83亿参数新SOTA!混元Video 1.5开源,推理加速87%,RTX 4090轻松跑

当Kling、Veo、Sora等闭源模型不断刷新视频生成的上限时,开源社区却在性能与效率的平衡木上艰难前行。要么模型太大难以部署,要么效果不尽人意。
ArXiv URL:http://arxiv.org/abs/2511.18870v2
这个困局,现在被打破了。
HunyuanVideo 1.5来了!它以仅83亿的轻量参数,实现了开源领域最顶尖的视觉质量和动态连贯性,更重要的是,它能在消费级GPU(例如RTX 4090)上高效运行!
两阶段高清生成框架
HunyuanVideo 1.5的核心是一个巧妙的两阶段生成管线。
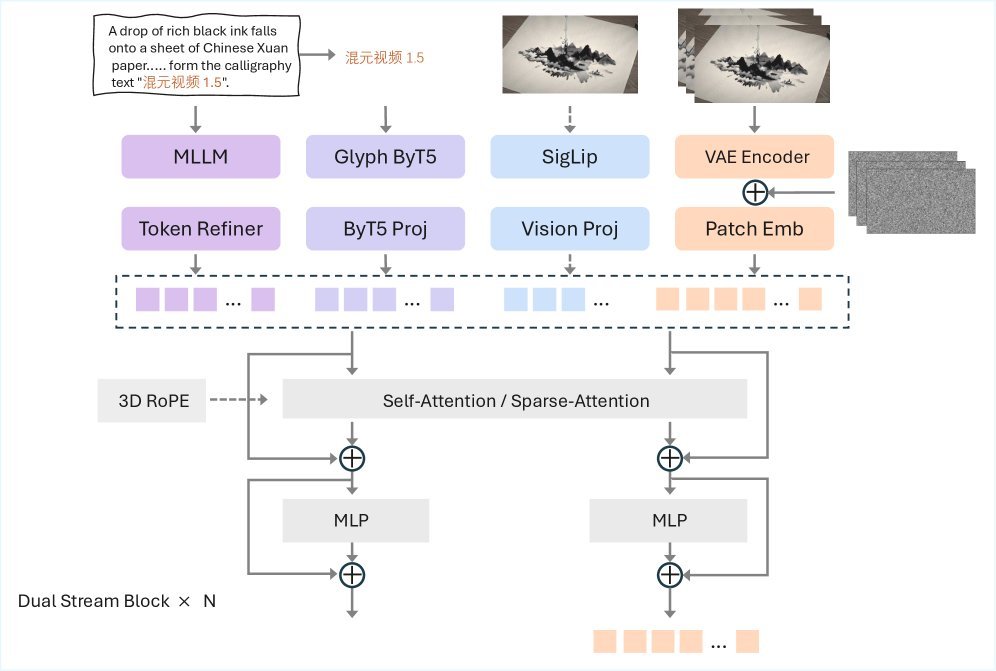
第一阶段,一个83亿参数的统一扩散Transformer(Unified Diffusion Transformer, DiT)作为主力。它能同时处理文生视频(T2V)和图生视频(I2V)任务,生成480p到720p分辨率、5到10秒的初始视频。
第二阶段,一个专用的视频超分网络(Video Super-Resolution, VSR)接力,将视频分辨率提升至惊人的1080p,同时锐化细节、修正伪影,让最终画面质感大幅提升。

稀疏注意力SSTA:为长视频推理加速
长视频生成的一大瓶颈是Attention机制带来的巨大计算开销。
为此,该研究引入了一种创新的选择性滑动切块注意力(Selective and Sliding Tile Attention, SSTA)机制。
它能智能地“剪枝”,动态剔除时空维度上冗余的Token,从而大幅降低长视频序列的计算负担。
效果如何?在生成10秒720p视频时,SSTA相比FlashAttention-3,实现了端到端1.87倍的推理加速!
精准理解:更懂中文与画面细节
一个好的视频模型,不仅要画得好,更要“听得懂”。
HunyuanVideo 1.5在多模态理解上下足了功夫。它利用一个大型多模态模型实现精准的中英双语理解,并结合ByT5进行专门的字形编码。
这意味着,它不仅能理解“画一只熊猫”,还能在视频画面中准确地生成汉字或字母,解决了许多模型“文盲”的痛点。
此外,模型还能识别并理解镜头语言,比如“推镜头”、“摇镜头”等,让用户可以更精细地控制视频的动态效果。
渐进式训练:从优秀到卓越
罗马不是一天建成的,好模型也需要精心“修炼”。
HunyuanVideo 1.5采用了一套多阶段的渐进式训练策略。
预训练阶段:从文生图(T2I)开始,逐步扩展到文生视频(T2V)和图生视频(I2V),通过混合任务训练,为模型打下坚实的语义对齐、视觉多样性和时间连贯性基础。
后训练阶段:通过持续训练(CT)、监督微调(SFT)和人类反馈对齐(RLHF)三部曲,对模型进行精细打磨,显著提升了动态一致性、美学质量和人类偏好对齐度。

性能与亲民兼得
在与多个主流开源模型的GSB(Good/Same/Bad)盲测中,HunyuanVideo 1.5在文生视频和图生视频任务上均取得了压倒性的胜利,被超过100名专业評測員一致认为是新的SOTA(State-of-the-Art)。

最令人兴奋的是它的亲民性。通过模型架构优化和多种卸载技术,在生成720p、121帧的视频时,峰值显存占用仅为13.6GB。
这意味着,你只需要一张消费级的RTX 4090显卡,就能在本地畅快地体验SOTA级别的视频生成!
结语
HunyuanVideo 1.5的开源,无疑为整个AI视频生成领域注入了一剂强心针。它用一个83亿参数的轻量级模型,证明了开源社区同样能达到媲美顶尖闭源系统的性能。
通过降低技术门槛,它让更多创作者和研究者能够接触并利用先进的视频生成技术,一个全民AI视频创作的时代,或许真的不远了。