让大模型学会“专注”:AWS发布Focal Attention,参数减42%,长文本性能飙升82%!
Transformer模型的能力源泉——注意力机制,有时却像一个眼神不太好的学生。当面对长篇大论时,它会努力关注所有内容,结果却常常“雨露均沾”,把宝贵的注意力浪费在不相关的“噪音”上,导致关键信息被淹没。
论文标题:Learning to Focus: Focal Attention for Selective and Scalable Transformers ArXiv URL:http://arxiv.org/abs/2511.06818v1
来自亚马逊人工智能实验室(AWS AI Labs)的一篇新论文直击痛点,提出了一种名为Focal Attention的机制。它不做复杂的结构手术,只通过一个极其简单的改动,就让大模型学会了“专注”,实现了惊人的效率和性能飞跃。
结果有多亮眼?
- 更省资源:达到同等精度,最多可节省42%的参数或33%的训练数据。
- 更强长文本能力:在长上下文任务中,性能相对提升高达17%到82%!
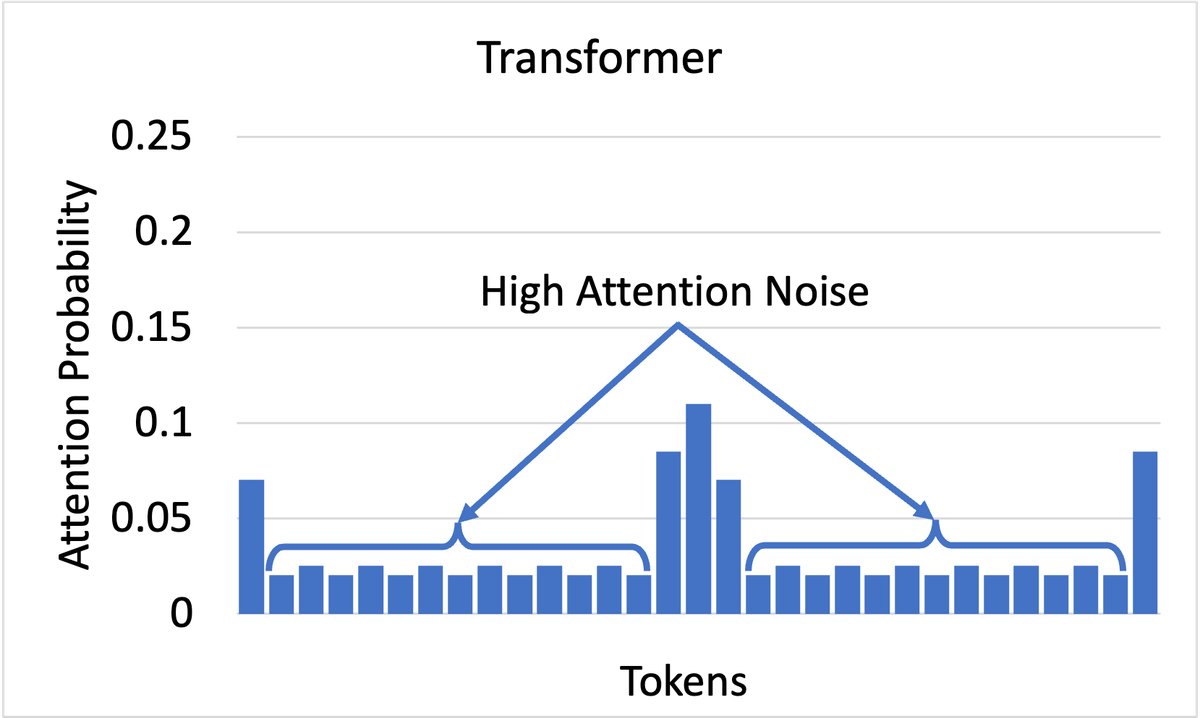 上图:标准Attention的注意力分布,较为分散和嘈杂
上图:标准Attention的注意力分布,较为分散和嘈杂 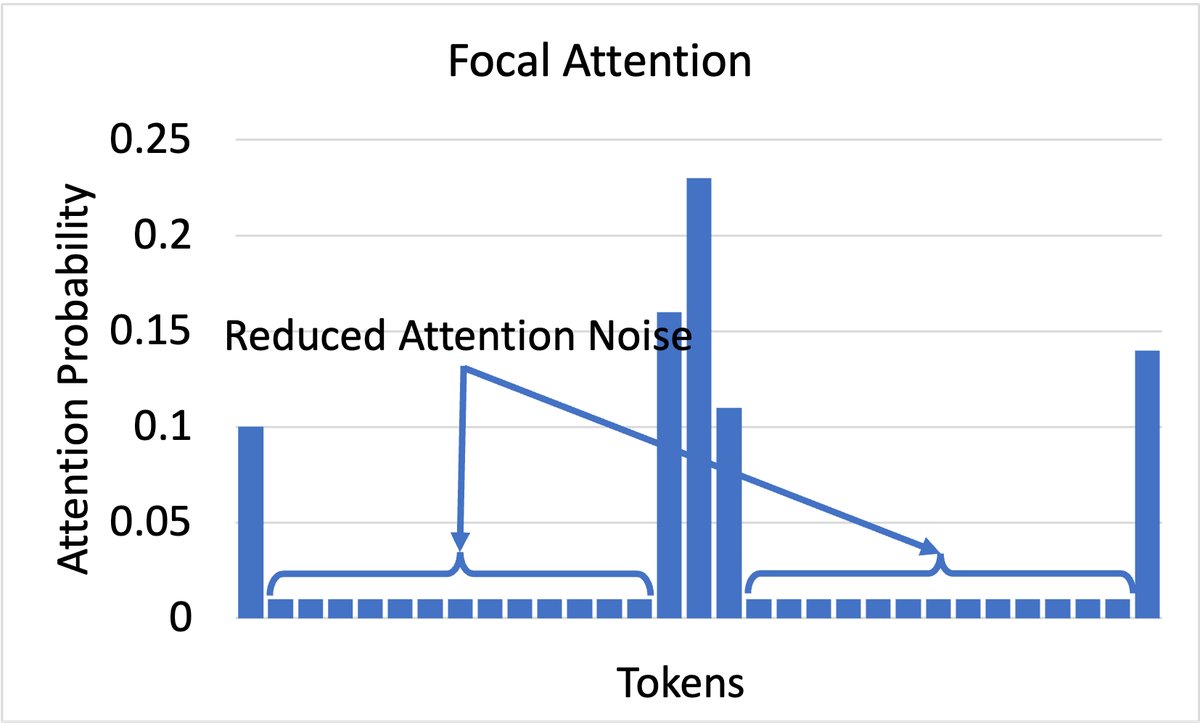 下图:Focal Attention的注意力分布,更锐利、更聚焦
下图:Focal Attention的注意力分布,更锐利、更聚焦
一、Focal Attention:给注意力机制装上“变焦镜头”
要理解Focal Attention,我们先得聊聊标准注意力中的$softmax$函数。它负责将模型的原始计算得分(logits)转换为一个概率分布,决定每个Token应该获得多少关注。
标准的$softmax$公式如下:
