Kascade: A Practical Sparse Attention Method for Long-Context LLM Inference
微软Kascade:无需训练,H100上长文本推理提速4.1倍!

在当今的大模型应用中,长上下文(Long-Context)能力已成为“兵家必争之地”。无论是RAG(检索增强生成)、代码助手,还是复杂的Agent推理,都依赖于模型处理海量Token的能力。然而,随着上下文长度的增加,推理延迟和显存占用呈指数级增长,尤其是Attention机制带来的 $O(n^2)$ 复杂度,成为了制约长文本落地的最大瓶颈。
ArXiv URL:http://arxiv.org/abs/2512.16391v1
为了解决这一难题,来自微软研究院(Microsoft Research India)的团队提出了一种名为 Kascade 的全新稀疏注意力方法。它无需对模型进行任何重新训练,就能在H100 GPU上实现 4.1倍的Decode加速 和 2.2倍的Prefill加速,同时在LongBench和AIME-24等高难度基准测试中,精度几乎无损。
核心洞察:注意力机制的“二八定律”与“近邻效应”
Kascade的设计灵感源于两个简单却深刻的观察,这两个观察揭示了注意力机制内部的冗余性:
-
注意力的本质是稀疏的:经过 $softmax$ 操作后,注意力分数呈现出极端的分布。实验显示,仅约10%的Token就贡献了超过95%的注意力权重。这意味着,如果我们能通过某种“先知(Oracle)”提前知道哪些是 Top-$k$ 的关键Token,就可以忽略剩下的90%,从而大幅减少计算量。
-
层与层之间具有相似性:这是Kascade最关键的发现。如果第 $i$ 层认为某些Token很重要,那么第 $i+1$ 层通常也会关注这些相同的Token。高权重的Key在相邻层之间具有极高的稳定性。
基于这两点,Kascade提出了一种策略:不要在每一层都费力地计算全量注意力,而是“借用”邻居的作业。
Kascade 的工作原理:锚点与复用
Kascade 将模型的层分为两类:锚点层(Anchor Layers) 和 复用层(Reuse Layers)。
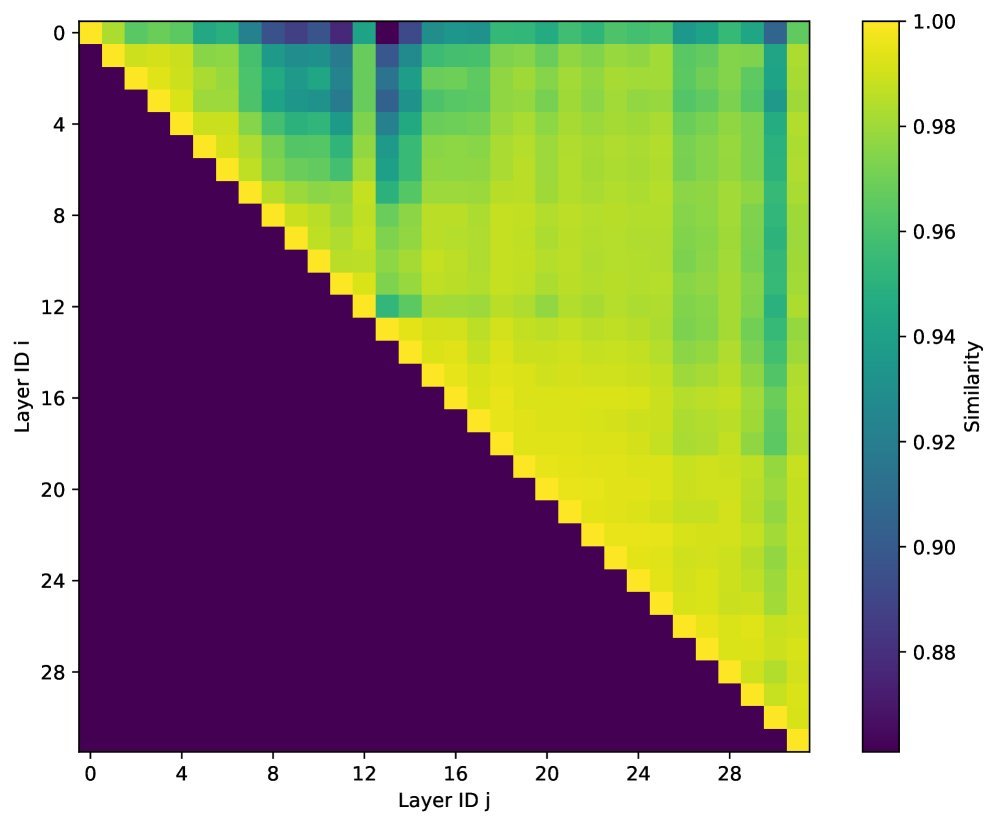
-
锚点层:负责“干重活”。在这些层中,Kascade 计算精确的 Top-$k$ 索引。
-
复用层:负责“搭便车”。这些层直接复用最近锚点层计算出的 Top-$k$ 索引,只对这些选定的Token进行计算。
这种方法看似简单,但实施起来有两个巨大的挑战:如何选择锚点层? 以及 如何处理多头注意力(Multi-Head Attention)的差异?
