LinMU: Multimodal Understanding Made Linear
告别$O(N^2)$!LinMU让多模态大模型实现线性复杂度,推理提速9倍

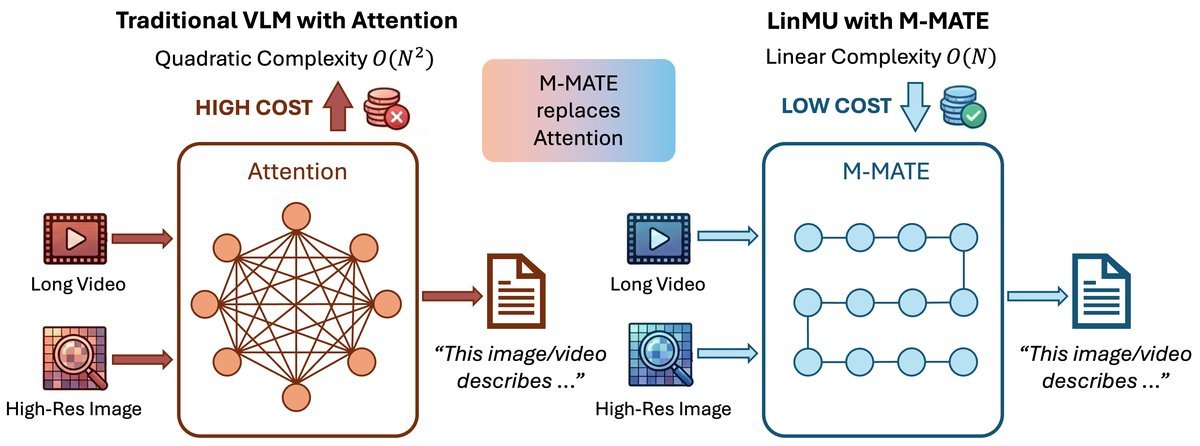
当前最先进的多模态大模型(VLMs)虽然在理解图像和视频方面表现惊人,但它们都有一个共同的“阿喀琉斯之踵”:基于Transformer的自注意力机制带来的二次方计算复杂度($O(N^2)$)。这意味着,随着输入视频变长或图像分辨率变高,计算成本会呈爆炸式增长。
ArXiv URL:http://arxiv.org/abs/2601.01322v1
普林斯顿大学的研究团队近日提出了一种名为 LinMU 的全新架构,试图打破这一瓶颈。LinMU 成功将多模态理解的复杂度降低到了线性水平($O(N)$),在保持与顶级教师模型(如 NVILA-8B, Qwen2.5-VL)性能相当的同时,将长视频的推理吞吐量提升了最高 9 倍。
核心设计:M-MATE 模块
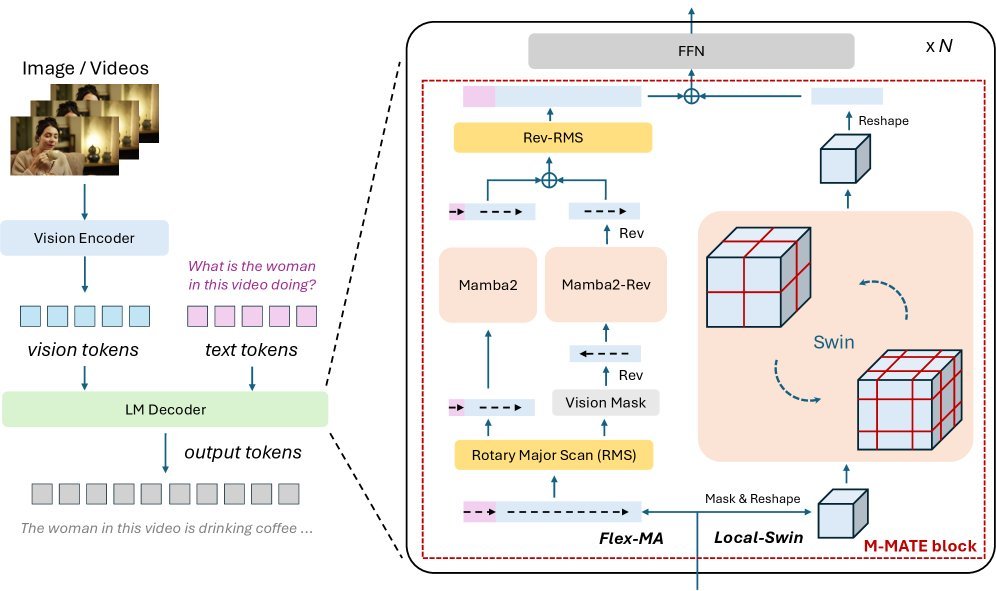
LinMU 的核心思想非常直接:彻底移除 VLM 中昂贵的自注意力层,取而代之的是一种名为 \(**M-MATE**\) 的线性复杂度模块。
单纯使用线性模型(如 Mamba)处理视觉任务往往会遇到“邻接性丢失”的问题,即图像被展平为序列后,空间上相邻的像素在序列中可能相隔甚远。为了解决这个问题,LinMU 设计了巧妙的双分支结构:
-
Flex-MA 分支(全局上下文):
基于双向的 \(**Mamba2**\) 模型。利用状态空间模型(SSM)的线性特性来捕捉长距离的依赖关系和全局上下文。它就像模型的“望远镜”,负责看清整体轮廓。
-
Local-Swin 分支(局部细节):
采用固定窗口大小的 \(**3D Swin Attention**\)。它只关注局部的时空相关性,计算量是线性的。它就像模型的“显微镜”,负责捕捉相邻像素间的精细关联。
通过这种“全局线性混合 + 局部精确注意”的组合,LinMU 既享受了 Mamba 的高效率,又保留了 Attention 在处理局部视觉特征时的优势。
