阿里LORE:电商搜索相关性暴涨27%!大模型训练心法全公开

在淘宝、京东上搜索商品,你是否也曾被那些毫不相关的结果搞得一头雾水?明明想买“晨C晚A”的护肤品,出来的却是维生素C片。这种体验的背后,是电商搜索领域一个核心且棘手的难题:相关性判断。
ArXiv URL:http://arxiv.org/abs/2512.03025v1
现在,阿里巴巴给出了一个惊艳的答案。
他们推出了名为LORE的大模型框架,历时三年、三轮迭代,最终在线上实现了高达 +27% 的“好评率”(GoodRate)累计提升!
这不仅仅是一个模型的胜利,更是一套可复制、可借鉴的完整方法论。今天,我们就来深入解读这份来自阿里的“电商搜索大模型训练心法”。
破局点:别把相关性当成一件事
过去,很多研究尝试用思维链(Chain-of-Thought, CoT)来提升大模型在搜索相关性上的表现,但很快就遇到了瓶颈。
LORE研究团队一针见血地指出:问题在于,大家把复杂的“相关性判断”看作一个单一的、笼统的推理任务。
而实际上,一个优秀的相关性模型,必须像一位资深导购员那样,同时具备三种不同的核心能力:
-
知识与推理能力 (Knowledge and Reasoning)
模型需要懂“行话”。比如,它得知道“晨C晚A”指的是“维生素C和视黄醇”的护肤组合,并能推理出“送给妈妈”意味着商品要适合中年女性。
-
多模态匹配能力 (Multi-modal Matching)
当用户搜索“蓝色上衣”,但商品标题里没写颜色时,模型必须能“看懂”商品图片,从视觉信息中找到“蓝色”这个关键属性。
-
规则遵循能力 (Rule Adherence)
有些判断需要严格遵守规则。例如,用户搜“LV包”,结果是个“二手LV包”。这不能仅靠属性匹配,而必须依据“新品/二手”的平台规则来判定相关性。
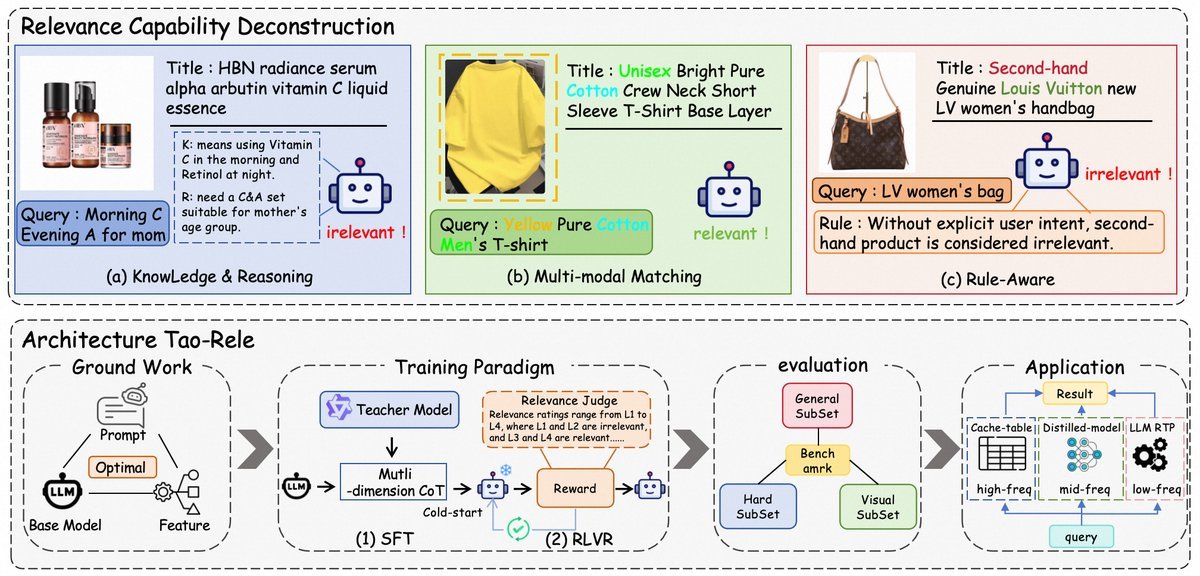
看清了这一点,LORE的整个框架便豁然开朗:先将问题拆解,再针对性地训练模型掌握这三种能力。
LORE训练蓝图:两阶段范式
为了将这三大能力“注入”大模型(研究选用了Qwen2.5-7B作为基础),LORE设计了一套精巧的两阶段训练范式。
第一阶段:SFT能力注入
在监督微调(Supervised Fine-Tuning, SFT)阶段,目标是让模型学会完整的、高质量的推理模式。
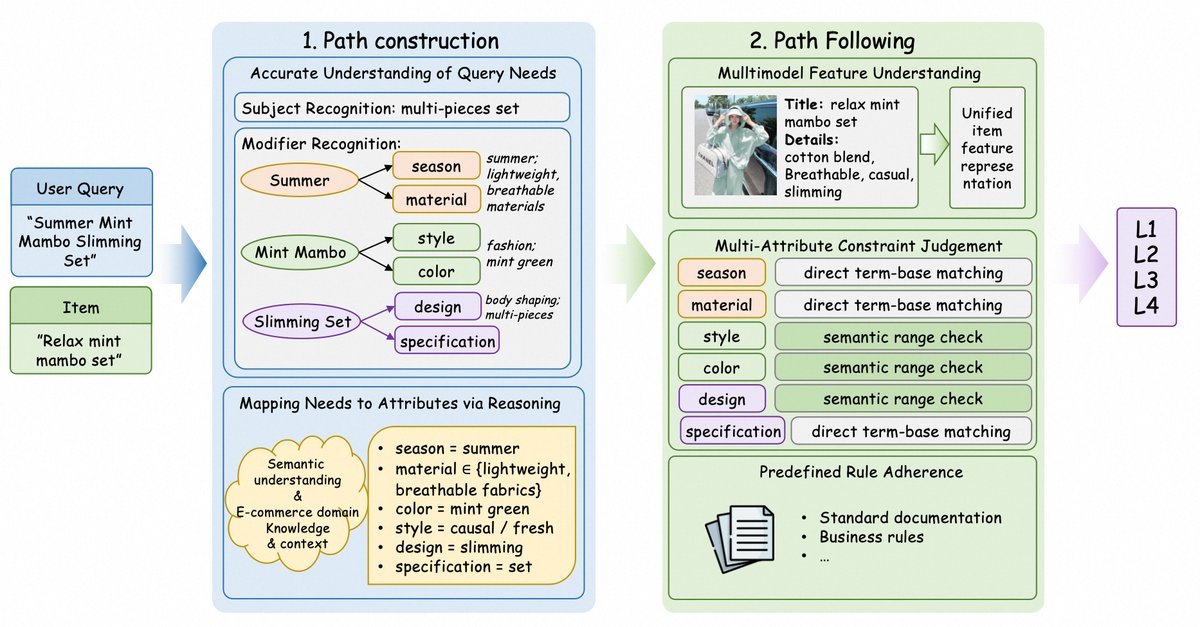
研究团队没有粗暴地灌输数据,而是采用了“渐进式CoT合成”的策略。
他们模拟了从“理解用户需求”到“匹配商品属性”再到“最终判断”的完整思考路径,生成高质量的思维链数据,让模型在SFT阶段就学到正确的“解题思路”,从而抬高模型能力的上限。
第二阶段:RL对齐偏好
学会了如何思考还不够,还得让模型的判断标准更接近“人”。
