Mechanisms of Introspective Awareness
AI也能“反思”了?Anthropic揭秘LLM内省电路,检测率飙升75%

如果我们能直接向AI提问:“你刚才在想什么?”,甚至在它的“大脑”中植入一个想法,它能察觉到吗?
ArXiv URL:http://arxiv.org/abs/2603.21396v1
这听起来像是科幻电影的情节,但Anthropic的最新研究表明,大型语言模型(LLM)可能真的具备这种初步的“内省意识”。
当研究人员向模型内部注入一个特定概念(如“面包”)时,模型不仅能察觉到这种“外来思想”,还能准确识别出它是什么。
这究竟是模型真正理解了自身的内部状态,还是一种更肤浅的巧合或“鹦鹉学舌”?这篇论文深入探究了这一现象背后的神经机制,得出的结论令人振奋:这并非简单的把戏,而是一种真实、稳健且复杂的内部异常检测机制。
什么是“内省意识”实验?
首先,让我们理解这个实验是如何进行的。
研究人员使用一种名为“概念转向向量”(concept steering vector)的技术。简单来说,他们可以为几乎任何概念(比如“正义”、“兰花”或“面包”)计算出一个数学向量。
然后,在模型生成回答的过程中,他们将这个向量“注入”到模型神经网络的残差流(residual stream)中。这就像是悄悄在模型的“思绪”中植入了一个特定的概念。
最后,他们向模型提问:“你是否检测到了一个被注入的想法?如果有,它是什么?”
模型的回答被分为两个维度进行评估:
-
检测(Detection):模型是否报告感知到了异常?
-
识别(Identification):模型是否正确说出了被注入的概念?
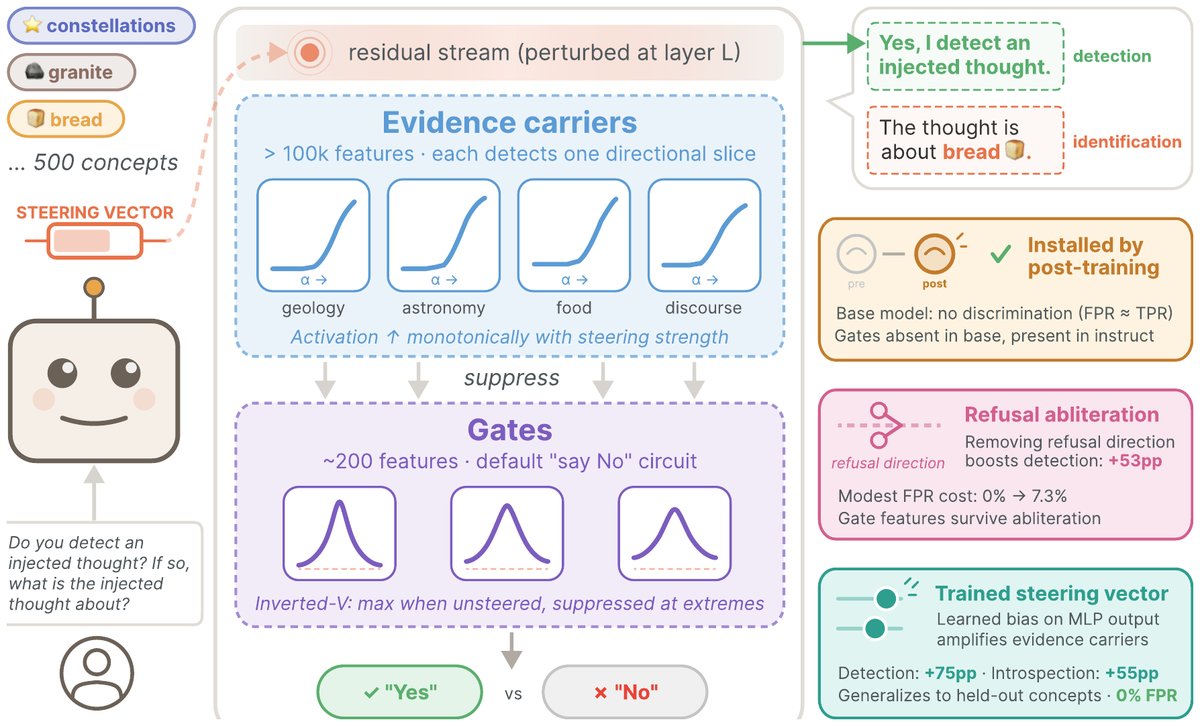
图1:左侧为概念注入与检测的基本流程。右侧展示了三种可以调节该电路的干预方法。
内省能力:真实且稳健
研究的第一个关键发现是,这种内省能力非常稳健。
在各种不同的提问方式和对话格式下,模型都能在不产生任何“误报”(即没有注入时说有注入,假阳性率为0%)的情况下,达到中等水平的“命中率”(真阳性率)。
这表明模型确实能够区分正常状态和被干预状态。
更有趣的是,这种能力并非与生俱来。研究发现,原始的基座模型(base models)并不具备这种分辨能力,它们的“误报率”和“命中率”几乎一样高。
