Memoria: A Scalable Agentic Memory Framework for Personalized Conversational AI
告别AI“健忘症”:Memoria利用加权知识图谱打造可扩展的个性化记忆

目前的LLM(大语言模型)聊天机器人往往像是一个患有严重“健忘症”的过客:无论你们之前的对话多么深入,一旦开启新会话,它就会把你忘得一干二净。这种“无状态”的特性,使得AI难以建立长期的用户画像,也无法提供真正连贯的个性化体验。
ArXiv URL:http://arxiv.org/abs/2512.12686v1
为了解决这一痛点,来自贝莱德(BlackRock)的研究团队推出了 Memoria。这是一个模块化的记忆框架,旨在通过引入代理记忆(Agentic Memory),让LLM拥有像人类一样的持久记忆能力。Memoria不仅能记住对话内容,还能通过构建知识图谱(Knowledge Graph, KG)来理解用户的偏好与特质,从而在长周期的交互中提供精准的个性化服务。
核心痛点:当聊天机器人没有“脑子”
传统的LLM部署通常是无状态的,每一次交互都是独立的。虽然我们可以通过检索增强生成(RAG)或简单的对话历史拼接来提供上下文,但这些方法往往面临两个极端:要么上下文窗口不够用(或Token成本太高),要么检索到的信息过于碎片化,缺乏对用户整体形象的理解。
Memoria的出现,正是为了填补这一空白。它不是简单地存储聊天记录,而是通过一种混合架构,同时解决了“短期对话连贯性”和“长期个性化记忆”的问题。
Memoria的系统架构:四大支柱
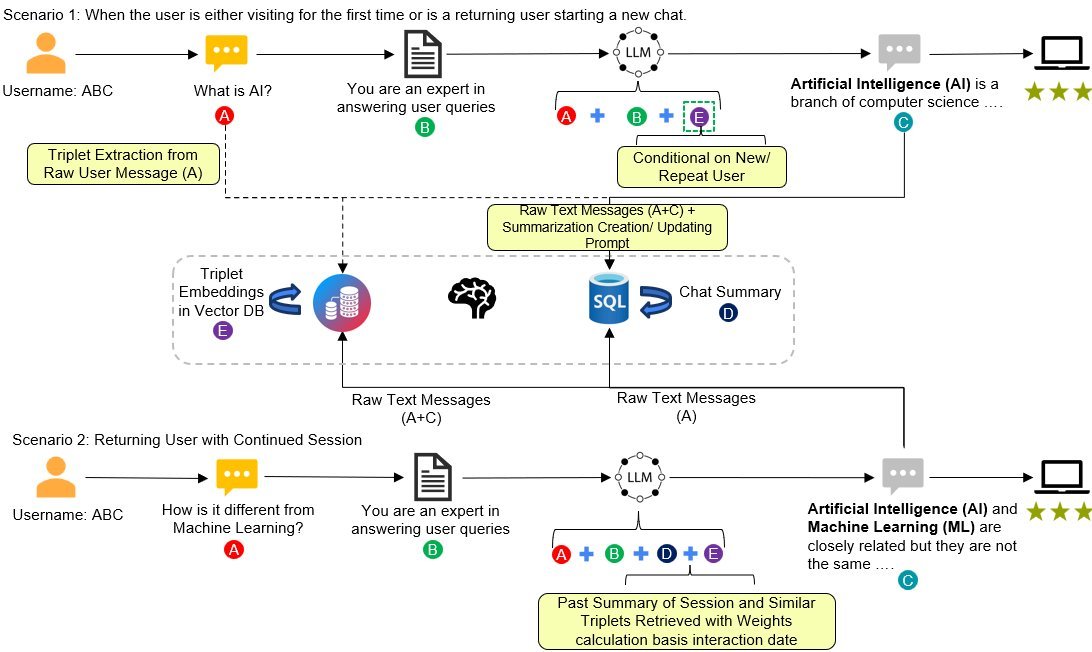
Memoria的设计理念非常清晰,它作为一个增强层嵌入到任何基于LLM的对话系统中。其核心由四个模块组成:
-
结构化对话日志(Structured Conversation Logging):
这是记忆的基础层。Memoria利用数据库将所有的交互转化为结构化的、可查询的记录。这消除了用户在跨会话时需要重复自我介绍的尴尬。
-
基于KG的动态用户画像(Dynamic User Persona via KG):
这是Memoria最“聪明”的地方。它不仅仅记录“说了什么”,还通过增量构建知识图谱来捕捉“用户是谁”。系统会从对话中提取实体和关系(例如:用户——喜欢——科幻电影),并随着对话的深入不断进化这个图谱。
-
会话级摘要(Session Level Memory):
为了处理当前正在进行的对话,Memoria会实时生成对话摘要。这确保了在多轮对话中,AI能保持上下文的连贯性,而不需要每次都把冗长的历史记录全部喂给模型。
-
上下文感知检索(Context-Aware Retrieval):
当用户在几天甚至几周后回归时,检索模块会融合“结构化历史”和“用户KG”,为当前的新查询提供最相关的背景信息。
