优化了\(Web Docs Scorer (WDS)\)作为核心注解工具,用于评估文档质量。同时,更新并重新训练了\(Turku web register classifier\),为104种语言提供了语域(register)标签。
- 封装与分发: 为了便于用户进行灵活的实验,HPLT 3.0数据集内的文档按WDS质量等级(5到10级)进行分箱,并全局排序。数据以Zstandard压缩的JSONlines格式公开发布,可通过HTTP下载。
数据集整体统计
如下表所示,HPLT 3.0在规模上远超其他公开的多语言数据集。其非英语部分的token数量约是FineWeb的2-3倍,MADLAD-400的5倍。
| 数据集 | 分区 | 文档数 (B) | Token数 (T) | 平均长度 | 占非英语% |
|---|---|---|---|---|---|
| HPLT 3.0 | 总计 | 17.9 | 29.7 | 1659 | |
| 英语 | 8.8 | 15.6 | 1772 | ||
| 非英语 | 9.1 | 14.1 | 1549 | ||
| 德语 | 0.82 | 1.15 | 1402 | 8.16 | |
| 法语 | 0.69 | 1.05 | 1521 | 7.45 | |
| 西班牙语 | 0.81 | 1.02 | 1259 | 7.23 | |
| FineWeb | 总计 | 15.1 | 9.0 | 596 | |
| 英语 | 9.9 | 6.0 | 606 | ||
| 非英语 | 5.2 | 3.0 | 576 | ||
| HPLT 2.0 | 总计 | 5.0 | 7.3 | 1460 | |
| 英语 | 2.5 | 3.7 | 1480 | ||
| 非英语 | 2.5 | 3.6 | 1440 | ||
| MADLAD-400 | 总计 | 0.9 | 2.8 | 3111 | |
| 非英语 | 0.9 | 2.8 | 3111 |
数据深度分析
- 描述性统计: HPLT 3.0的平均唯一片段比例为73%,显著高于HPLT 2.0的52%,这得益于全局去重策略。
- 互联网域名: HPLT 3.0展示了更广泛的域名多样性。与HPLT 2.0相比,来自维基百科的文档比例显著降低,说明重复内容被有效滤除。
- N-grams分析: 高频n-gram分析显示,与HPLT 2.0相比,HPLT 3.0中与维基百科相关的内容显著减少。同时,也发现了一些低质量文本的信号,如成人或博彩内容。
- 语域标签: 全局去重导致语域分布发生变化。HPLT 3.0中,博客(\(Blog/Forum\))内容的比例相较于百科全书式(\(Encyclopedic\))文章有所增加。
人工评估
对23种语言的随机样本进行了人工检查。结果表明,大多数语言中色情内容的比例低于2%,语言识别错误率也很低(波斯尼亚语和阿斯图里亚斯语除外)。不自然文本和含干扰项文本的比例在不同语言间差异较大,这与标注的主观性有关。
| 语言 | 色情内容 (%) | 格式干扰 (%) | 不自然文本 (%) | 语言识别错误 (%) |