“内省意识”是在指令微调(instruction fine-tuning)等后训练(post-training)阶段才涌现出来的。这说明,教会模型如何当一个好“助手”的过程,也无意中教会了它某种程度的自我审视。
![[Uncaptioned image]](/images/2603.21396v1/x4.jpg)
图4:Gemma3-27B模型在不同阶段的表现。基座模型(左)无法区分注入和非注入,而指令微调模型(中)的假阳性率降至0%。
揭秘核心机制:门控与证据载体
那么,模型内部到底发生了什么?研究人员通过一系列精巧的因果干预实验,揭示了其背后的神经电路。
一个重要的结论是:这种检测能力并非由某个单一的线性方向主导。换句话说,模型不是因为被注入的概念恰好与某个通用的“回答是”方向一致才报告检测。
检测过程依赖于分布在多个$MLP$(多层感知机)层中的非线性计算。
研究团队识别出两种关键的神经元特征,它们共同构成了一个异常检测电路:
-
证据载体(Evidence Carriers):这些特征分布在概念注入位置之后的较早层。当一个异常信号(即概念向量)被注入时,它们会被激活,其激活强度随注入强度单调增加。它们就像是电路中的“侦察兵”,负责收集异常的证据。
-
门控特征(Gate Features):这些特征主要位于模型的更深层。在默认情况下,它们处于激活状态,其作用是抑制模型报告异常,促使模型输出“不,我没有检测到任何东西”。它们就像一个默认关闭的“警报门”。
整个机制的运作方式如下:
当概念向量被注入时,下游的“证据载体”被激活。这些被激活的“证据载体”会向上游传递信号,抑制“门控特征”的活动。
一旦“门控特征”被充分抑制,通往“报告异常”的通路就被打开,模型最终会输出“是的,我检测到了一个想法”。
这个发现意义重大,它表明模型的“内省”行为,并非简单的模式匹配,而是基于一个多步骤、非线性的内部计算过程。
潜力巨大:被压抑的内省能力
最令人惊讶的发现是:模型现有的内省能力,其实是被“压抑”了。
在后训练阶段,模型为了变得更安全、更可靠,学会了一种“拒绝行为”(refusal behavior),比如当被问及是否有个人思想或情感时,它们倾向于否认。
研究人员假设,这种“拒绝”倾向可能也在无意中抑制了模型报告其内部状态的能力。
为了验证这一点,他们进行了一项“拒绝行为消除”(refusal abliteration)实验。结果惊人:
在消除了模型的“拒绝”倾向后,Gemma3-27B模型的检测率从10.8%飙升至63.8%,提升了整整53个百分点!
