告别思维混乱:自重写技术让LLM推理长度锐减46%,质量反而更高

大模型在解决复杂问题时,其推理过程常常显得冗长、混乱,甚至充满无效思考。你是否也曾被它绕来绕去的“思维过程”搞得头大?这不仅消耗了大量计算资源,也降低了我们对模型决策的信任度。
ArXiv URL:http://arxiv.org/abs/2511.16331v1
最近,来自字节跳动、北理和浙大的研究者提出了一种名为自我重写(Self-Rewriting)的全新框架。它通过让大模型自己“批改”和“重写”自己的推理过程,实现了惊人的效果:在推理长度大幅缩短46%的同时,准确率反而提升了0.6%,推理质量评分更是飙升7.2分!
问题的核心:只看结果的“粗放式”训练
当前,大模型的推理能力主要通过强化学习(RL)来提升。这种方法通常只关注最终答案是否正确,给予一个简单的“对”或“错”的奖励。
这种“唯结果论”的训练方式,忽略了对推理过程本身的精细打磨。
这导致模型在思考时常常出现四大“思维病”:
-
过度思考(Over-thinking):在无关紧要的细节上反复纠缠。
-
思考不足(Under-thinking):跳过关键步骤,推理不充分。
-
重复思考(Redundant-thinking):反复陈述同样的想法,没有新进展。
-
无序思考(Disordered-thinking):思维线索混乱,东一榔头西一棒子。

图1:大模型推理中常见的四种思维缺陷,而自我重写能显著改善这些问题。
这些问题不仅让模型的“内心戏”变得难以理解,还浪费了宝贵的计算资源,甚至可能导致最终结果出错。
解决方案:让模型学会“自我重写”
如何让模型学会更“聪明”地思考呢?该研究的思路十分巧妙:让模型自己教自己。
