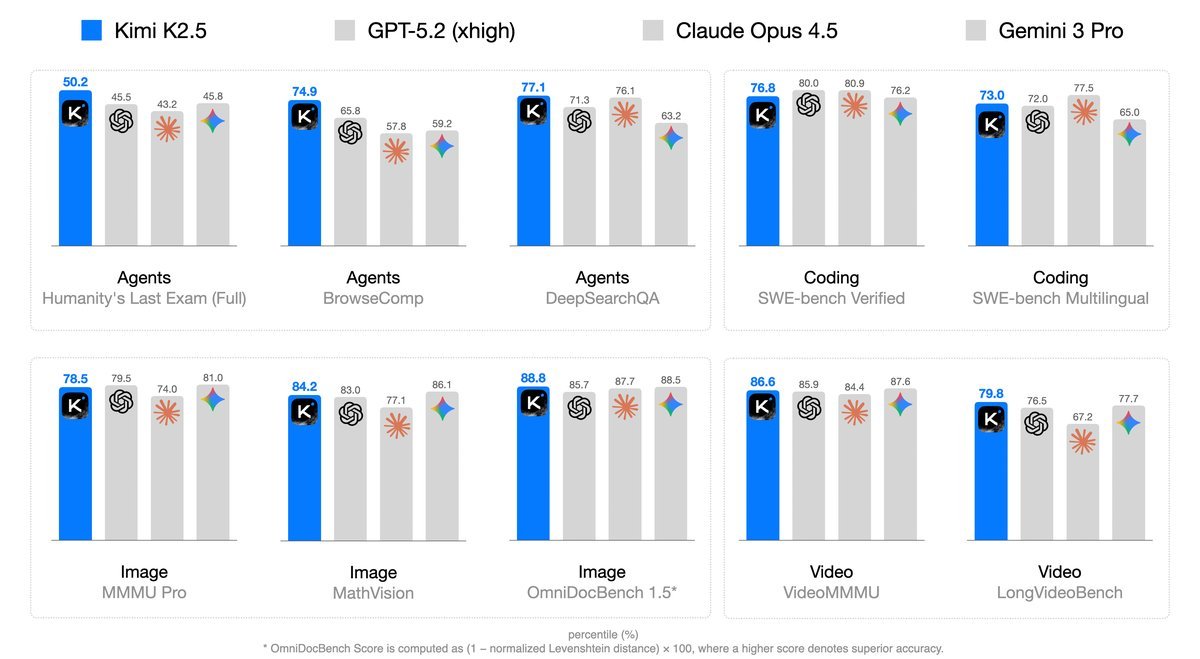
Kimi K2.5: Visual Agentic Intelligence
Kimi K2.5重磅开源:多模态联合增强,Agent推理提速4.5倍

月之暗面(Moonshot AI)刚刚投下了一枚重磅炸弹:Kimi K2.5 正式开源。这不仅仅是一个简单的模型升级,而是一次向通用智能体(General Agentic Intelligence)迈进的重要探索。
ArXiv URL:http://arxiv.org/abs/2602.02276v1
Kimi K2.5 最大的亮点在于它打破了以往多模态模型“文本强、视觉弱”或者“视觉强、文本弱”的魔咒,通过文本与视觉的联合优化实现了双向增强。更令人兴奋的是,它引入了 Agent Swarm 框架,让智能体学会了“分身术”,将推理延迟大幅降低了 $4.5\times$。
本文将深入解读 Kimi K2.5 背后的核心技术,看看它是如何重新定义多模态智能体的。
视觉与文本:从“貌合神离”到“深度融合”
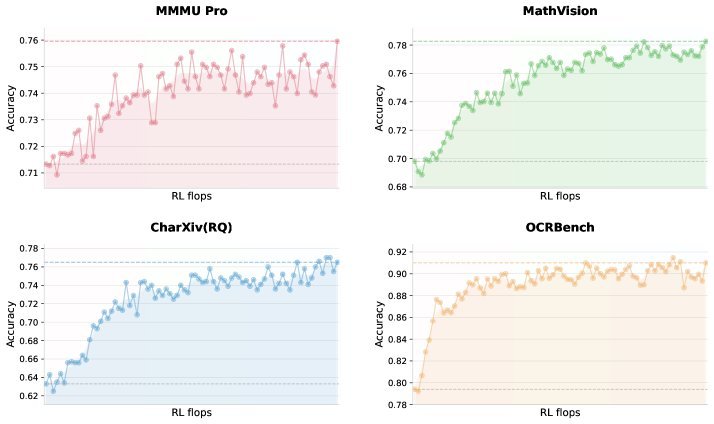
在以往的多模态模型训练中,视觉往往是作为“外挂”在后期加入的。但 Kimi K2.5 的研究团队发现了一个反直觉的现象:早期融合效果更好。
原生多模态预训练
该研究并未采用传统的后期视觉对齐策略,而是从预训练的一开始就引入视觉数据。实验表明,在固定的视觉-文本 Token 总预算下,早期融合(Early Fusion)且保持较低的视觉比例,反而能产生更好的多模态表征。
在架构上,Kimi K2.5 采用了 MoonViT-3D 视觉编码器。它利用了 NaViT 的打包策略,能够处理任意分辨率的图像。对于视频理解,模型引入了轻量级的 3D ViT 压缩机制:将连续帧分组并通过共享编码器处理,随后在 Patch 级别进行时间平均。这种设计使得 Kimi K2.5 在保持相同上下文窗口的情况下,能够处理长达 $4\times$ 的视频内容。
