即插即用LoRA!LoGo实现零成本动态适配,推理性能最高提升3.6%

当下的AI社区,低秩适应(Low-Rank Adaptation, LoRA)无疑是最火的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术。每个人都在训练自己专属的LoRA模型,从代码助手到小说家,LoRA模型库正以前所未有的速度扩张。
论文标题:LoRA on the Go: Instance-level Dynamic LoRA Selection and Merging
ArXiv URL:http://arxiv.org/abs/2511.07129v1
但这带来了一个棘手的问题:当用户向AI助手提出一个随机问题时,模型该如何从成百上千个LoRA“专家”中,挑出最合适的那一个或几个来回答?
是为每个任务手动加载,还是提前训练一个复杂的路由模型?前者太笨,后者成本太高。
现在,来自MPI-SWS和微软的研究者们提出了一个极其优雅的方案:LoRA on the Go (LoGo)。它无需任何额外训练,就能在推理时为每个输入动态选择并融合最合适的LoRA!
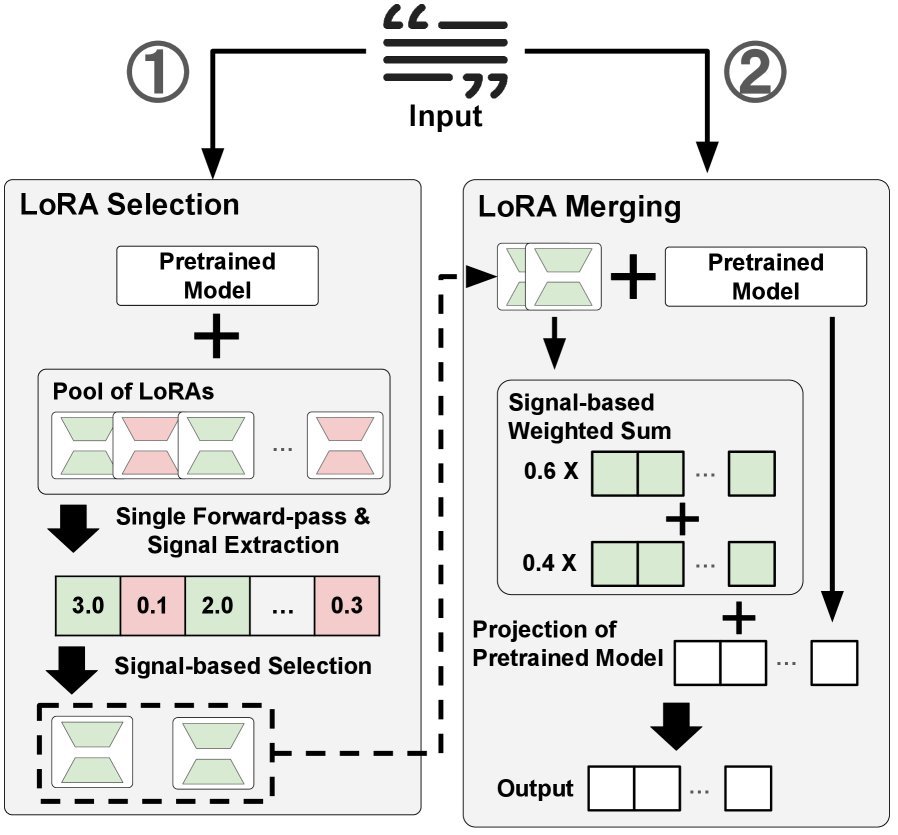
LoGo如何工作:一次前向传播定乾坤
LoGo的核心思想非常巧妙:一个LoRA是否与当前输入相关,其自身的激活状态会“告诉”我们答案。
想象一下,当一个擅长代码生成的LoRA遇到一个编程问题时,它在模型中的激活响应自然会比一个擅长写诗的LoRA更强烈。
LoGo正是利用了这一点。它的工作流程简单高效:
-
并行激活:面对一个新输入,LoGo会一次性挂载所有可用的LoRA适配器。
-
信号提取:在一次前向传播中,LoGo会从模型的特定Transformer块(如最后一个块)中,提取每个LoRA产生的激活输出。
-
计算相关性:通过计算这些激活输出的“信号强度”(如$L_2$范数或信息熵的倒数),LoGo可以量化每个LoRA与当前输入的相关性。信号越强,相关性越高。
-
动态选择与融合:LoGo选取信号最强的前 $k$ 个LoRA,并以它们的信号强度为权重,将它们的输出加权融合。
整个过程在一次前向传播中完成,完全是“即插即用”的,不需要任何标注数据,也无需为任务选择或模型融合进行任何额外训练。
实验效果:无需训练,胜似训练
纸上谈兵终觉浅,LoGo的实际效果如何?
研究团队在LLaMA-3.1-8B、Qwen-2.5-7B和DeepSeek-LLM-7B-Base三大模型家族上,对LoGo进行了严苛的测试。
实验覆盖了5大类NLP基准、共27个数据集,包括代码生成、自然语言推理、结构化文本生成等。
结果令人惊叹:在没有任何额外训练的情况下,LoGo在部分任务上的表现,竟比需要额外训练数据的LoRAHub等基线方法高出 3.6%!
