数据生成提速15倍!Meta开源Matrix框架,用P2P架构颠覆多智能体协作

大模型训练越来越依赖高质量的合成数据,而让多个AI智能体(Agent)协作生成数据,正成为前沿趋势。但当成千上万个智能体工作流同时运行时,传统的中心化“总指挥”模式很快就会不堪重负,成为效率瓶瓶颈。
ArXiv URL:http://arxiv.org/abs/2511.21686v1
现在,Meta AI提出了一个全新的解决方案:Matrix框架。它彻底抛弃了中心协调器,引入了对等网络(Peer-to-Peer, P2P)架构,让智能体之间直接通信、协同工作。结果如何?在相同硬件下,数据生成吞吐量直接飙升了 2到15倍!
告别总指挥:P2P编排的核心思想
传统的多智能体框架通常依赖一个中心化的编排器(Orchestrator),如下图(a)所示。这个“总指挥”需要管理所有任务的执行顺序、数据流转和资源调用。当任务规模扩大到数万个时,它就成了系统的性能瓶颈。
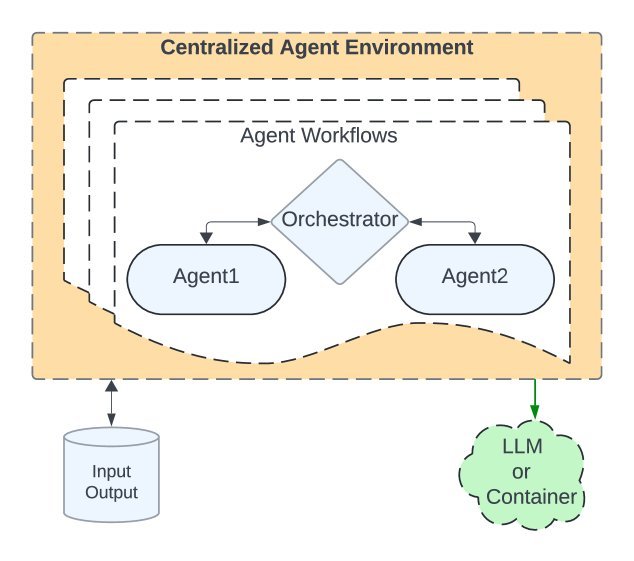
图(a): 传统中心化编排
Matrix则另辟蹊径,采用了如上图(b)所示的P2P架构。它的核心思想是:将每个任务的工作流状态,包括控制逻辑和对话历史,都封装成一个可序列化的“编排器”消息。
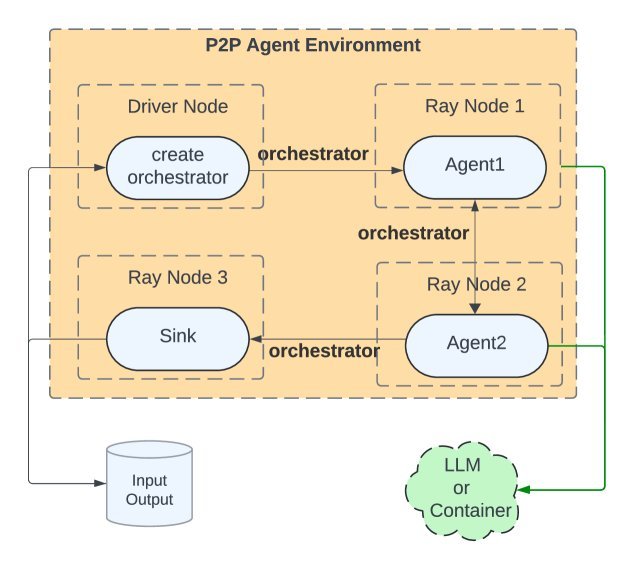
图(b): Matrix的P2P编排
这个消息就像一个“接力棒”,在不同的智能体之间传递。每个智能体接收到消息后,独立完成自己的任务,更新消息状态,然后将其传递给下一个指定的智能体。
整个过程完全异步,无需等待中央调度,从而极大地提升了系统的可扩展性和并发处理能力。
Matrix系统架构概览
Matrix构建在Ray、SLURM等成熟的开源技术栈之上,其整体架构设计清晰且模块化。
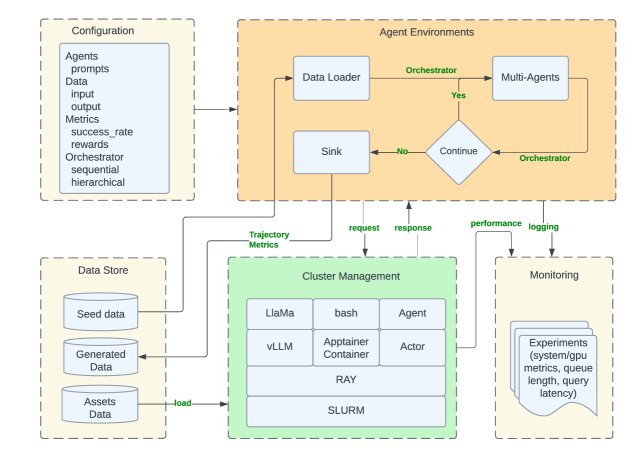
从上图可以看出,Matrix主要包括:
-
集群管理:基于Ray集群执行,通过Ray Serve提供高吞吐的LLM推理服务。
-
配置:使用Hydra进行灵活配置,可以定义智能体角色、工作流、资源需求等。
-
智能体环境:每个智能体都是一个轻量级的Ray Actor,它们通过分布式队列接收和发送“编排器”消息,实现P2P协作。
-
分布式服务:计算密集型操作(如LLM推理)和有状态任务(如容器化环境)被剥离为独立的分布式服务,可以独立扩展。
效率倍增的秘密:行级调度