|---|---|---|---|---|
| 阿斯图里亚斯语 | [0, 4.2] | [28.3, 44.1] | [19.2, 33.6] | [29.2, 45.1] |
| 巴斯克语 | [0.3, 4.3] | [15, 27.2] | [0.8, 5.8] | [1.5, 7.3] |
| 波斯尼亚语 | [0, 4.2] | [5.8, 16.5] | [2.2, 10.3] | [81.5, 92.8] |
| 加泰罗尼亚语 | [0, 2.3] | [14.1, 22.8] | [1.3, 5.4] | [2.1, 6.7] |
| 捷克语 | [0, 0.4] | [8.1, 11] | [14.1, 17.6] | [0, 0.4] |
| 英语 | [0.6, 1.4] | [18.2, 21.6] | [7.4, 9.9] | [0, 0.4] |
| 芬兰语 | [0.3, 4.3] | [6, 14.8] | [1, 6.2] | [0, 2.3] |
| 法语 | [0.7, 3.2] | [10.2, 16.5] | [2.8, 6.7] | [0.1, 1.3] |
| 加利西亚语 | [0, 1.9] | [14, 21.4] | [15.2, 22.8] | [0.5, 3] |
| 德语 | [0.7, 3.2] | [16.5, 23.6] | [1.3, 4.5] | [0, 1] |
| 挪威语(Bokmål) | [0.3, 4.3] | [9.6, 19.3] | [1.5, 7.3] | [0, 2.3] |
| 挪威语(Nynorsk) | [0.3, 4.3] | [10.4, 20.3] | [0, 2.3] | [0, 2.3] |
| 西班牙语 | [0.5, 2.4] | [13.2, 18.9] | [1.3, 4.2] | [0.1, 1.3] |
| 乌克兰语 | [0.1, 2.9] | [22.4, 33] | [8.1, 16.3] | [0.1, 2.9] |
| 23种语言均值 | [0.4, 2.3] | [14.9, 21.1] | [6.9, 11.2] | [4.5, 8.8] |
实验结论
本文通过训练和评估一系列语言模型,验证了 HPLT 3.0 数据集的质量和有效性。
多语言LLM评估 (HPLT-E)
通过新开发的HPLT-E框架,本文对在不同数据集上预训练的2.15B参数解码器模型进行了比较。
数据集比较
如下图所示,在7种语言的26个精选任务上,所有模型性能都随着预训练的进行而单调提升。
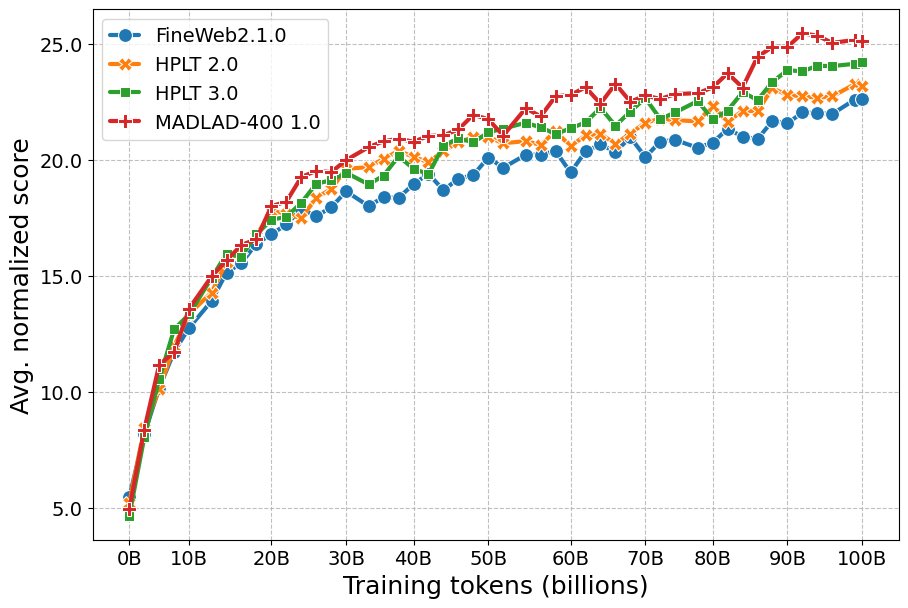
- 性能排序: 在多语言综合得分上,\(MADLAD-400\) 训练的模型表现最佳,其次是 \(HPLT 3.0\)。\(HPLT 3.0\) 的表现显著优于 \(HPLT 2.0\) 和 \(FineWeb\)。