零视觉 SFT:文本训练竟能激活视觉?
这是一个非常有趣的发现:研究人员在监督微调(SFT)阶段引入了零视觉 SFT(Zero-Vision SFT)。
通常认为,要让模型学会看图,必须喂给它大量的图文对数据。但 Kimi K2.5 的实验显示,仅使用纯文本 SFT 就足以激活模型的视觉推理和工具使用能力。相反,如果在这一阶段加入人工设计的视觉轨迹,反而会损害模型的泛化能力。这说明,得益于联合预训练,模型内部已经建立了强大的视文对齐。
视觉 RL 反哺文本能力
在强化学习(RL)阶段,Kimi K2.5 采用了联合文本-视觉 RL。结果令人惊讶:视觉 RL 不仅提升了视觉任务的表现,还反过来增强了纯文本任务的能力(例如在 MMLU-Pro 和 GPQA-Diamond 基准上的提升)。
这种“文本引导视觉,视觉精炼文本”的双向增强,证明了跨模态对齐的深度潜力。
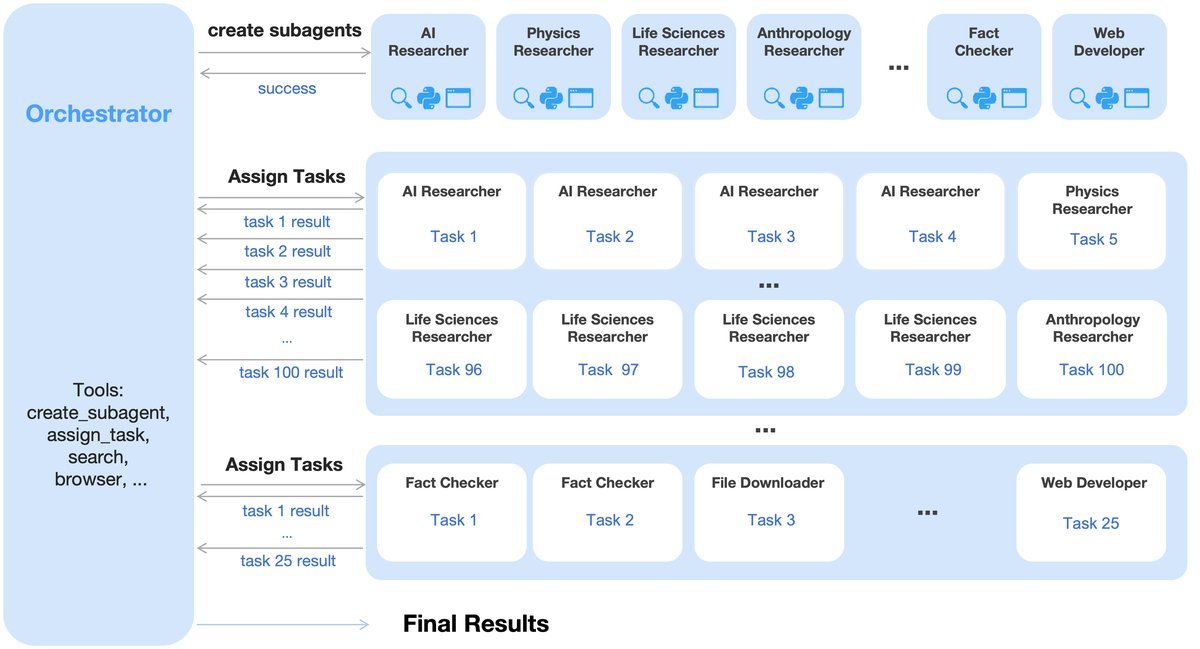
Agent Swarm:拒绝串行,并行智能体蜂群
目前的智能体系统大多是“串行”的:一步推理,一步执行。面对复杂任务时,这种线性模式会导致推理时间过长,甚至耗尽上下文窗口。为了解决这个问题,Kimi K2.5 引入了 Agent Swarm——一种并行的智能体编排框架。
并行智能体强化学习(PARL)
Agent Swarm 包含一个可训练的编排器(Orchestrator)和多个冻结的子智能体(Sub-agents)。
该框架采用了一种新颖的并行智能体强化学习(Parallel-Agent Reinforcement Learning, PARL)范式。为了避免端到端联合优化的不稳定性,研究团队选择冻结子智能体,只对编排器进行 RL 更新。编排器学会了将复杂任务动态分解为异构的子问题,并指派给专门的子智能体并行执行。