\[P_{i}=\frac{exp(z_{i})}{\sum_{j=1}^{n}(exp(z_{j}))}\]问题在于,这个转换过程通常很“温和”。即使某些Token的得分远低于其他Token,它们依然能分到一小杯羹。当上下文很长时,成千上万个无关Token累积起来的“噪音”就会严重干扰模型的判断。
Focal Attention的解法堪称优雅:引入一个“温度”参数$t$。
这就像给注意力机制装上了一个变焦镜头。
- 标准注意力:镜头的焦距是固定的,拍出的照片里,主角和背景都比较清晰,难以突出重点。
- Focal Attention:通过调低温度$t$($t<1$),相当于拧动变焦环,锐化焦点。这使得得分最高的Token获得绝大部分注意力,而其他无关Token的注意力则被急剧压缩,几乎可以忽略不计。
Focal Attention的核心公式就这么简单:
\[P_{i}=\frac{exp(z_{i}/t)}{\sum_{j=1}^{n}(exp(z_{j}/t))}\]这个温度$t$可以有两种玩法:
- 固定温度:直接给整个模型设置一个固定的、较低的温度值(如$t=0.4$)。简单粗暴,但效果拔群。
- 可学习温度:让模型自己学习每一层、每一个输入的最佳“焦距”。低层可能需要更广的视角来捕捉全局信息,高层则需要更锐利的焦点来做出决策。这就像一个“自动变焦”系统。
二、卓越的缩放特性:更少资源,更强性能
Focal Attention的威力在 scaling law 上体现得淋漓尽致。研究表明,它在模型尺寸、训练数据和上下文长度三个维度上都比标准Transformer扩展得更好。
1. 用更少的参数达到同等性能 实验显示,Focal Attention模型可以用比基线模型少得多的参数达到相同的准确率。在某个测试点上,仅用5.5B参数的Focal Attention模型,其性能就超过了9.5B参数的基线模型,参数量减少了42%!
