Kling-Omni Technical Report
10步推理生成电影级视频:快手Kling-Omni全能架构揭秘

视频生成领域长期存在着一种“割裂感”:有的模型擅长文生视频,有的专精于视频编辑,而有的则需要借助外部工具才能理解复杂的视觉指令。这种“流水线式”的拼凑方案,不仅效率低下,更难以捕捉用户细腻的创作意图。
ArXiv URL:http://arxiv.org/abs/2512.16776v1
快手团队最新发布的 Kling-Omni 技术报告,正是为了终结这种割裂。作为一款端到端的全能生成框架,Kling-Omni 不仅打破了视频生成、编辑与推理之间的壁垒,更通过高效的蒸馏技术将推理步数压缩至惊人的 10 步。这不仅仅是一个内容创作工具,更是向着能够感知、推理并模拟物理世界的“多模态世界模拟器”迈出的关键一步。
统一架构:从“拼凑”到“融合”
现有的视频模型往往依赖静态的文本编码器,难以捕捉复杂的视觉细节;而视频编辑通常需要独立的适配器,导致系统臃肿。Kling-Omni 的核心突破在于提出了一种全新的交互范式——多模态视觉语言(Multimodal Visual Language, MVL)。
这种范式不再将文本、图像和视频视为分离的输入,而是将它们构建为一个统一的输入表示。
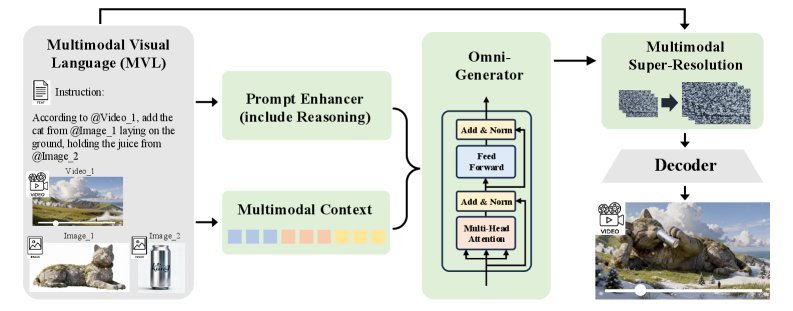
如上图所示,Kling-Omni 的架构主要由三个关键组件构成:
-
提示增强器(Prompt Enhancer, PE):这是一个基于 MLLM 的模块,负责“翻译”用户的意图。它能将模糊的用户指令与世界知识结合,转化为模型更易理解的精细化提示。
-
全能生成器(Omni-Generator):这是核心引擎。它在一个共享的嵌入空间中处理视觉和文本 Token,实现了深度的跨模态交互,确保了生成的视频既符合指令又具有视觉一致性。
-
多模态超分辨率(Multimodal Super-Resolution):用于进一步提升画质,通过条件化原始 MVL 信号来恢复高频细节。
训练策略:从理解到直觉
为了让模型具备“全能”的身手,研究团队设计了一套渐进式的多阶段训练策略。
在预训练阶段,模型通过大规模文本-视频对数据,建立了基础的指令遵循能力。随后进入监督微调(Supervised Fine-tuning, SFT)阶段,模型开始接触高度交错的图像、视频和文本混合数据,学习处理复杂的编辑任务和语义理解。
最值得关注的是强化学习(Reinforcement Learning, RL)阶段。为了让生成的视频符合人类审美,Kling-Omni 采用了直接偏好优化(Direct Preference Optimization, DPO)。