传统批处理系统(如Spark或Ray Data)通常采用“批处理调度”,一次处理一批任务。这种模式的缺点是,如果批次中有一个任务执行时间特别长,整个批次都会被拖慢,导致GPU等宝贵资源闲置,产生所谓的“气泡效应”。
Matrix则采用了行级调度(Row-Level Scheduling)。每个任务(即每一行数据)都作为一个独立的“编排器”消息在智能体网络中流动。一个任务完成后,下一个任务可以立即开始,无需等待同一批次的其他任务。
这种精细化的调度方式消除了批处理的等待时间,实现了更高的资源利用率,尤其是在处理计算需求差异巨大的异构任务时,优势更为明显。
巧妙的优化:消息卸载
在智能体协作中,对话历史可能会变得非常庞大,导致“编排器”消息过大,增加网络传输负担。
一个常规的优化方法是将历史记录存入外部缓存(如Redis)。但这只是将网络流量从“智能体之间”转移到了“智能体与缓存之间”,总带宽消耗甚至可能翻倍。
Matrix的设计则更为巧妙:它将超过特定大小阈值的对话内容存储在Ray的分布式对象存储中,而在“编排器”消息里只保留其对象ID。智能体按需获取内容,任务完成后,所有相关对象即被删除。这种“消息卸载”机制既保持了消息的轻便,又显著降低了网络负载。
实验效果:吞吐量碾压式提升
口说无凭,实验数据最能说明问题。该研究在多个场景下对Matrix进行了评估。
以协同推理(Collaborative Reasoner, Coral)任务为例,该任务需要两个智能体通过多轮对话达成共识。研究团队将Matrix与Coral的官方实现进行了直接对比。
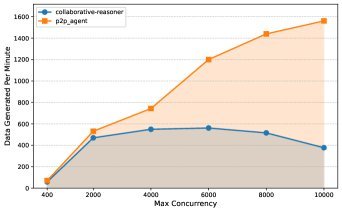
如上图所示,随着GPU节点数量的增加,Matrix的吞吐量几乎呈线性增长。而基线系统的中心化编排很快达到瓶颈,性能无法继续提升。
在一项使用31个A100节点(共248个GPU)的大规模测试中,Matrix在4小时内生成了20亿Token,吞吐量是官方实现的6.8倍,同时生成的数据质量(一致性正确率)与基线系统持平。在其他测试场景中,Matrix更是实现了高达15倍的性能提升。
总结
面对大模型时代对高质量合成数据的海量需求,多智能体协作是关键路径,而可扩展性则是其核心挑战。
Meta开源的Matrix框架,通过其创新的P2P编排架构和行级调度机制,优雅地解决了中心化瓶颈问题,为大规模、高并发的智能体工作流提供了一个高效、灵活且可扩展的运行环境。
这项研究不仅为数据合成领域带来了强大的新工具,其去中心化的设计思想也为未来更复杂的分布式AI系统的构建提供了宝贵的借鉴。
项目地址:https://github.com/facebookresearch/matrix