KimiLinear揭秘:首次全面超越全注意力,1M上下文解码提速6倍!
在追求更强AI智能体的道路上,长文本处理能力已成为一道绕不开的“性能墙”。传统的Transformer架构因其$O(N^2)$的注意力计算复杂度和线性增长的KV缓存,在处理超长序列时变得力不从心,效率和成本成为巨大瓶颈。
论文标题:Kimi Linear: An Expressive, Efficient Attention Architecture ArXiv URL:http://arxiv.org/abs/2510.26692v2
人们曾寄望于线性注意力来解决这一难题,但它们往往以牺牲模型性能为代价,尤其在短文本任务上表现不佳。这似乎是一个无法两全的困境:性能和效率,你只能选一个。
现在,Kimi团队给出了新的答案:Kimi Linear。
这是一种新型的混合线性注意力架构,它在严格的公平对比下,首次在短文本、长文本乃至强化学习(RL)等所有场景中,全面超越了传统的全注意力(Full Attention)模型。
它不仅在100万Token的超长上下文解码中实现了高达6倍的吞吐量提升,还将KV缓存的使用量降低了75%。
Kimi Delta Attention (KDA):更精细的记忆控制器
Kimi Linear架构的核心,是一种名为Kimi Delta Attention(KDA)的全新线性注意力模块。要理解KDA的巧妙之处,我们可以把它想象成一个升级版的“记忆管理系统”。
传统的线性注意力,就像一个记忆力有限的大脑,为了记住新东西,不得不粗暴地遗忘旧信息,导致关键信息丢失。
一些改进方法,如Gated DeltaNet(GDN),引入了“遗忘门”,允许模型按“主题”(head-wise)来决定遗忘哪些内容。这就像给记忆系统装了几个粗糙的开关,可以决定忘掉“历史”这个大类,但保留“物理”。这比胡乱遗忘要好,但仍然不够精细。
而KDA则实现了革命性的升级:它引入了更细粒度的门控机制(fine-grained gating)。

这个机制就像为大脑的每个“记忆神经元”(channel-wise)都安装了独立的开关。模型不再是按“主题”来遗忘,而是可以精确到某个“知识点”。比如,在处理历史信息时,可以选择性地忘记某个不重要的年份,同时牢牢记住关键的历史事件脉络。
这种对记忆状态的“像素级”精准调控,让KDA在有限的RNN状态容量下,能更高效地利用记忆,极大地增强了模型的表达能力。
为效率而生:定制化的并行算法
精细的控制虽好,但会不会拖慢速度?Kimi团队通过一个定制化的分块并行算法(chunkwise algorithm)解决了这个问题。
KDA的状态转移矩阵采用了一种特殊的对角加低秩(Diagonal-Plus-Low-Rank, DPLR)结构。团队为这种结构量身打造了一套计算方法,能够在硬件(如GPU Tensor Cores)上高效并行。
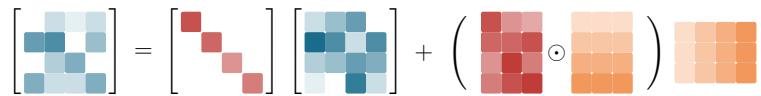
