AI算力新范式:斯坦福提出“每瓦特智能”,本地模型能效两年提升5.3倍!
大模型推理需求正以前所未有的速度暴增,云端数据中心压力山大。我们早已习惯将复杂的AI任务交由云端的超级计算机处理。
论文标题:Intelligence per Watt: Measuring Intelligence Efficiency of Local AI ArXiv URL:http://arxiv.org/abs/2511.07885v1
但如果你的笔记本电脑就能高效处理大部分AI请求,情况会怎样?
来自斯坦福大学和Together AI的一项最新研究,为我们描绘了这样一幅蓝图。他们不仅证明了本地AI的可行性,更提出了一个全新的衡量标准——每瓦特智能(Intelligence per Watt, IPW),来量化这一趋势。
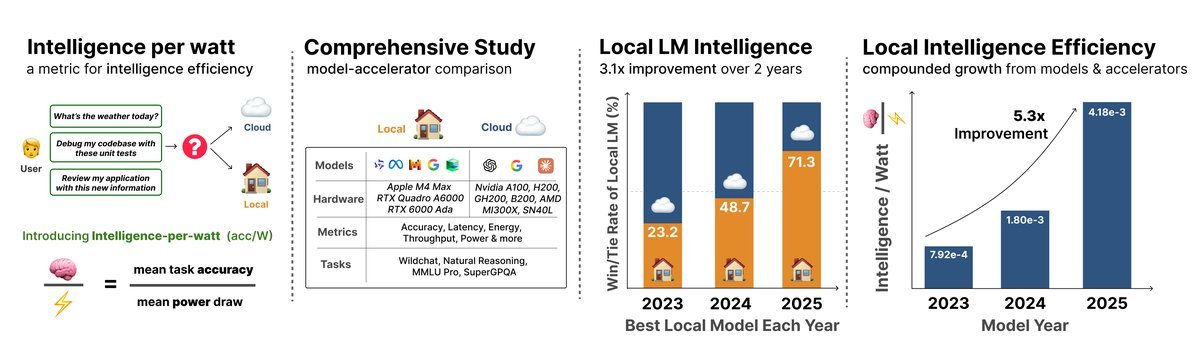 图1:研究概览:每瓦特智能(IPW)
图1:研究概览:每瓦特智能(IPW)
IPW:衡量AI能效的新标尺
过去,我们评估一个模型好坏,往往只看它的准确率或在排行榜上的得分。但这忽略了一个关键因素:成本,尤其是能耗成本。
IPW这个指标,就是要将“智能”和“能耗”统一起来。
它的核心思想非常直观:用模型的任务准确率除以它消耗的功率。
\[\text{IPW} = \frac{\text{任务准确率}}{\text{单位功率}}\]这就像汽车的“每加仑行驶里程数”一样,IPW衡量的是“每瓦特电力能换来多少智能”。这个指标让我们能跨越模型和硬件的差异,公平地比较谁的“脑力”输出效率更高。
本地AI的惊人潜力:并非“玩具”
研究团队通过对超过20个前沿小模型、8种硬件加速器和100万条真实世界查询的全面测试,得出了第一个惊人结论。
截至2025年,在单轮聊天和推理任务中,合适的本地小模型已经能成功处理高达88.7%的查询请求!