2. 用更少的训练数据学得更快 在对一个2.7B模型的训练中,研究者发现,使用Focal Attention的模型仅用210B Tokens的训练数据,就达到了基线模型训练315B Tokens后的性能水平。这意味着节省了33%的训练数据和计算成本!
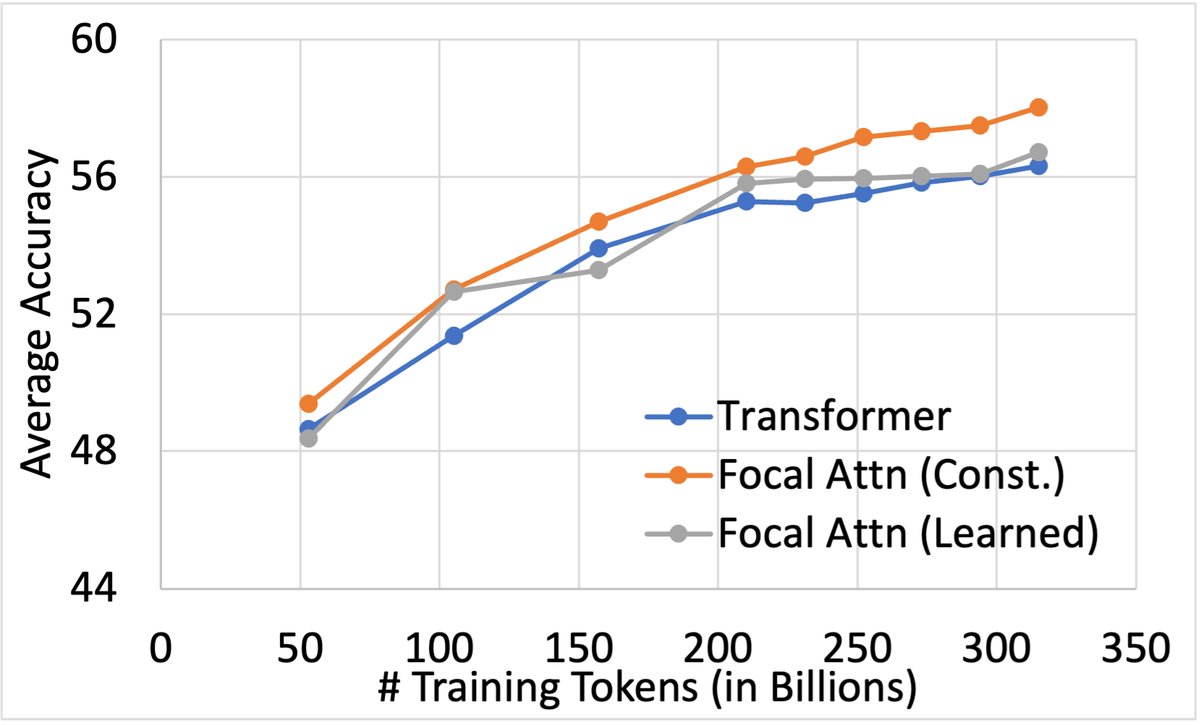 随着训练Token增加,Focal Attention(橙色和绿色线)相比基线(蓝色线)的优势越来越大。
随着训练Token增加,Focal Attention(橙色和绿色线)相比基线(蓝色线)的优势越来越大。
三、长文本任务中的绝对王者
Focal Attention真正的杀手锏在于处理长上下文。当文本长度从几千扩展到几万甚至几十万时,从海量信息中精准定位关键点的能力变得至关重要。
研究团队在一个名为HELMET的综合性长文本评测基准上,对一个经过32K上下文微调的2.7B模型进行了测试。结果令人震撼。
