MAI-UI Technical Report: Real-World Centric Foundation GUI Agents
超越Gemini!阿里MAI-UI发布:全尺寸GUI Agent与端云协同新范式

我们距离真正的“贾维斯”还有多远?
ArXiv URL:http://arxiv.org/abs/2512.22047v1
尽管GUI Agent(图形用户界面智能体)被视为下一代人机交互的革命性技术,但现实往往是骨感的:它们要么在复杂的动态网页中迷路,要么在面对模糊指令时不知所措,更别提在手机端运行时那令人担忧的隐私和延迟问题了。
为了打破这些僵局,阿里巴巴通义实验室(Tongyi Lab)近日发布了 MAI-UI。这不仅仅是一个模型,而是一整套“全尺寸”的GUI Agent家族,参数量跨越了从端侧极致轻量化的 2B 到云端巨无霸 235B。
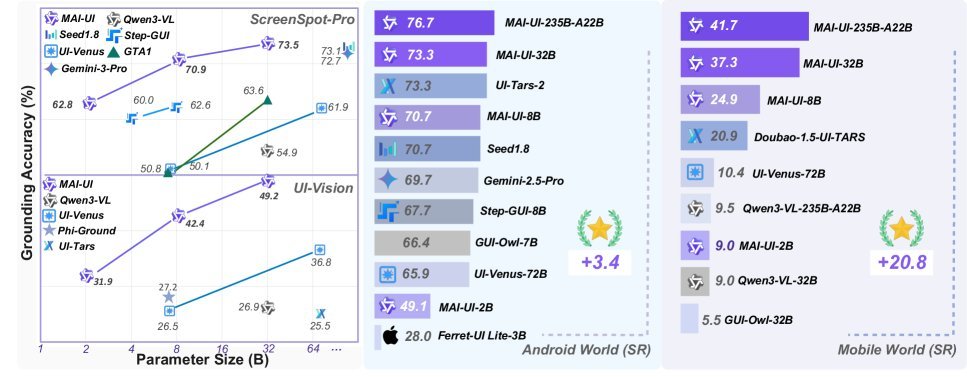
MAI-UI不仅在AndroidWorld上以 76.7% 的成功率刷新了SOTA,超越了UI-Tars-2和Gemini-2.5-Pro,更重要的是,它提出了一套端云协同(Device-Cloud Collaboration)和在线强化学习(Online RL)的全新系统架构。
痛点:为什么现在的GUI Agent还不够好?
在深入技术细节之前,我们需要理解MAI-UI试图解决的四大核心痛点:
-
缺乏“人味”的交互:大多数Agent只会埋头干活,遇到模糊指令(比如“帮我点个外卖”,但没说吃什么)就瞎猜,而不是主动询问用户。
-
纯UI操作的局限性:仅仅依赖点击和滑动(Click & Swipe)是非常脆弱的。一旦UI改版或出现弹窗,长链路操作极易中断。
-
端与云的割裂:小模型在端侧不够聪明,大模型在云端不够安全且昂贵。缺乏一个能根据任务难度动态切换“大脑”的机制。
-
动态环境的脆弱性:在静态数据上训练的Agent,一遇到真实的、动态变化的APP环境就容易“崩”。
MAI-UI的核心技术武器库
针对上述问题,MAI-UI基于 Qwen3-VL 底座,打出了一套漂亮的组合拳。
1. 超越点击:引入主动交互与MCP工具
MAI-UI扩展了Agent的动作空间(Action Space)。除了常规的点击、滑动、输入外,它新增了两个关键动作:
-
\(ask_user\):当信息不足时,Agent会主动向用户提问,而不是盲目执行。
-
\(mcp_call\):通过 模型上下文协议(Model Context Protocol, MCP),Agent可以直接调用API工具(如地图API、GitHub操作),绕过繁琐且脆弱的UI步骤。
这使得MAI-UI不再是一个只会点屏幕的“操作工”,而是一个懂得使用工具和沟通的“智能助理”。
2. 自进化的数据流水线
