推理成本直降75%!英伟达新研究:LLM学会“长话短说”,数学能力还不减

让大模型(LLM)学会像人一样思考和推理,是AI领域的一大难题。但更强的推理能力,往往意味着更长的“思考”过程和更高的计算成本。
ArXiv URL:http://arxiv.org/abs/2511.19333v1
有没有办法让模型既聪明又高效?
来自英伟达(NVIDIA)和DICTA的最新研究给出了一个惊喜的答案:可以!
通过学习一种更简洁的推理风格,模型在数学问题上的表现毫不逊色,而推理成本却能大幅降低75%!
推理的“学问”:从何学起?
当前,提升LLM推理能力的一个主流方法,是让模型在给出最终答案前,先生成一步步的中间思考过程。
这个过程被称为推理轨迹(Reasoning Traces),就像学生在草稿纸上演算一样。
像DeepSeek-R1和OpenAI的gpt-oss这类顶尖的开源推理模型,就擅长生成高质量的推理轨迹。
研究者们发现,可以利用这些“学霸”的解题思路,作为高质量的“教材”,去微调和训练中小型模型,教它们学会推理。
但这带来一个新问题:不同的“学霸”有不同的解题风格。
有的喜欢洋洋洒洒,每一步都详细论证(如DeepSeek-R1),有的则言简意赅,直击要点(如gpt-oss)。
到底哪种风格的“教材”对“学生”的成长更有利呢?这正是本文要探讨的核心。
一场风格迥异的“教学实验”
为了找到答案,研究团队设计了一场对比实验。
他们准备了30万道数学题,并让\(DeepSeek-R1\)和\(gpt-oss-120b\)这两位“老师”分别给出带有推理轨迹的解答。
结果发现,\(gpt-oss\)的解答平均长度约为3500个Token,风格非常简洁。
接着,他们挑选了\(Mistral-Nemo-12B\)这个12B参数级别的模型作为“学生”,并基于两种不同的推理轨迹数据,分别对其进行微调。
整个实验在NVIDIA DGX Cloud云平台上进行,并使用了NVIDIA NeMo框架,确保了训练的高效和稳定。
惊人发现:简洁即是力量
实验结果令人眼前一亮!
研究者在多个数学基准测试上评估了两个微调后的模型,结果如表1所示。
| 模型训练数据 | Pass@8 准确率 | 平均Token使用量 |
|---|---|---|
| DeepSeek-R1 Traces | 53.6 | 1900 |
| gpt-oss Traces | 53.1 | 470 |
结果显示,用\(gpt-oss\)简洁风格训练的模型,在准确率上与\(DeepSeek-R1\)冗长风格训练的模型几乎持平,但推理时生成的Token数量却少了整整4倍!
这意味着,模型的推理成本和延迟可以大幅降低。
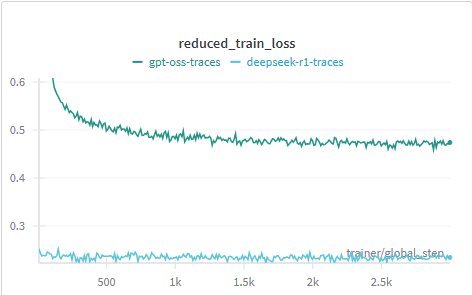
图1: 在Nemotron-Nano-12B-V2上微调时的训练损失曲线
上图的训练损失曲线也揭示了一个有趣的现象。
使用\(DeepSeek-R1\)数据微调时,模型的损失从一开始就很低且变化不大。这是因为基础模型在预训练阶段已经接触过类似风格的数据。
而使用\(gpt-oss\)数据微调时,损失从一个较高的值开始,然后稳步下降,这表明模型确实在努力学习一种全新的、更高效的推理模式。
“少即是多”背后的启示
这项研究初步证明了一个重要观点:在数学推理任务中,更冗长的思考过程(更多的Token)并不一定带来更好的性能。
模型完全可以被训练成一个“言简意赅”的思考者,在保持高准确率的同时,大幅提升推理效率。
这一发现对于LLM的实际部署具有重大意义。更少的Token意味着更低的API调用成本和更快的响应速度,这对于构建可扩展、低延迟的AI应用至关重要。
当然,研究者也指出,目前该结论主要在数学领域得到验证。未来,需要进一步探索这种“简洁推理”是否同样适用于编程、创意写作等其他领域。
同时,探索混合两种推理风格进行训练,让模型学会根据问题难度自动选择“详略”,将是一个非常有价值的研究方向。
为了推动社区发展,该研究中使用的对比数据集已在HuggingFace上公开,供更多研究者探索。