为何选择 DPO?相比于 DeepSeekMath 等使用的 GRPO 算法,DPO 避免了计算昂贵的轨迹采样,仅需一步扩散前向过程即可完成优化。通过构建“偏好对”(即人类认为更好 vs 更差的视频),模型学会了如何生成动作更自然、视觉更完整的视频。
极致优化:10步推理的秘密
视频生成模型通常面临巨大的算力挑战。Kling-Omni 在推理效率上通过“蒸馏”技术实现了质的飞跃。
研究人员开发了一种两阶段的蒸馏方法:
-
轨迹匹配蒸馏:让学生模型模仿教师模型的生成轨迹。
-
分布匹配蒸馏:进一步优化生成性能。
与常见的基于 SDE 的蒸馏方法(如 DMD 或 SiD)不同,Kling-Omni 采用了更适合视频任务的 ODE 采样蒸馏。这一套组合拳下来,将生成单个视频所需的函数评估次数(NFE)从原本的 150 次大幅压缩至 10 NFE。这意味着推理速度提升了 15 倍,且几乎没有牺牲画质。
此外,针对长序列视频生成的显存瓶颈,Kling-Omni 采用了混合并行推理策略(Ulysses 并行 + 张量并行),并设计了专门的 Cache 机制,实现了约 $2\times$ 的额外加速。
数据基石:构建多模态数据引擎
强大的模型离不开高质量的数据。Kling-Omni 构建了一个全面的数据系统,涵盖了从数据采集到处理的全流程。
特别是在数据合成方面,单纯依赖真实数据往往难以学习到精确的控制力。因此,团队利用内部的图像编辑和视频理解模型,构建了大量高质量的合成数据,用于训练模型的编辑和多图参考能力。

为了保证数据质量,还建立了一个三层过滤系统(如上图),分别从基础质量、时间稳定性和跨模态对齐三个维度对数据进行清洗,确保“喂”给模型的数据都是精品。
性能评估:超越 SOTA 的表现
Kling-Omni 的实际表现如何?研究团队构建了 OmniVideo-1.0 基准测试,包含 500 多个涵盖不同主体、场景和挑战的测试案例。
在与行业领先模型(如 Veo 3.1 和 Runway-Aleph)的对比中,Kling-Omni 展现出了显著优势。
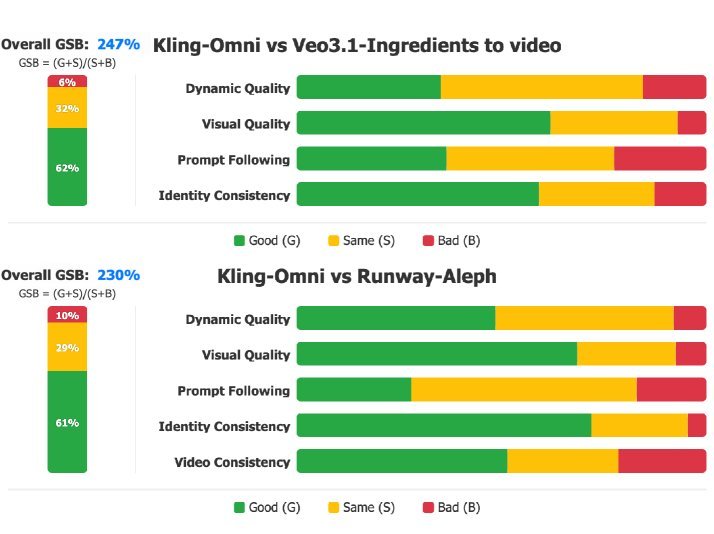
从上图的 GSB(Good-Same-Bad)评估结果可以看出:
-
在图像参考生成任务中,Kling-Omni 在多个维度上优于 Veo 3.1。
-
在视频编辑任务中,相比 Runway-Aleph,Kling-Omni 在保持原视频特征的同时,展现了更强的编辑能力。
结语
Kling-Omni 不仅仅是一个视频生成模型,它展示了一种将感知、推理和生成融为一体的可能性。通过统一的架构和高效的推理策略,它让“所想即所得”的视频创作变得更加触手可及。
更重要的是,它展现出的对物理世界的初步理解和推理能力,让我们看到了未来“多模态世界模拟器”的雏形。在这个模拟器中,AI 不再只是被动地生成像素,而是开始理解像素背后动态而复杂的世界逻辑。