三阶段蒸馏:从 Attention 到 Linear 的平滑过渡
如何将一个训练好的、基于 Attention 的强大 VLM 转换为线性的 LinMU 架构?直接从头训练成本太高,且容易掉点。研究团队提出了一套精密的三阶段蒸馏框架:
-
权重复用初始化:首先,利用教师模型(Teacher)的 Attention 权重来初始化学生模型(Student)的 M-MATE 分支,不让模型“白手起家”。
-
阶段一:冻结其他部分,仅训练 Flex-MA 分支。让 Mamba 先学会模仿 Attention 的全局注意力模式。
-
阶段二:解冻 Local-Swin 分支,与 Flex-MA 联合训练。此时模型开始补全局部细节的建模能力。
-
阶段三:通过 \(**LoRA**\) 微调其余的骨干网络层。这一步是为了让整个模型适应新的线性模块,进一步对齐教师模型的隐藏状态和输出分布。
性能与效率的完美平衡
LinMU 的表现如何?实验结果令人印象深刻。
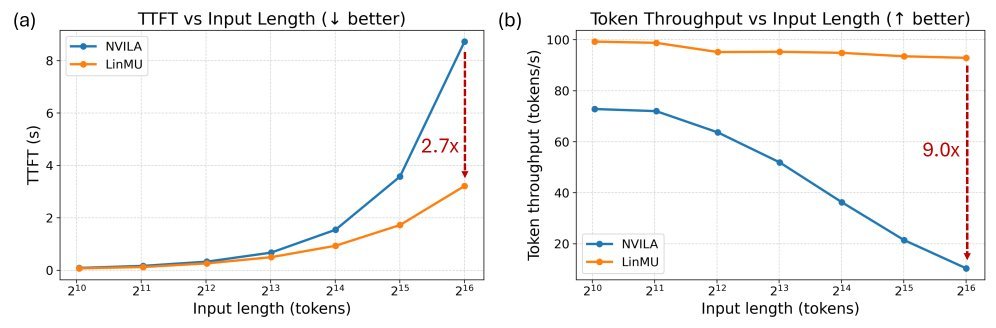
在 MMMU、TextVQA、LongVideoBench 和 Video-MME 等多个主流基准测试中,LinMU 的性能几乎与它的教师模型(NVILA-8B-Video 和 Qwen2.5-VL-7B)持平。这证明了线性注意力机制完全有能力处理复杂的多模态推理任务。
但在效率方面,LinMU 展现出了巨大的优势:
-
首字生成时间(TTFT):缩短了最多 2.7倍。
-
Token 吞吐量:在处理分钟级长视频时,吞吐量提升了惊人的 9.0倍。
下图展示了随着输入序列长度增加,LinMU 相比传统 VLM 在延迟和吞吐量上的巨大优势:
总结
LinMU 的出现证明了在多模态领域,“高性能”与“线性复杂度”并非不可兼得。通过 M-MATE 模块和精心设计的蒸馏策略,我们可以在不牺牲理解能力的前提下,大幅降低计算门槛。这为未来在边缘设备上部署能够理解长电影、高分辨图像的超长上下文 VLM 打开了大门。