Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
别再堆Thinking Tokens了!qTTT让长文本性能暴涨14%

长文本(Long Context)已经成为大模型竞赛的必争之地,百万级 Token 的上下文窗口似乎已成标配。然而,也就是在我们将海量文档塞给模型时,一个尴尬的现实浮出水面:模型“读得进去”,但未必“找得出来”。
ArXiv URL:http://arxiv.org/abs/2512.13898v1
为了解决长文本推理难题,业界普遍的做法是让模型“多思考一会儿”——即生成思维链(Chain-of-Thought)或“Thinking Tokens”。但这真的是最优解吗?
来自哈佛大学、Meta、OpenAI 等机构的研究者给出了否定的答案。他们发现,在超长上下文中,单纯增加 Thinking Tokens 的收益会迅速递减。为此,他们提出了一种名为 Query-only Test-Time Training (qTTT) 的新方法:与其让模型带着原本“近视”的眼睛看更久,不如在推理时花一点点计算量,先把“眼镜”度数配准。
这项技术在 Qwen3-4B 模型上,于 LongBench-v2 和 ZeroScrolls 基准测试中分别带来了 12.6% 和 14.1% 的惊人提升。
长文本的隐形杀手:分数稀释
为什么现在的长文本模型会“丢三落四”?研究团队首先对这一现象进行了病理诊断。
在标准的 Transformer 架构中,注意力机制(Self-Attention)的核心是计算 Query 和 Key 的相似度,然后通过 $softmax$ 归一化。然而,当上下文长度 $T$ 激增时,即便包含了正确答案的那个 Token(我们称之为“针”,Needle)产生了一个较高的 Logit 值,它也面临着巨大的风险。
因为随着 $T$ 的增长,会有成千上万个无关的 Token(干扰项,Distractors)产生微小的 Logit。这些微小的数值在 $softmax$ 的分母中累积,最终导致“针”的注意力权重 $\alpha_{i,j^{\star}}$ 被严重稀释。
论文将这种现象命名为分数稀释(Score Dilution)。
研究者推导出了一个对数间隔要求(Logarithmic Margin Requirement):为了防止注意力权重消失,目标 Token 和干扰项之间的 Logit 差值必须随着上下文长度 $T$ 的增加而以 $\Omega(\log T)$ 的速度增长。
遗憾的是,静态的注意力机制无法自动满足这一要求。更糟糕的是,目前流行的“Thinking Tokens”策略,本质上是在使用相同的静态参数生成更多 Token。如果模型原本的注意力机制就已经被稀释了,生成再多的思考过程也无法从根本上“捞”出被淹没的信号。
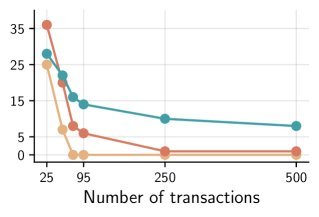
图 1(b):随着上下文长度增加(横轴),仅靠上下文(蓝色)和增加 Thinking Tokens(橙色)的效果都在下降,而 qTTT(绿色)依然坚挺。
qTTT:推理时的“微创手术”
既然静态的注意力权重不够好,那我们能不能在推理的时候,针对当前的输入,临时“训练”一下模型?
这就是测试时训练(Test-Time Training, TTT)的思路。但是,传统的 TTT 需要更新所有参数,这会导致 KV Cache 失效,意味着每更新一次梯度,就要重新计算一遍长达百万 Token 的前向传播,计算成本高到无法接受。
作者提出的 Query-only TTT (qTTT) 巧妙地解决了这个问题。它的核心思想极其简单且高效:
-
只做一次 Prefill:输入长文本,计算并缓存所有的 Key ($K$) 和 Value ($V$)。
-
只更新 Query:在推理阶段,我们保持 $K$ 和 $V$ 不变(这样就不需要重新计算 KV Cache),仅仅通过梯度下降更新注意力层中的 Query 投影矩阵 $W_Q$。
-
目标明确:通过无监督或自监督的损失函数,让 Query 向量主动向“针”靠拢,人为地拉大目标与干扰项之间的 Logit 差距。
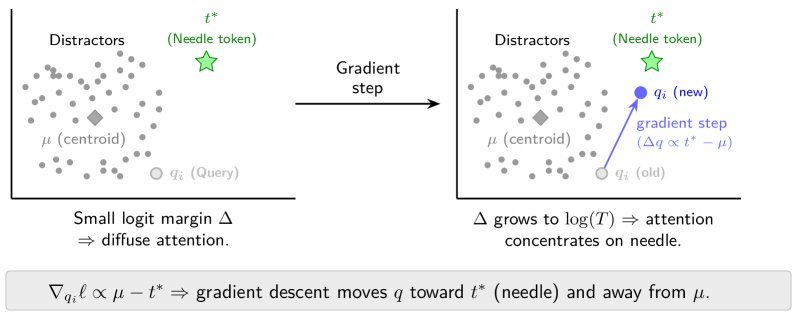
图 3:qTTT 的直观演示。标准的注意力(左)中,Query 可能离目标 Key 很远。通过 qTTT 更新(右),Query 被推向目标 Key,直接抵抗了分数稀释。
这种方法就像是在考试时,允许你根据题目的特点,临时调整一下你的眼镜焦距,而不是让你用模糊的视力多读几遍题。
实验结果:碾压式的性能提升
研究团队在 15+ 个现实世界的长文本数据集上进行了测试,涵盖了代码理解、多文档问答等任务。实验主要基于 Qwen3 系列模型(1.7B 到 8B 参数)。
结果显示,qTTT 是一种比 Thinking Tokens 更高效的计算分配方式。
在保持推理计算量(FLOPs)一致的前提下(即 qTTT 的梯度更新计算量等于生成若干 Thinking Tokens 的计算量),qTTT 的表现大幅超越了基线。
-
大幅涨点:在 LongBench-v2 和 ZeroScrolls 上,Qwen3-4B 的平均准确率分别提升了 12.6% 和 14.1%。
-
越长越强:在极长上下文(如 100k+ Token)的任务中,传统方法的性能断崖式下跌,而 qTTT 依然能保持较高的检索精度。
-
代码任务奇效:在涉及代码库层级依赖的复杂任务中,qTTT 展现出了极强的“大海捞针”能力。
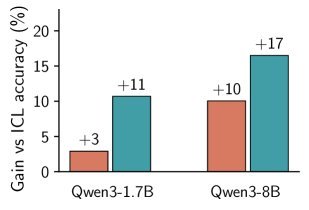
图 1(c):在 LongBench-v2 和 ZeroScrolls 两个权威基准上,qTTT 带来了显著的性能飞跃。
总结与启示
这篇论文给当前火热的“Scaling Inference Compute”(扩展推理计算)泼了一盆冷水,但也指明了一条新路。
它告诉我们,对于长文本任务,盲目地让模型“多想”可能是在做无用功。当注意力机制本身因为长下文而失效时,生成再多的 Token 也是枉然。
相反,qTTT 证明了在推理阶段进行极少量的、针对性的参数更新(Specific Training),其性价比远高于生成式扩展。这种“磨刀不误砍柴工”的策略,或许才是解锁大模型超长上下文能力的正确姿势。