- 结论: 结果表明,HPLT 3.0精细化的数据处理流程带来了模型性能的实质性提升。同时,规模更小、年代更早的MADLAD-400表现出色,值得进一步研究。
按质量估计采样
为了验证WDS质量分数的作用,本文对西班牙语HPLT 3.0数据集进行了三种采样策略实验:随机采样(\(random\))、仅使用最高分数据(\(top\))和仅使用最低分数据(\(bottom\))。
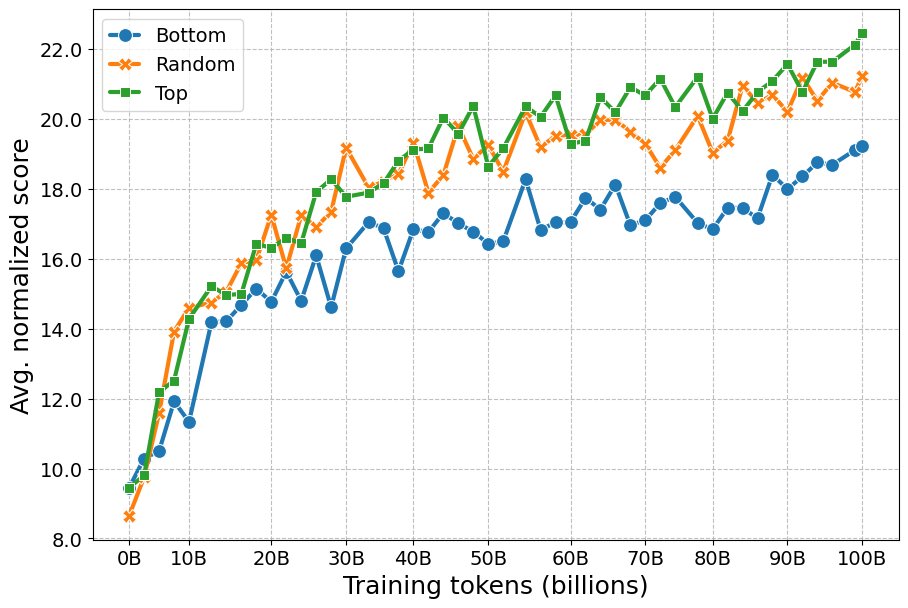
- 结果: 使用低WDS分数的数据(\(bottom\))显著损害了模型性能。而仅使用高质量数据(\(top\))并未明显优于从整个数据集中随机采样,这可能归因于数据多样性的下降。
- 结论: WDS是衡量数据质量的有效指标。在预训练中,避免使用低质量数据至关重要,但过分追求最高质量而牺牲多样性可能并非最优策略。
单语Encoder-Decoder模型
本文还训练并发布了57个特定语言的单语 \(encoder-decoder\) 模型(类似T5-base架构),以评估 HPLT 3.0 在更广泛语言上的适用性。
| 语言 | 模型 | NER (F1) | MultiBLIMP (Acc) |
|---|---|---|---|
| 英语 | HPLT 3.0 T5 | 86.84 | 85.92 |
| mT5-base | 79.13 | 82.38 | |
| HPLT 2.0 BERT | 87.21 | — | |
| 捷克语 | HPLT 3.0 T5 | 88.66 | 83.18 |
| mT5-base | 84.15 | 71.91 | |
| HPLT 2.0 BERT | 88.58 | — | |
| 芬兰语 | HPLT 3.0 T5 | 92.29 | 63.88 |
| mT5-base | 91.07 | 70.21 | |
| HPLT 2.0 BERT | 91.95 | — | |
| 法语 | HPLT 3.0 T5 | 88.60 | 82.35 |
| mT5-base | 86.43 | 77.01 | |
| HPLT 2.0 BERT | 88.94 | — | |
| 西班牙语 | HPLT 3.0 T5 | 87.21 | 84.34 |
| mT5-base | 84.77 | 81.33 | |
| HPLT 2.0 BERT | 87.12 | — | |
| 均值(57种语言) | HPLT 3.0 T5 | 83.18 | 74.19 |
| mT5-base | 82.59 | 71.32 | |
| HPLT 2.0 BERT | 83.56 | — |
- 结果: 如上表所示,在命名实体识别(NER)和语言能力(MultiBLIMP)任务上,基于HPLT 3.0训练的单语T5模型表现出色。
- 结论: 在NER任务上,这些模型的性能与基于HPLT 2.0训练的BERT模型相当,同时作为encoder-decoder架构更具通用性。在语言能力评估中,它们平均优于多语言的mT5-base模型。这再次证明HPLT 3.0是跨多种语言的高质量训练数据。