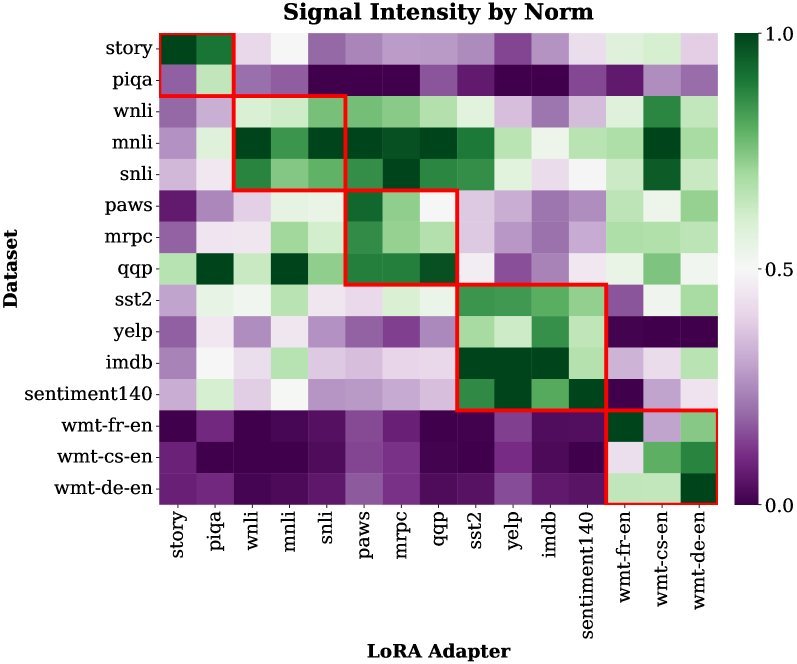
这张热图清晰地展示了,当输入特定任务的数据时(y轴),与之相关的LoRA(x轴)会表现出更强的信号范数(颜色更亮)。
更重要的是,当面对一个模型从未见过的全新任务(如CodeXGLUE编程语言基准)时,LoGo依然能够准确识别并组合相关的LoRA,表现优于所有基线方法。这证明了其强大的泛化能力。
信号真的有效吗?
LoGo的成功关键在于其提取的“信号”是否真的代表了任务相关性。
研究者通过深入分析发现,LoGo分配给每个LoRA的融合权重,与该LoRA的训练任务和当前输入任务的语义相似度,呈现出非常强的正相关关系。
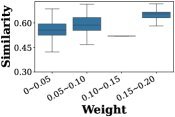
上图显示,LoGo赋予的合并权重(x轴)越高的LoRA,其任务与当前输入的相似度(y轴)也越高。这证实了LoGo的信号机制确实抓住了任务的本质关联。
简而言之,LoGo的信号机制是有效的,它能精准地“感知”到哪个LoRA更适合当前的工作。
性能与效率兼得
动态选择和融合听起来很酷,但会不会拖慢推理速度?
答案是:开销很小,且完全可以接受。
LoGo的推理时间与LoRARetriever等需要复杂检索模型的方法相当。
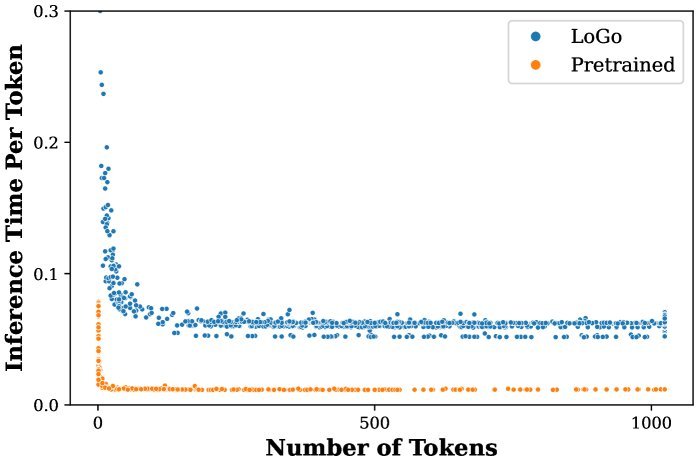
更妙的是,在长文本生成(如摘要、长篇问答)等任务中,LoGo在初始阶段进行信号提取和选择的开销,会随着生成文本长度的增加而被迅速摊销。
如上图所示,在生成大约100个Token后,每个Token的平均推理时间就已趋于稳定,证明LoGo在实际应用中极具效率。
总结
LoRA on the Go (LoGo) 提出了一种开创性的、无需训练的框架,用于在实际部署中为每个输入动态选择和合并LoRA适配器。
它通过一次前向传播提取轻量级信号,精准识别最相关的LoRA,实现了高效的实例级自适应。
这项研究证明了,我们不必总是依赖昂贵的额外训练来解决多任务、多领域的问题。LoGo为在真实、异构环境中部署大语言模型提供了一条极具前景的新路径,让模型能以更低的成本、更高的效率,“见机行事”。