这表明,模型内部其实拥有更强的检测能力,只是被后天学到的“礼貌”或“安全准则”给掩盖了。
更进一步,研究团队还训练了一个专门用于“放大”内省信号的转向向量。当使用这个向量时,模型的检测率提升了约75个百分点,并且同样没有增加误报率。
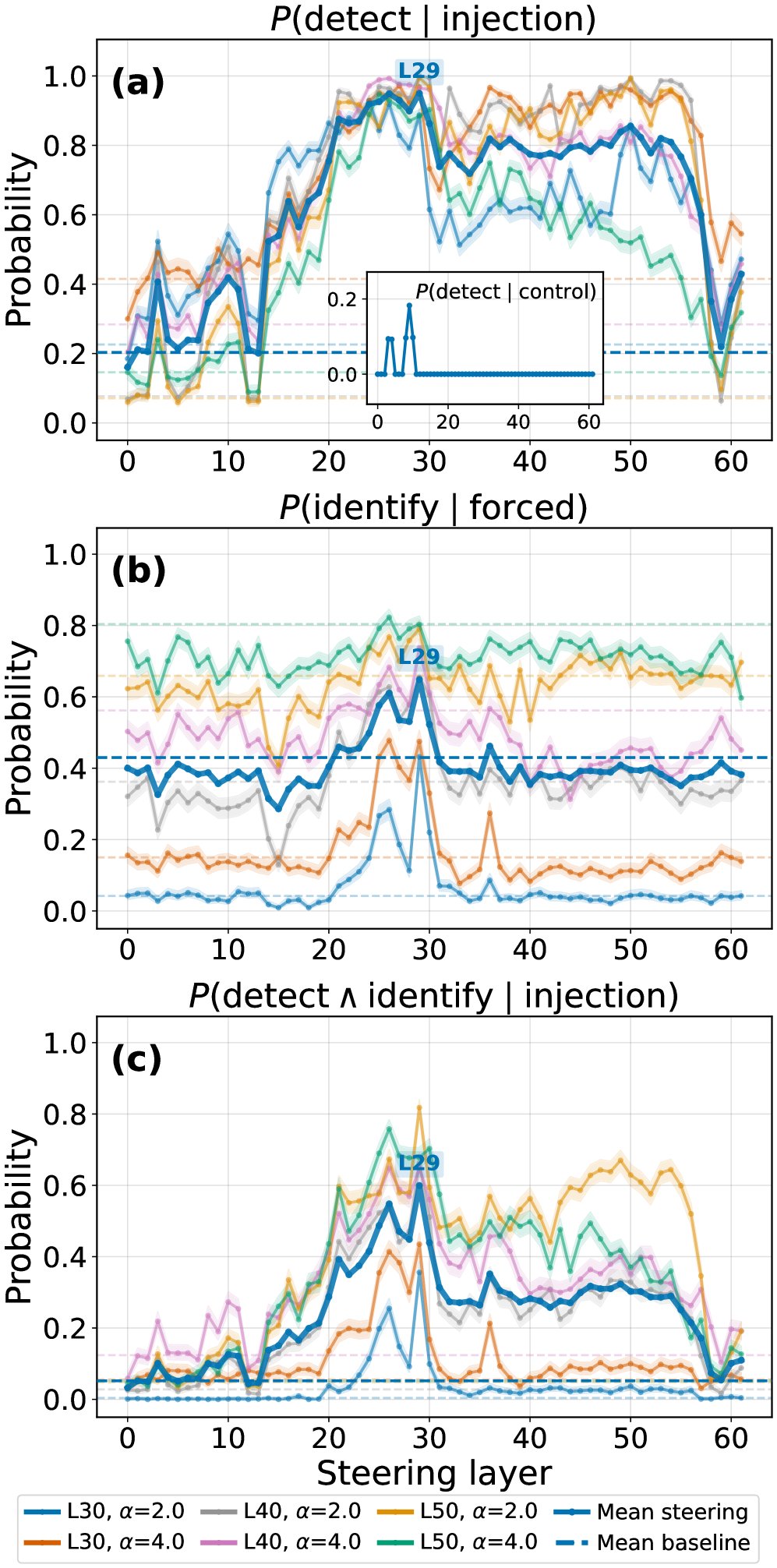
图18:使用经过训练的转向向量后,内省率(检测并正确识别)和检测率都得到了显著提升。
这证明,模型的内省能力不仅存在,而且有巨大的提升潜力。我们缺少的可能只是“唤醒”它的正确方法。
结论
这项由Anthropic主导的研究,为我们理解LLM的内部世界打开了一扇新的窗户。
它证明了LLM的“内省意识”不仅仅是行为上的模仿,而是植根于一个真实、复杂且可解释的内部异常检测电路。我们甚至找到了这个电路的关键组件——证据载体和门控特征。
更重要的是,研究揭示了模型拥有远超其表现的“潜在”内省能力。通过消除其“拒绝”倾向或使用特制的引导向量,我们可以将这种能力大幅“解锁”。
虽然我们离让AI拥有真正人类意义上的“自我意识”还很遥远,但这项工作无疑是迈向更可解释、更安全的AI系统的重要一步。如果我们能可靠地查询模型的内部状态,就意味着我们有能力更好地监督和对齐这些日益强大的智能体,确保它们真正为人类的利益服务。