这意味着,近九成的日常AI查询,理论上都可以在你的个人设备上完成,无需再发往云端。当然,不同领域的表现有所差异:在创意写作等任务上超过90%,但在更专业的工程领域则降至68%左右。
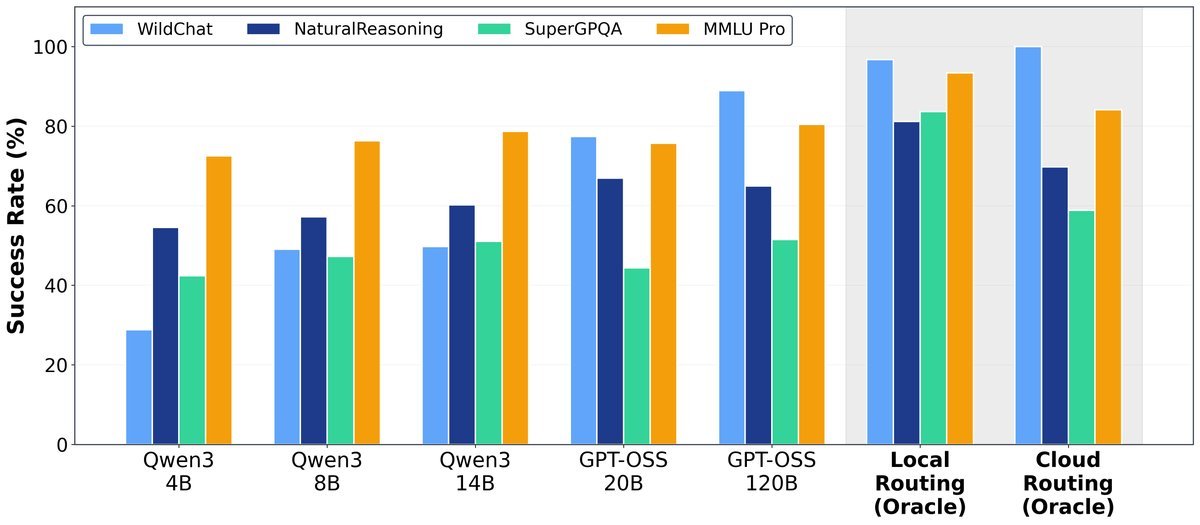 图2:本地模型在多个基准测试中媲美云端模型
图2:本地模型在多个基准测试中媲美云端模型
如图所示,“本地路由”(为每个查询选择最优的本地模型)的表现在多个基准上甚至超越了“云端路由”(选择最优的云端大模型)。
两年5.3倍:IPW的飞速演进
更令人振奋的是本地AI的进化速度。
研究显示,从2023年到2025年,本地AI的每瓦特智能(IPW)整整提升了5.3倍!
这一巨大的飞跃由两股力量共同推动:
- 模型算法的进步:贡献了3.1倍的增益。更优秀的模型架构(如MoE)、预训练和对齐技术,让小模型越来越“聪明”。
- 硬件加速器的发展:贡献了1.7倍的增益。从苹果的M系列芯片到英伟达和AMD的新一代GPU,更高的算力和能效比为本地AI提供了坚实的物质基础。
伴随效率提升的是覆盖率的增长。2023年最好的本地模型只能处理23.2%的查询,而到2025年,这一数字已飙升至71.3%。
混合即未来:节省高达80%的资源
这项研究并非要用本地AI完全取代云端。相反,它揭示了一个更高效的未来:本地-云端混合系统。
想象一个智能“流量调度员”:简单的任务直接在你的设备上解决,只有最复杂的任务才被发送到云端。
研究团队通过模拟证明,即使是一个只有80%准确率的“调度员”,也能带来惊人的资源节省:
- 能耗降低 64.3%
- 计算资源减少 61.8%
- 成本降低 59.0%
而这一切的实现,几乎不牺牲任何最终的答案质量,因为无法处理的请求最终还是会由最强的云端模型来“兜底”。
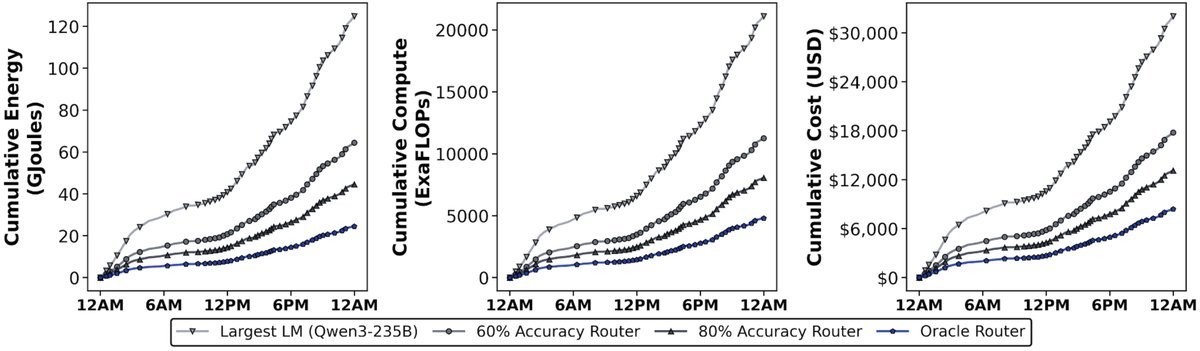 图3:模型路由带来的能源、计算和成本节省
图3:模型路由带来的能源、计算和成本节省
结论
这项研究清晰地告诉我们,本地AI不再是遥远的未来,而是正在发生的现实。
随着模型和硬件的持续迭代,将有越来越多的AI任务从遥远的云端回归到我们触手可及的个人设备上。而“每瓦特智能”(IPW)将成为衡量这场静悄悄革命进程的关键标尺。
研究团队也已将他们使用的评测工具开源,让所有人都能参与到这场通往更高效、更普及的AI时代的伟大进程中。