技术亮点:加权衰减与冲突解决
在长期记忆中,最大的挑战之一是信息的时效性和冲突。比如,用户上周说“我喜欢吃辣”,但这周说“最近胃不好,不吃辣了”。如果AI只是简单检索,可能会产生矛盾。
Memoria引入了一种指数加权平均(Exponential Weighted Average, EWA)机制来解决这个问题。它根据信息的新旧程度为知识图谱中的三元组分配权重。
具体来说,对于每个三元组 $i$,其原始权重 $w_{i}$通过以下指数衰减函数计算:
\[w_{i}=e^{-a\cdot x_{i}}\]其中 $x_{i}$ 代表该信息距离当前的“距离”(如时间或对话轮数)。
随后,系统会对权重进行归一化处理:
\[\tilde{w}_{i}=\frac{w_{i}}{\sum_{j=1}^{N}w_{j}}\]这种机制确保了最近的交互拥有更高的权重。在检索时,LLM会优先考虑权重更高的信息。这意味着,如果用户的偏好发生了变化,Memoria能够自然地“遗忘”旧偏好,采纳新偏好,从而解决记忆冲突,保持用户画像的鲜活性。
工作流程:从陌生人到老朋友
Memoria根据用户的状态(新用户 vs 老用户)和会话状态(新会话 vs 进行中)动态调整其工作流:
-
新用户/新会话:系统从零开始,仅依赖当前的Prompt和用户输入。
-
老用户/新会话:这是Memoria大显身手的场景。系统会检索该用户的知识图谱(KG),提取关键的用户画像信息注入到Prompt中。这样,即便是一个全新的话题,AI也能带着对你过去的了解来回答。
-
老用户/进行中:系统同时结合“会话摘要”和“知识图谱”,既保证了当前聊天的流畅,又不丢失长期的个性化背景。
实验表现:更精准,更高效
研究团队在 LongMemEvals 数据集上对 Memoria 进行了评估,并与另一种记忆框架 A-Mem 进行了对比。实验主要关注“单会话用户记忆”和“知识更新”两个维度。
结果显示,Memoria在准确性上表现优异。特别是在处理知识更新(即用户改变偏好或纠正事实)的场景下,得益于其独特的加权衰减机制,Memoria能够更准确地识别最新的用户意图,而不是被旧的历史数据误导。
此外,在延迟和Token消耗方面,Memoria也展现出了极佳的可扩展性。相比于简单粗暴地堆砌历史记录,Memoria通过精选的KG三元组和摘要,大幅减少了输入给LLM的Token数量,这对于工业级的大规模应用至关重要。
总结
Memoria展示了如何通过结合结构化数据库、语义知识图谱和动态加权算法,构建一个既懂短期语境又懂长期偏好的AI代理。对于那些希望在客户服务、个人助理或长期陪伴型AI产品中实现深度个性化的开发者来说,Memoria提供了一个极具参考价值的开源范式。它证明了,让AI拥有“记忆”,不仅仅是存储数据,更是关于如何理解和权衡数据。