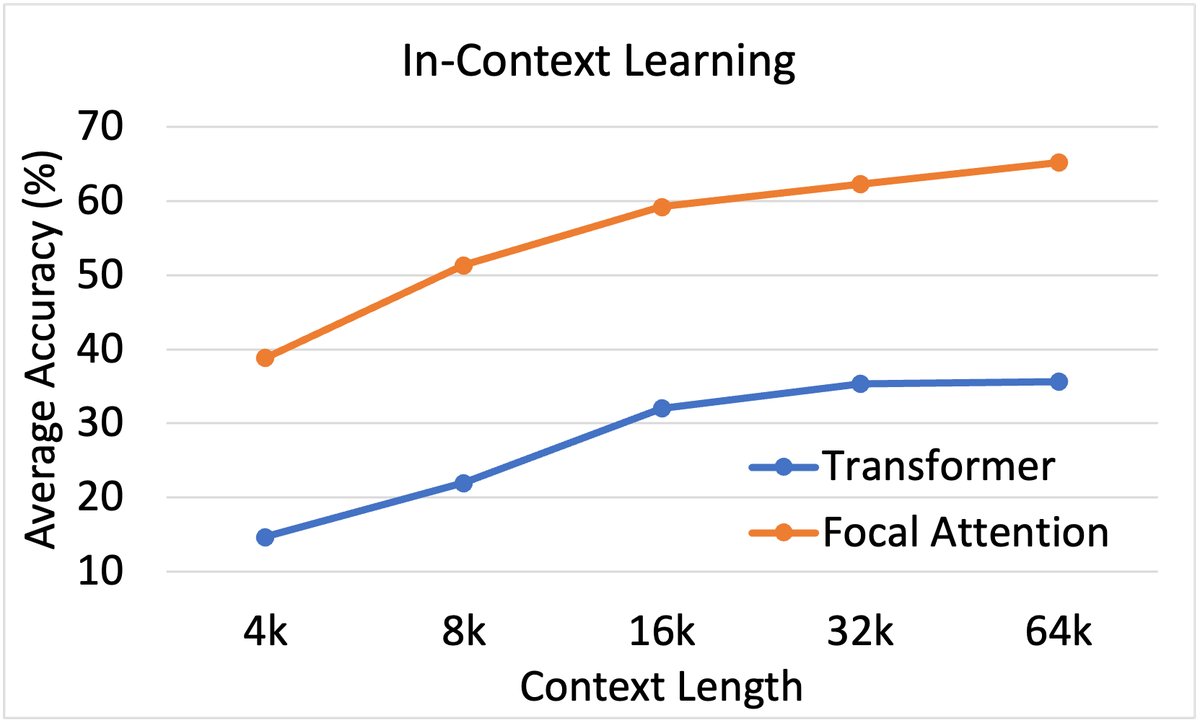 在多样本上下文学习(ICL)任务中,Focal Attention(橙色)的性能远超基线(蓝色),且上下文越长,优势越明显。
在多样本上下文学习(ICL)任务中,Focal Attention(橙色)的性能远超基线(蓝色),且上下文越长,优势越明显。
在包括多样本上下文学习(In-Context Learning, ICL)、检索增强生成(Retrieval-Augmented Generation, RAG)和信息检索等任务中,Focal Attention取得了压倒性优势。
- 对于ICL任务,当上下文中可以放入成百上千个示例时,Focal Attention能更有效地从这些示例中学习模式,准确率远超基线。
- 对于RAG任务,当模型需要在大量检索到的文档(其中混杂着干扰项)中寻找答案时,Focal Attention的“专注”能力让它能精准锁定包含答案的“黄金段落”,而不会被无关信息迷惑。
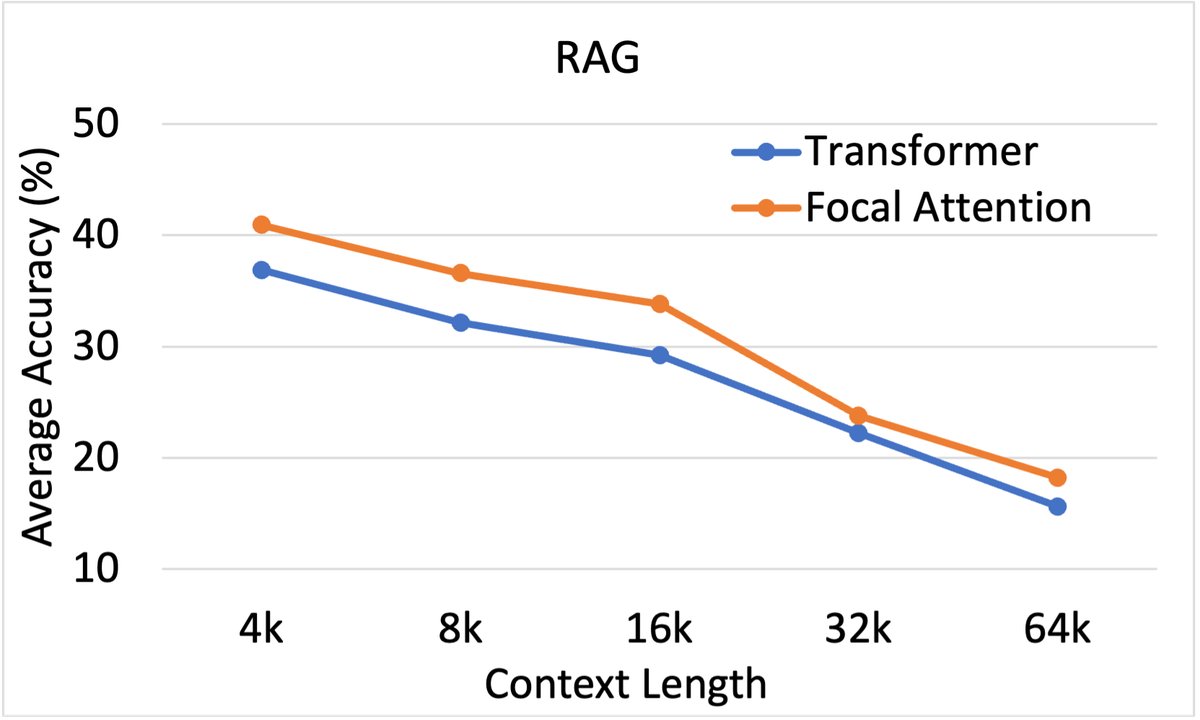 在RAG任务中,Focal Attention同样表现出持续的领先优势。
在RAG任务中,Focal Attention同样表现出持续的领先优势。
四、一些有趣的发现与结论
- 最佳温度是多少? 实验发现,并非温度越低越好。过低的温度可能会让模型变得“目光短浅”,过早地放弃了对其他可能性的探索。对于固定温度来说,$t=0.4$是一个甜点值。
- 可以中途“换装”吗? 研究者尝试将一个预训练好的标准Transformer模型,通过继续训练来适配Focal Attention。结果发现,虽然性能有所提升,但远不如从头开始就使用Focal Attention训练的模型。这表明,要发挥最大功效,最好在模型诞生之初就赋予它“专注”的能力。
总而言之,Focal Attention用一种极其简单的方式,解决了Transformer注意力机制中长期存在的“注意力分散”问题。它不仅显著提升了模型的训练和推理效率,更在长文本处理这一前沿战场上展现出巨大的潜力。这再次印证了AI领域的一个迷人法则:有时候,最深刻的突破,往往源于对基础模块最优雅、最简洁的改进。