Improving Recursive Transformers with Mixture of LoRAs
小模型逆袭:MoL让1.2亿参数ModernALBERT超越全参数基线

在追求大模型极致性能的今天,如何让小模型兼具“轻量级”与“高智商”一直是业界的痛点。经典的ALBERT模型通过极其激进的参数共享(Parameter Sharing)策略大幅降低了显存占用,但代价是模型表达能力的显著下降——这就好比让一个学生用同一套解题思路去应对语文、数学和英语考试,效果自然大打折扣。
ArXiv URL:http://arxiv.org/abs/2512.12880v1
为了解决这一难题,来自牛津大学和苏黎世大学的研究团队提出了一种名为混合LoRA(Mixture of LoRAs, MoL)的全新机制,并基于此构建了ModernALBERT。令人惊讶的是,仅有1.2亿参数的ModernALBERT在多项基准测试中不仅击败了同量级的紧凑模型,甚至超越了参数量更大的全参数模型(如ModernBERT)。它是如何做到的?
递归Transformer的“紧箍咒”
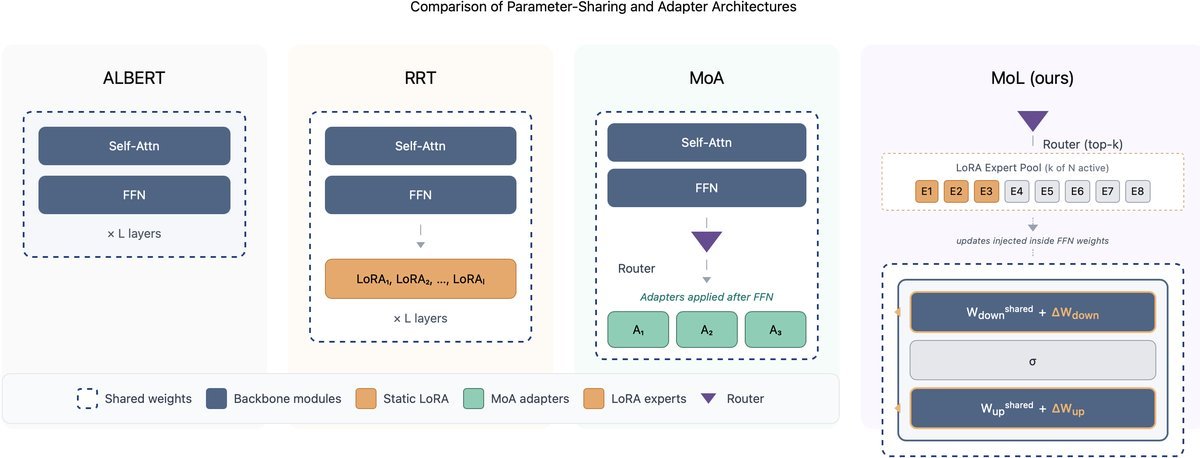
递归Transformer(Recursive Transformer),以ALBERT为代表,其核心思想是“循环利用”权重。比如,第1层和第12层使用完全相同的参数矩阵。这种做法极大地节省了参数量,但也带来了一个致命问题:层级表达能力坍缩(Layer-wise Expressivity Collapse)。
由于所有层共享同一套参数,模型无法针对不同深度的特征进行差异化处理。以往的补救措施通常是把层做得更宽(增加计算量)或者在层外挂载适配器(Adapter)。但这些方法要么牺牲了效率,要么未能触及核心——即共享权重本身的灵活性。
核心创新:混合LoRA(MoL)
本文提出的混合LoRA(MoL)是一种轻量级的条件计算(Conditional Computation)机制。不同于以往在FFN(前馈神经网络)之后添加适配器的做法,MoL选择直接深入“敌后”,将LoRA专家嵌入到共享的FFN内部。
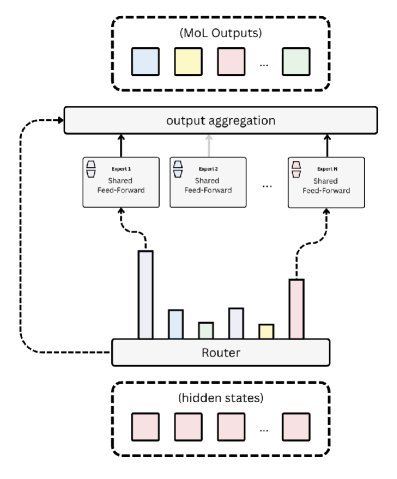
MoL的工作原理可以概括为以下几点:
-
内嵌式专家:在共享的FFN权重空间内,插入多个低秩适应(Low-Rank Adaptation, LoRA)专家。
-
Token级动态路由:对于每一个输入的Token,模型会通过一个路由网络(Router)动态选择激活一小部分LoRA专家(例如Top-2)。
-
权重空间调制:这不仅仅是输出值的相加,而是对共享权重的直接调制。公式上,标准FFN的权重 $W$ 被修改为:
\[W^{\prime}=W+\sum p_i(h) \cdot \frac{\alpha}{r}B_i A_i\]其中 $p_i(h)$ 是路由概率,$B_i A_i$ 是第 $i$ 个LoRA专家的低秩矩阵。