为此,LORE进入了强化学习(Reinforcement Learning, RL)阶段。
研究团队设计了一种名为RLVR(Reinforcement Learning with Verifiable Rewards)的机制。简单来说,就是让模型在SFT学会的多种推理路径中进行探索,同时用一个“验证器”来判断这些路径的优劣,并给予奖励或惩罚。
这个过程就像一位导师在批改学生的解题步骤,不断纠正错误的推理,强化正确的逻辑,最终让模型的判断与人类的偏好高度对齐。
实践出真知:来自阿里的SFT与RL宝贵经验
这篇报告最珍贵的部分,莫过于分享了大量实践中总结的“坑”与“金”。这些发现对所有从事垂域大模型微调的工程师都极具参考价值。
SFT阶段的关键发现:
-
数据并非越多越好:模型性能在数据量增加的初期会快速增长,但很快就会进入平台期,出现收益递减。
-
特征多多益善:为模型提供稳定、相关的信息,哪怕有些冗余,也能带来性能提升。
-
Prompt并非越长越好:一个包含核心信息、长度约800个Token的“中等长度”Prompt效果最好。过于冗长(7000+ Token)或过于简洁的Prompt反而会损害性能。
-
简单的CoT蒸馏效果不佳:直接用教师模型的CoT来训练学生模型,由于分布差异,效果甚至不如基础的SFT。
RL阶段的关键发现:
-
课程学习依然有效:按难度对训练数据进行排序,由易到难地训练,效果显著优于随机顺序。
-
长CoT不是目的,是结果:在RL过程中,模型输出的CoT长度并未显著增加。这表明,优秀的性能并不需要冗长的思考过程,长CoT只是模型能力提升时可能出现的副产品。
-
熵坍塌是性能天花板:训练初期,模型会迅速牺牲“探索多样性”(熵)来换取性能。当熵降到一定程度,模型探索能力受限,性能提升也就停滞了。
-
聪明的策略能延缓熵坍塌:研究发现,一种名为\(clip-higher\)的优化策略能最有效地延缓熵的下降,为模型保留了更多探索空间,从而达到更优的性能。
从实验室到线上:智能部署策略
如此强大的模型,如何高效地在真实的线上环境中部署呢?
LORE团队设计了一种“查询频率分层”的部署策略。
简单来说,就是对高频、常见的用户查询,采用更优化的方式将LORE的能力“蒸馏”到线上服务中;而对于低频、复杂的查询,则可以调用更完整的模型能力。这种差异化的策略,在成本和效果之间取得了绝佳的平衡。
正是这一整套从理论解构、训练范式、实践总结到智能部署的完整蓝图,共同造就了LORE在线上+27%的惊人效果。
结语
LORE的成功,为我们展示了在特定领域(如电商)应用大模型的正确姿势:它不是简单地调用一个通用大模型,也不是盲目地堆砌数据进行微调。
关键在于深入理解任务本质,进行系统性地解构,并围绕所需的核心能力设计针对性的训练和评估体系。
阿里LORE不仅为电商搜索领域提供了一个强大的解决方案,其背后的思想和实践经验,更为其他垂直行业如何落地大模型技术,提供了一份宝贵的行动指南。