研究者们提出了自我重写(Self-Rewriting)框架。其核心思想是,让模型在生成初步推理后,扮演一个“编辑”的角色,根据一个通用的高质量指令(如“请优化这段思考,使其更有条理、更连贯、更准确”)来重写自己的推理文本。
为了确保训练的稳定性和高效性,研究者设计了选择性重写(Selective Rewriting)策略。
具体来说,只有当模型对一个问题的所有初步回答都正确时,才会触发“重写”机制。模型会将自己重写后的、更精炼的推理版本视为更优的答案,并在后续的强化学习中模仿这种高质量的思考方式。
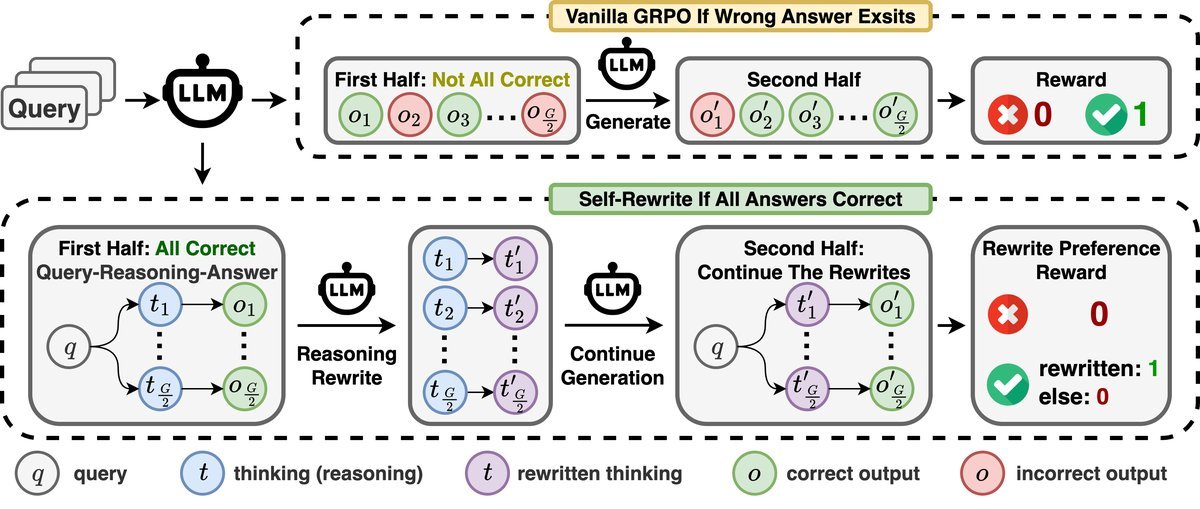
图2:自我重写框架。仅当所有初步推理都正确时,模型才会进行重写,并为重写后的版本赋予更高奖励。
如果初步回答中存在错误,则沿用传统的强化学习方式,奖励正确的答案。这种设计既保留了原有算法的优点,又引入了提升推理质量的“自我监督”信号。
更棒的是,通过精巧的实现,这套自我重写机制带来的额外计算开销仅有约10%,完全可以接受。
性能与效率:更短的推理,更高的准确率
实验结果令人振奋。研究者在Qwen3系列模型上进行了广泛测试,并与多种现有的推理优化方法进行了对比。
结果显示,自我重写方法在准确率-长度权衡上取得了最佳表现。
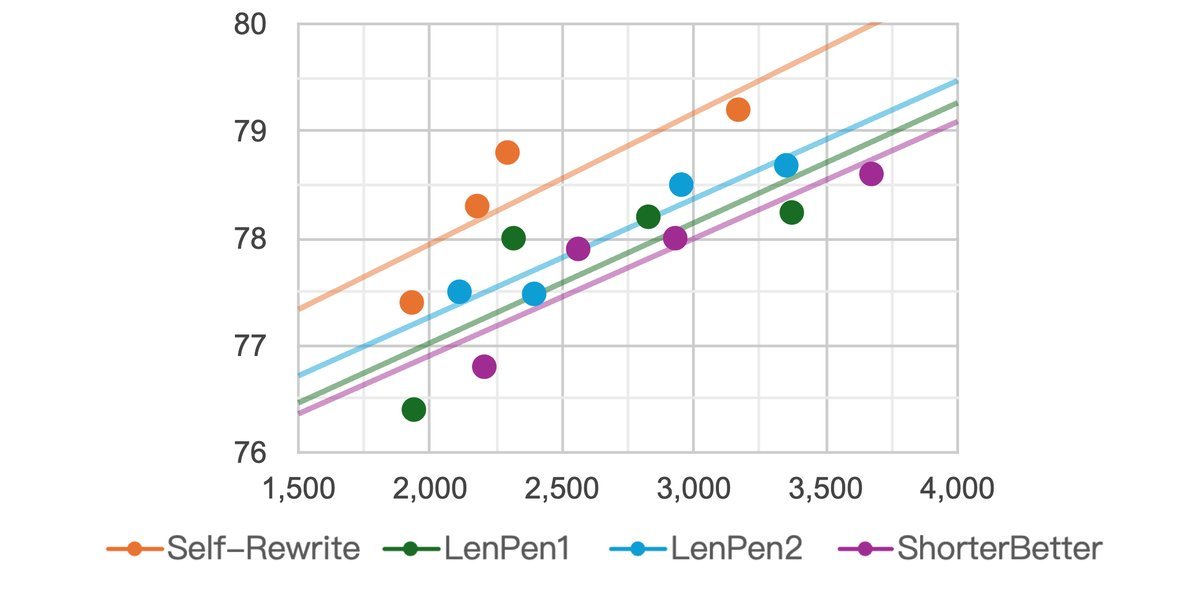
图3:在不同推理长度下,自我重写(Self-Rewriting,红色)始终保持着最高的准确率。
如图所示,相较于其他只是简单惩罚长度的方法,自我重写能够在大幅压缩推理文本长度的同时,保持甚至提升在数学、科学、逻辑等多种复杂任务上的准确率。
此外,通过强大的LLM作为裁判进行打分,自我重写后的推理文本在内部质量上获得了显著更高的分数(平均+7.2分),证明其有效缓解了前文提到的四种“思维病”。
深入剖析:为何“自我重写”更胜一筹?