以“关键步骤”为核心的资源约束
为了衡量并行效率,该研究定义了关键步骤(Critical Steps)这一概念,类比于计算图中的“关键路径”。
\[\text{CriticalSteps}=\sum_{t=1}^{T}\left(S_{\mathrm{main}}^{(t)}+\max_{i}S_{\mathrm{sub},i}^{(t)}\right)\]通过在训练中优化这一指标,模型被激励去最大化并行度,从而减少端到端的延迟。实验数据显示,在广泛搜索场景下,Agent Swarm 将推理延迟降低了 $4.5\times$,同时在项目级 F1 分数上从 72.8% 提升到了 79.0%。
强化学习的精细化打磨
除了上述两大核心架构创新,Kimi K2.5 在 RL 算法上也做了诸多微调。
-
生成式奖励模型(GRMs):不再局限于简单的二元对错,而是使用符合 Kimi 价值观(如有用性、安全性)的细粒度评估器。
-
Token 效率优化:为了防止模型在推理时为了“思考”而输出过长的废话,研究团队引入了动态预算控制。通过 Toggle 算法,模型学会了在不牺牲性能的前提下,将输出长度减少 25%~30%,去除了思维链中的冗余模式。
总结
Kimi K2.5 展示了一个统一的架构:它不仅融合了视觉与语言,还打通了思考(Thinking)与行动(Acting)、单体与群体(Swarm)。
通过开源 Kimi K2.5 的 Post-trained Checkpoint,Moonshot AI 为社区提供了一个强大的多模态智能体基座。无论是对于研究跨模态联合训练的学者,还是致力于构建低延迟、高并发 Agent 应用的开发者,Kimi K2.5 都提供了一个极具价值的参考范本。