Large language models and the entropy of English
挑战香农极限:LLM揭示10^4字符长程依赖与“涌现确定性”
早在1951年,信息论之父克劳德·香农(Claude Shannon)曾通过一个著名的“猜字游戏”来估算英语的熵:给定前 $N$ 个字母,人类受试者能多准确地猜出下一个字母?香农当时推测,随着上下文长度 $N$ 的增加,每个字符的条件熵会在 $N \approx 100$ 时趋于一个平稳的常数(Plateau)。
ArXiv URL:http://arxiv.org/abs/2512.24969v1
但如果这个“猜谜者”不是人类,而是阅读过海量文本的大语言模型(Large Language Models, LLMs)呢?如果上下文长度不是100,而是10,000甚至更多呢?
来自普林斯顿大学物理系的研究团队利用现代 LLM 作为工具,重新审视了这个问题。他们的发现令人惊讶:在长达 $10^4$ 个字符的尺度上,英语文本的熵仍在持续下降,丝毫没有“躺平”的迹象。这一发现不仅挑战了传统的语言统计物理模型,还揭示了一种迷人的“涌现确定性”现象。
超越人类的“猜谜者”
这项研究的核心思想非常直观:利用 LLM 强大的预测能力来衡量文本的信息密度。研究人员使用了 OLMo 2、Llama 3.2、Qwen3 以及自研的 DCLM 模型,让它们在给定前 $K$ 个 Token(对应 $N$ 个字符)的情况下预测下一个 Token。
模型输出的概率分布可以直接转化为码长(Code Length),即 $-\log P$,这正是条件熵的一个上界。
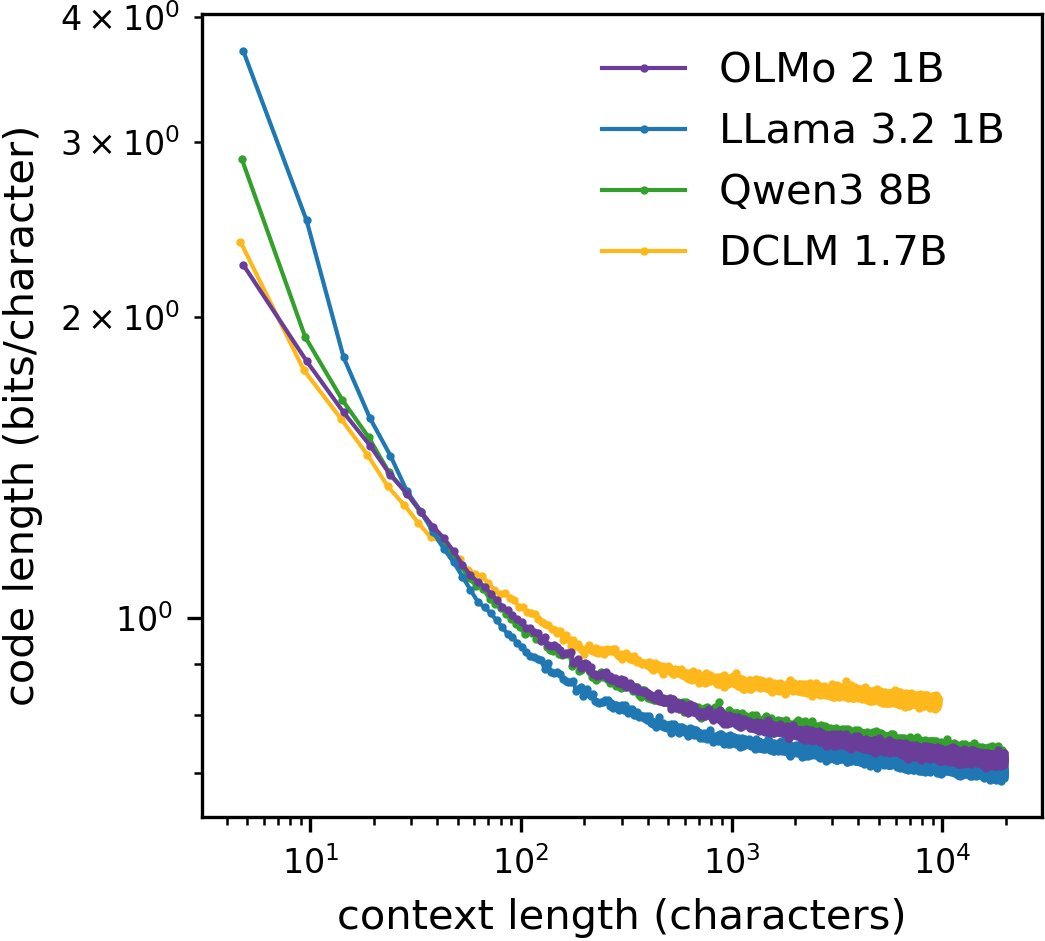
图1:不同模型在C4语料库上的码长随上下文长度的变化。可以看到,即使在 $N > 10^3$ 之后,曲线依然保持下降趋势,且不同模型间的一致性惊人。