这种设计的精妙之处在于:虽然主干参数(Backbone)是共享的,但通过MoL的动态调制,每一层、每一个Token所“看到”的实际权重都是不同的。 这成功恢复了因参数共享而丢失的层级多样性。
ModernALBERT:全方位的现代化改造
除了MoL,研究团队还构建了一个现代化的架构——ModernALBERT。它不仅仅是加了MoL的ALBERT,还集成了当今大模型领域的最佳实践:
-
架构升级:引入了旋转位置编码(RoPE)、GeGLU激活函数以及FlashAttention,确保了训练和推理的高效性。
-
蒸馏初始化:为了解决从头预训练数据效率低的问题,ModernALBERT利用了全参数模型(ModernBERT)进行知识蒸馏和参数初始化。这使得它在仅使用300亿Token进行预训练的情况下,就能达到极高的性能水平。
实验结果:小身材,大能量
实验数据表明,ModernALBERT在紧凑型模型中确立了新的SOTA(State-of-the-Art)。
-
GLUE基准测试:ModernALBERT-large(120M参数)取得了 88.72 的平均分,不仅超过了NomicBERT和MosaicBERT等紧凑模型,更是直接击败了参数量更大的全参数基线模型 ModernBERT-base(149M参数,88.45分)。
-
问答与检索:在SQuAD-v2和BEIR基准测试中,ModernALBERT同样表现出色,证明了其在语义理解和信息检索任务上的强大泛化能力。
特别值得一提的是,在消融实验中,MoL的表现始终优于传统的混合适配器(Mixture-of-Adapters, MoA),证明了在权重空间内部进行调制比在输出端进行修补更为有效。
推理加速:专家合并技术
虽然MoE架构提升了性能,但动态路由通常会增加推理延迟。为了解决这个问题,本文提出了专家合并(Expert Merging)策略。
在推理阶段,可以通过加权平均的方式将所有LoRA专家合并为一个静态的适配器。
\[w_{merged} = \frac{1}{E} \sum_{i=1}^{E} w_i\]或者使用基于路由历史的指数加权平均。实验发现,简单的均匀平均(Uniform Averaging)就能保留绝大部分精度。这意味着,在部署时,ModernALBERT可以退化为一个没有任何动态路由开销的普通模型,享受极致的推理速度(ModernALBERT-tiny的延迟仅为9.46ms)。
总结
ModernALBERT通过引入混合LoRA(MoL),成功解决了递归Transformer中参数共享导致的表达能力瓶颈。它证明了:通过精细的条件计算和现代化的架构设计,我们完全可以用更少的参数、更低的显存占用,换取超越全参数大模型的性能。这对于边缘设备部署和资源受限场景下的AI应用,无疑是一个巨大的利好消息。