自我重写为何比传统的“长度惩罚”等方法更有效?研究者通过分析模型偏好的数据揭示了答案。
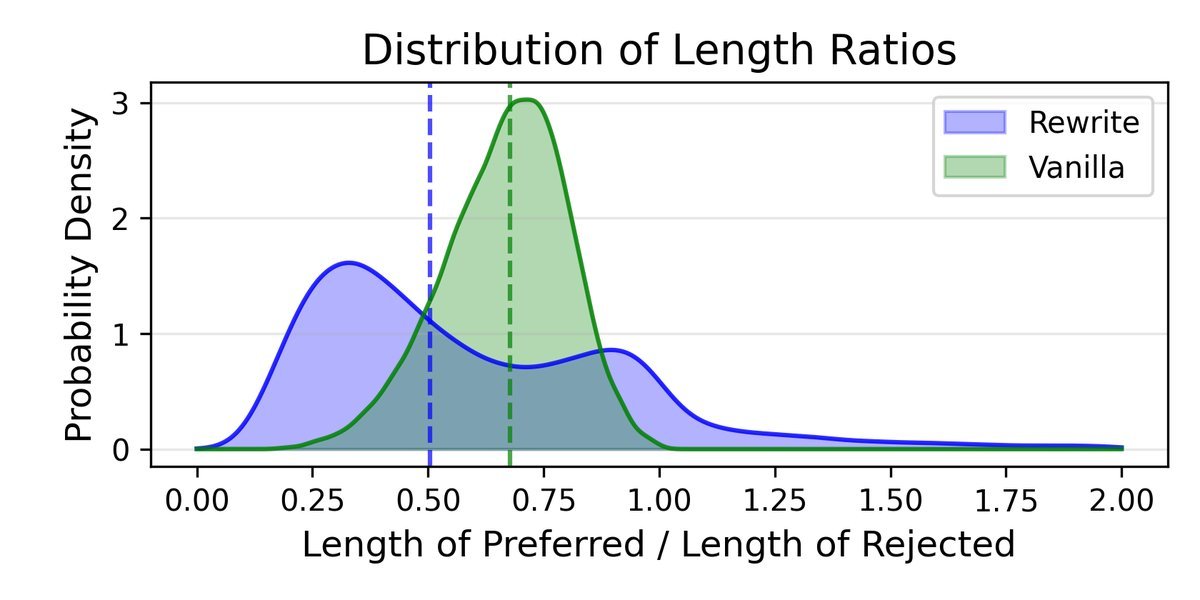
图4:自我重写(左)产生的长度比例分布更多样,表明其能根据问题动态调整压缩程度。
上图显示,传统的长度偏好方法(右)倾向于统一地将文本缩短到一个固定的比例(中位数约0.7)。
而自我重写(左)则表现出极大的灵活性。它有时会进行大刀阔斧的删减(长度比小于0.5),有时则进行微调。甚至在约10%的情况下,模型认为重写后的版本需要比原始版本更长才能把问题讲清楚!
这表明,自我重写并非盲目追求“短”,而是真正理解了推理的本质,学会了根据问题的复杂性动态地调整思考的详略程度。
结语
这项研究为我们打开了一扇新的大门。它表明,与其设计复杂的奖励函数来“告诉”模型如何思考,不如赋予模型“自我反思”和“自我修正”的能力。
自我重写框架以其简洁的设计和出色的效果,证明了让模型从自己的高质量输出中学习是一种极具潜力的优化路径。未来,我们或许能看到更多高效、清晰、且值得信赖的AI思考者出现。