从图1中我们可以看到一个关键现象:尽管不同模型在短上下文($N < 100$)时的表现有所差异(这可能与分词器和训练细节有关),但在长上下文区间($N > 10^3$),它们表现出了惊人的一致性。更重要的是,码长并没有像香农预测的那样在 $N=100$ 处进入平台期,而是随着上下文的增加持续下降,直到实验覆盖的 $N \sim 10^4$ 范围。
这意味着,相隔上万个字符的文本之间,依然存在着直接的依赖关系或“相互作用”。
文本中的“长程纠缠”
这种持续下降的熵暗示了什么?在统计物理学中,如果相关性函数随着距离衰减得足够慢(例如幂律衰减),系统就会表现出长程有序。
为了验证这一点,研究人员不依赖模型,直接计算了数据中字符间的互信息(Mutual Information)。结果显示,虽然短程相关性(语法、拼写)衰减很快,但在 C4 语料库中,字符间的互信息在极长距离上呈现出幂律衰减 $I(d) \propto d^{-\alpha}$,其中 $\alpha \approx 0.12$。
这种长程相关性说明,语言并不是简单的马尔可夫链,也不是仅由局部语法规则支配的系统。文章形象地指出,如果把文本看作一维自旋链,那么字符之间存在着跨越数千个位置的“有效相互作用”。
涌现的确定性:当预测变得“绝对自信”
随着阅读的文本越来越长,模型对下一个字符的预测发生了什么质的变化?研究发现,平均熵的下降并不仅仅是因为整体分布的平移,而是因为出现了一种结构性的变化。
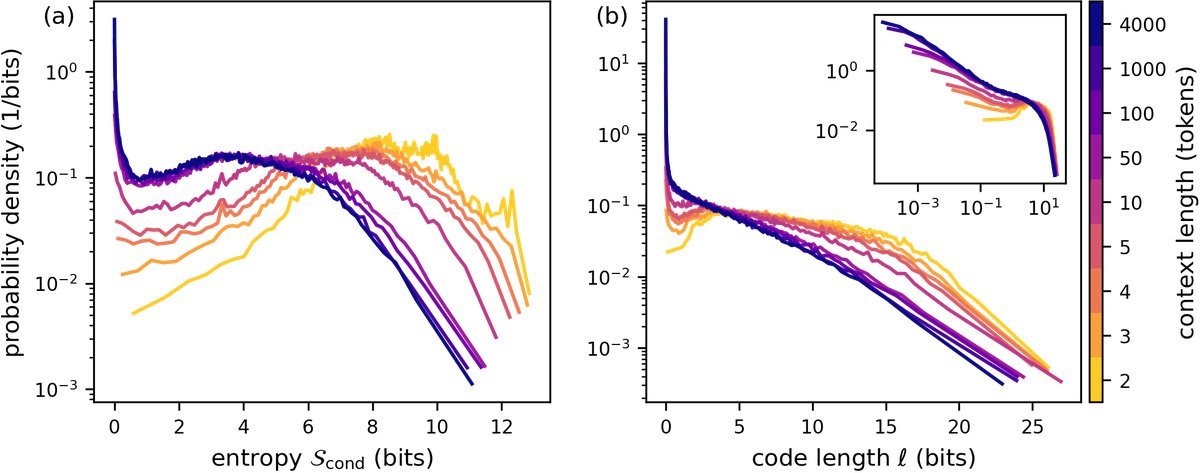
图3:条件熵(a)和码长(b)的分布随上下文长度 $K$ 的演变。注意在 $K$ 增大时,接近零熵(即完全确定)的峰值是如何“涌现”出来的。
如图3所示,随着上下文长度 $K$ 的增加,分布图中出现了一个显著的特征:在接近零熵的位置涌现出了一个尖峰。
这被称为“涌现确定性”(Emergent Certainty)。这意味着,当模型掌握了足够多的上下文信息(比如读完了半本书),对于某些位置的字符,它不再是“猜测”,而是几乎达到了“确信”的程度(熵趋近于0)。这种近乎完美的预测能力,是在短上下文中完全看不到的。