该算法巧妙地将复杂的递归计算转换为分块并行处理,不仅规避了其他细粒度门控方法中常见的数值精度问题,还大幅减少了计算量。相比通用的DPLR实现,KDA的算子效率提升了近100%。
这意味着KDA在拥有强大表达能力的同时,也保持了极高的硬件效率。
Kimi Linear架构:线性与全局的黄金配比
Kimi Linear并非一个纯粹的线性注意力模型,而是一个精心设计的混合架构。它巧妙地将高效的KDA层和传统的全注意力层(论文中为MLA)以3:1的比例交错排列。
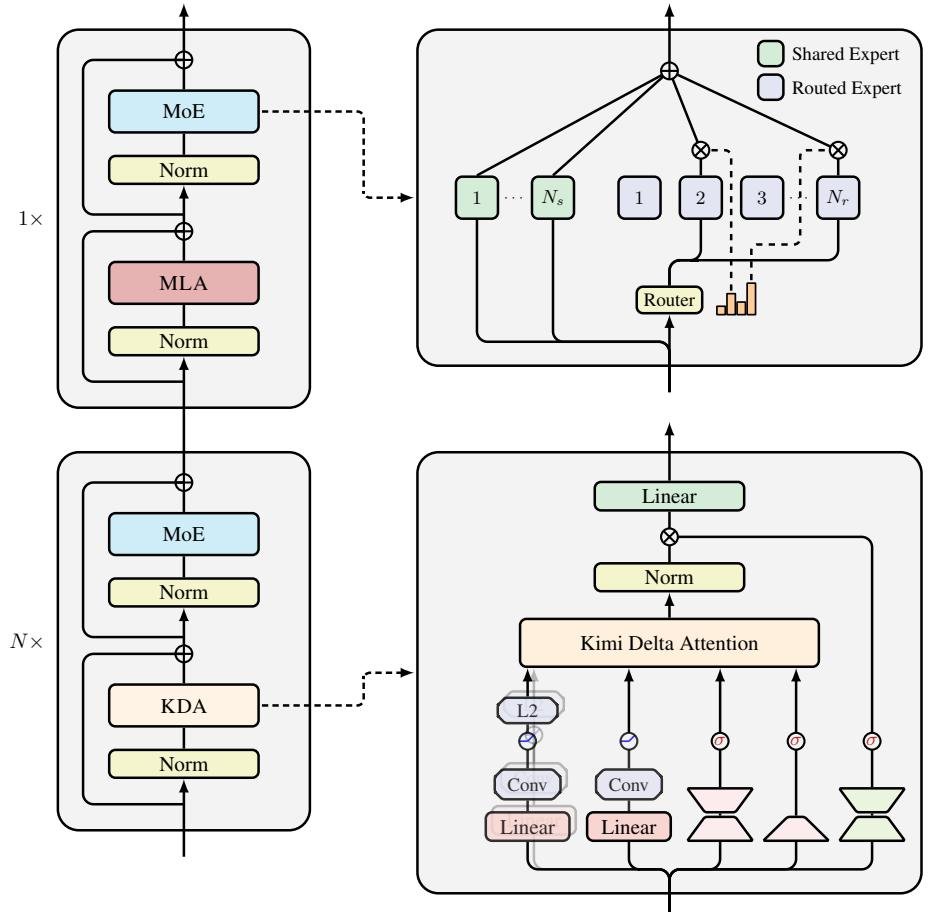
这种设计堪称神来之笔:
- 3个KDA层:作为主力,它们负责处理绝大部分的序列信息,保证了模型在长文本处理上的速度和低内存占用。
- 1个全注意力层:作为“全局信息枢纽”,周期性地出现,确保模型不会因为线性注意力的局部性而丢失全局上下文的关联,解决了纯线性模型常见的“远距离检索”难题。
这个 3:1 的比例,是经过实验验证的“黄金配比”,在性能和效率之间取得了最佳平衡。
碾压全注意力:惊人的实验结果
口说无凭,实验数据展示了Kimi Linear的真正实力。在与配置、参数和训练数据完全相同的全注意力基线模型(MLA)的“公平对决”中,Kimi Linear取得了压倒性优势。
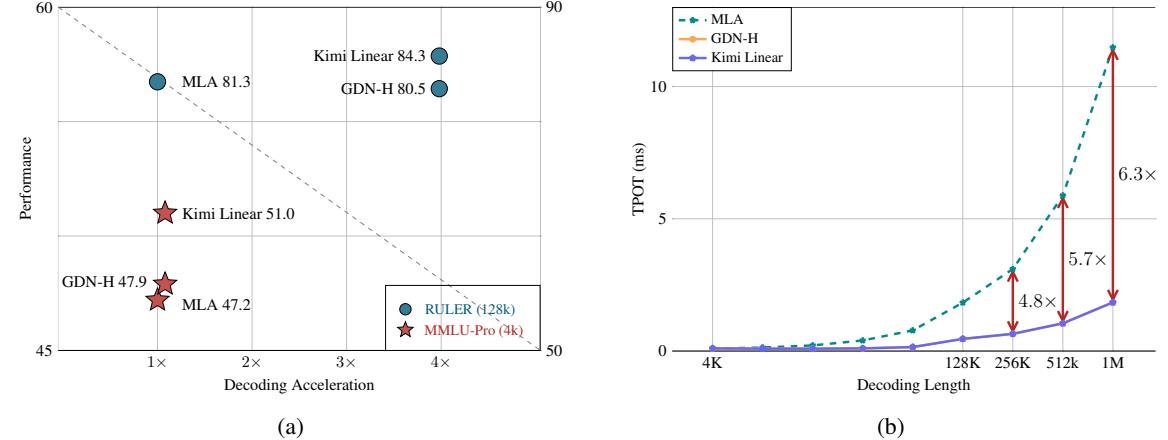 图注:Kimi Linear在性能和加速上实现了帕累托最优
图注:Kimi Linear在性能和加速上实现了帕累托最优
- 性能全面领先:无论是在短文本的通用知识评测(如MMLU-Pro),还是长文本的RULER基准测试,Kimi Linear的得分都显著高于全注意力模型。这证明它并非“偏科生”,而是一个全能选手。
- 效率大幅提升:在百万Token级别的解码任务中,得益于恒定的RNN状态大小,Kimi Linear的吞吐量是全注意力模型的6.3倍。这意味着生成相同数量的Token,它的速度要快得多。
- 显存显著节省:KV缓存占用降低高达75%,使得在同等硬件条件下可以支持更大的批处理大小(batch size),进一步提升了整体吞吐率。
 图注:在1M上下文长度下,Kimi Linear解码速度比全注意力快6倍
图注:在1M上下文长度下,Kimi Linear解码速度比全注意力快6倍
结论
Kimi Linear的出现,标志着大模型注意力机制的一次重要突破。它不仅解决了线性注意力长期以来“性能不如全注意力”的固有印象,更在多个维度上实现了超越。
这项研究证明,通过精巧的门控设计(KDA)、高效的硬件感知算法(定制化并行计算)和明智的混合架构(3:1比例),我们完全可以构建出既比全注意力更强、又比它更高效的模型。
Kimi Linear不再是一个实验室里的“玩具”,而是一个可以无缝替换现有全注意力架构的“即插即用”方案。为了推动社区发展,Kimi团队已经开源了KDA的核心算子、vLLM集成实现以及预训练和指令微调的模型权重,为下一代更高效、更强大的AI智能体铺平了道路。