数据是Agent的燃料。MAI-UI构建了一个自进化数据流水线(Self-Evolving Data Pipeline)。
这个流水线包含三个阶段:任务生成、轨迹合成(结合了人工标注和模型生成)、以及迭代拒绝采样(Iterative Rejection Sampling)。
简单来说,系统会利用当前的Agent去尝试完成任务,成功的轨迹会被加入训练集,失败的轨迹如果前半段正确也会被回收利用。这种“左脚踩右脚”的迭代方式,让模型和数据同步进化。
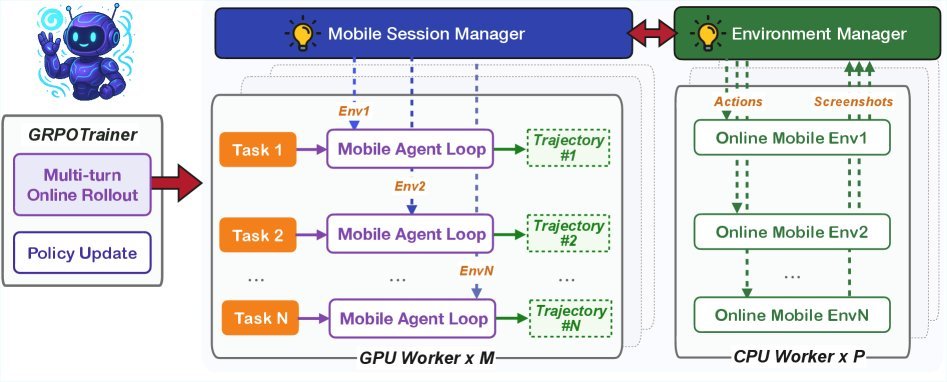
3. 大规模在线强化学习(Online RL)
这是MAI-UI最硬核的技术亮点之一。为了解决动态环境适应性问题,研究团队引入了在线强化学习。
但这并不容易,因为GUI环境是“有状态”的(Stateful),不像数学题那样可以随时重置。为了解决效率问题,MAI-UI采用了基于 verl 框架的异步训练架构,并实现了混合并行(Hybrid Parallelism)策略。
-
规模化环境:系统支持并行运行 500+ 个GUI环境进行采样。
-
长序列处理:针对动辄数百万Token的超长操作轨迹,利用Megatron的TP+PP+CP多维并行技术,实现了端到端的策略更新。
实验表明,仅将并行环境从32扩展到512,就带来了 +5.2 个点的性能提升。
4. 原生端云协同系统
MAI-UI并没有在“端侧”和“云侧”之间二选一,而是设计了一个原生端云协同系统。
-
端侧模型(2B/8B):负责处理隐私敏感数据和简单的高频操作,响应快,零成本。
-
云端模型(235B):当任务变得复杂,或者端侧模型搞不定时,系统会根据任务状态动态路由到云端大模型。
这种设计使得端侧性能提升了 33%,同时减少了 40% 以上的云端调用,完美平衡了性能、成本和隐私。
实验结果:全面霸榜
MAI-UI在多个权威基准测试中展现了统治力:
-
GUI定位(Grounding):在ScreenSpot-Pro上达到 73.5%,大幅领先Gemini-3-Pro和Seed1.8。
-
移动端导航(Mobile Navigation):
-
在 AndroidWorld 上,MAI-UI取得了 76.7% 的成功率,刷新了SOTA。
-
即便是 2B 的端侧小模型,也比同量级的Ferret-UI Lite强了 75.4%。
-
-
真实场景评估:在更贴近真实的MobileWorld基准中,MAI-UI不仅在纯GUI操作上领先,在涉及用户交互和MCP工具调用的任务上,更是展现了绝对优势。
总结
MAI-UI的发布标志着GUI Agent正在从“实验室玩具”走向“工业级应用”。它不再执着于单一模型的刷榜,而是通过全尺寸模型矩阵、端云协同架构以及大规模在线RL,构建了一套可落地的解决方案。
对于开发者而言,MAI-UI展示了一条清晰的路径:未来的Agent不仅仅要“看懂”界面,更要懂得“询问”用户、“调用”工具,并在端云之间灵活穿梭。