诗歌与散文的物理学差异
有趣的是,这种“熵值无限下降”的规律并非放之四海而皆准。研究人员对比了不同体裁的文本:
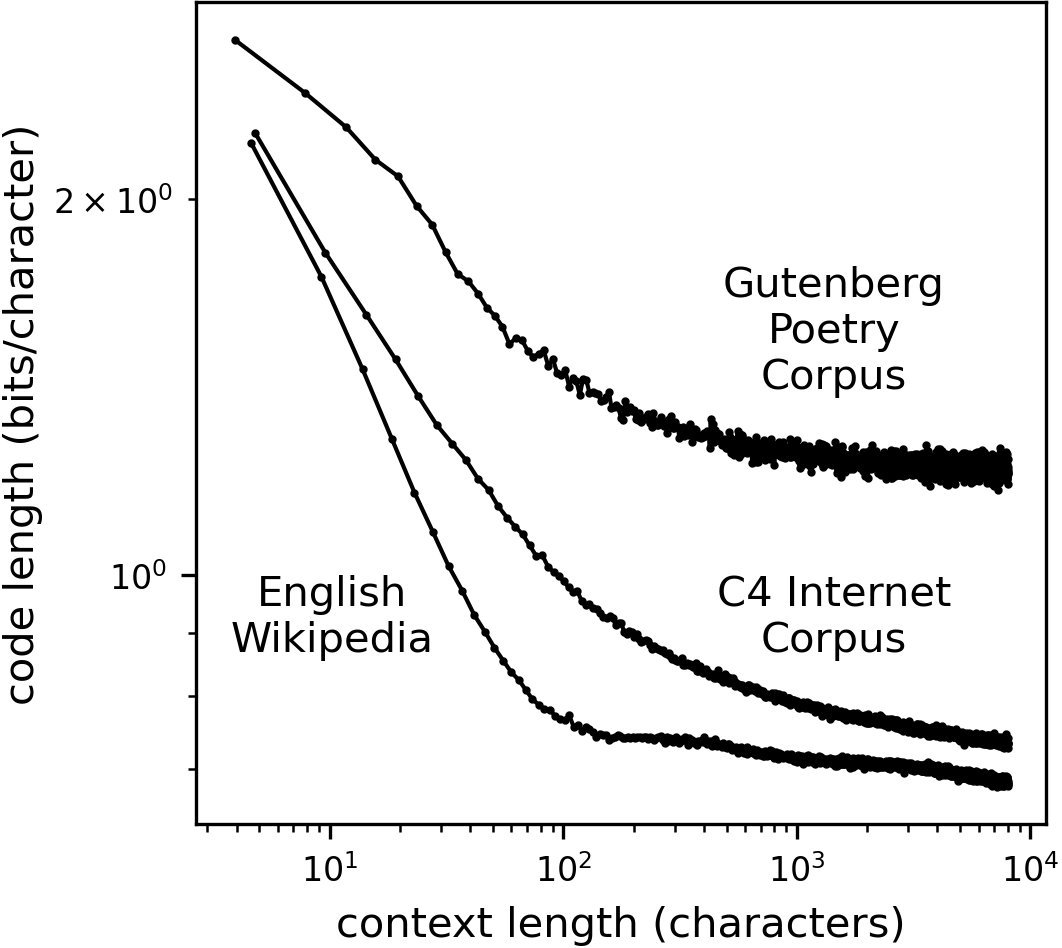
图2:不同体裁文本的码长变化。诗歌(绿色)明显比互联网文本(蓝色)和维基百科(橙色)更早进入平台期。
-
互联网文本(C4)与维基百科:熵值持续下降,表现出强烈的长程依赖。
-
诗歌:码长明显更长(信息密度更高,更难预测),且在 $N$ 较大时似乎真的进入了一个平台期。
这或许暗示了不同文体背后的生成机制存在本质差异:散文和说明文依赖于贯穿全文的逻辑和叙事结构(长程关联),而诗歌则更注重局部的韵律和意象,或者说诗歌的“跳跃性”切断了长程的统计依赖。
学习的快与慢
模型是如何学会这些长程依赖的?研究人员追踪了 DCLM 1.7B 模型的训练过程。
结果显示,模型在训练初期就迅速掌握了短上下文的规律(语法、词法),使得 $L(N)$ 在小 $N$ 处迅速下降并稳定。然而,长上下文(大 $N$)处的性能提升则要缓慢得多。这表明,捕捉跨越数千字符的语义关联,是 LLM 训练中最难啃的骨头,也是模型能力“分级”的关键所在。
总结与启示
这篇论文利用 LLM 作为显微镜,让我们看清了语言在宏观尺度上的物理结构。它告诉我们:
-
香农的直觉在长尺度上需要修正:英语的冗余度和结构性关联延伸到了万字级别,远超人类直觉。
-
语言具有统计物理特性:长程幂律相关性和“涌现确定性”让语言看起来更像是一个处于临界状态的物理系统。
-
大模型的潜力:既然熵还在下降,意味着只要上下文窗口足够大、模型足够强,我们对文本的压缩和理解能力还有提升空间。
对于致力于构建下一代长文本模型的研究者来说,这意味着“Long Context”不仅仅是工程上的显存挑战,更是捕捉语言本质结构的必经之路。