1. 自动化锚点选择(Automatic Anchor Selection)
以往的类似工作(如LessIsMore)通常依靠人工经验来设定哪些层作为锚点,这导致方法很难迁移到新模型上。Kascade 创新性地引入了一个 动态规划(Dynamic Programming) 算法。
该算法会在一个小的开发集上运行,自动寻找一种分层方案,使得锚点层与复用层之间的“跨层相似度”最大化。这使得 Kascade 成为一个真正的“即插即用”方案,无论是 Llama-3 还是 Qwen-3,都能自动找到最优配置。
2. 头部重映射(Head Remapping)
这是 Kascade 精度高的秘诀。在 Transformer 中,不同的注意力头(Head)关注的信息截然不同。如果简单地把锚点层第1个头的 Top-$k$ 索引直接给复用层的第1个头,效果往往不佳。
Kascade 发现,锚点层的第 $i$ 个头,可能与复用层的第 $j$ 个头更相似。因此,它引入了 头部重映射 机制,为复用层的每一个头,在锚点层中找到最相似的“导师”,从而确保复用的索引是真正相关的。
性能与精度:鱼与熊掌兼得
该研究在 H100 GPU 上,使用 FlashAttention-3 作为基线进行了严格的测试。
速度方面:
得益于基于 TileLang 实现的高效内核,Kascade 在长文本推理中表现出了惊人的加速比。
-
Decode 阶段:最高实现 4.1倍 加速。
-
Prefill 阶段:最高实现 2.2倍 加速。
精度方面:
在 LongBench 和 AIME-24(一个专注于长文本推理的基准)上,Kascade 展现了卓越的稳定性。
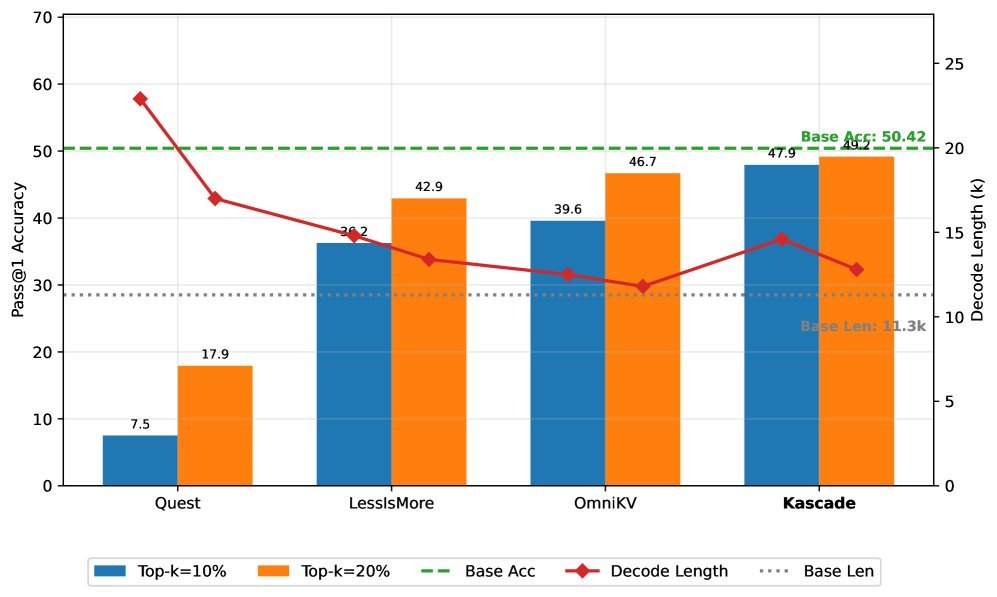
如上表所示,在 AIME-24 测试中,相比于 Quest、OmniKV 等其他稀疏注意力方法,Kascade 在保持相同稀疏度(10% Top-$k$)的情况下,准确率大幅领先(提升了8-10个百分点),几乎与全量注意力(Dense)持平。
总结
Kascade 的出现证明了,长文本推理并不一定需要昂贵的计算代价。通过巧妙利用注意力机制内在的稀疏性和层间相似性,并结合动态规划与底层算子优化,Kascade 为大模型的长文本推理提供了一个既快又准的实用方案。对于那些正在为显存焦虑和推理延迟头疼的开发者来说,Kascade 无疑是一个值得尝试的“降本增效”利器。