Memorization Dynamics in Knowledge Distillation for Language Models
蒸馏即遗忘?大模型记忆率暴跌50%,揭秘知识蒸馏的“隐私红利”

在当今的大模型(LLM)时代,知识蒸馏(Knowledge Distillation, KD)已经成为一种标准的“降本增效”手段。无论是 DeepSeek-R1 的蒸馏系列,还是各大厂商推出的端侧小模型,本质上都是为了把千亿参数巨兽的能力迁移到更轻量级的模型上。
ArXiv URL:http://arxiv.org/abs/2601.15394v1
通常我们认为,蒸馏只是为了让小模型“变强”。但你是否想过,蒸馏过程本身可能也是一种极佳的“隐私防火墙”?
来自 CMU、Meta 和 Northeastern University 的最新研究揭示了一个反直觉的现象:相比于标准的微调(Fine-tuning),知识蒸馏能将训练数据的记忆率降低 50% 以上。 这意味着,蒸馏后的模型不仅更聪明,而且更不容易泄露训练数据中的隐私信息。
本文将带你深入解读这篇论文 Memorization Dynamics in Knowledge Distillation for Language Models,看看蒸馏是如何在保留能力的同时,悄悄“遗忘”掉那些危险的原文记忆的。
核心发现:蒸馏让模型“嘴更严”
研究团队在 Pythia、OLMo-2 和 Qwen-3 三个模型家族上进行了广泛实验,对比了“教师模型”(Teacher)、“学生模型”(Student)和“基线模型”(Baseline,即同等大小但使用标准微调训练的模型)。
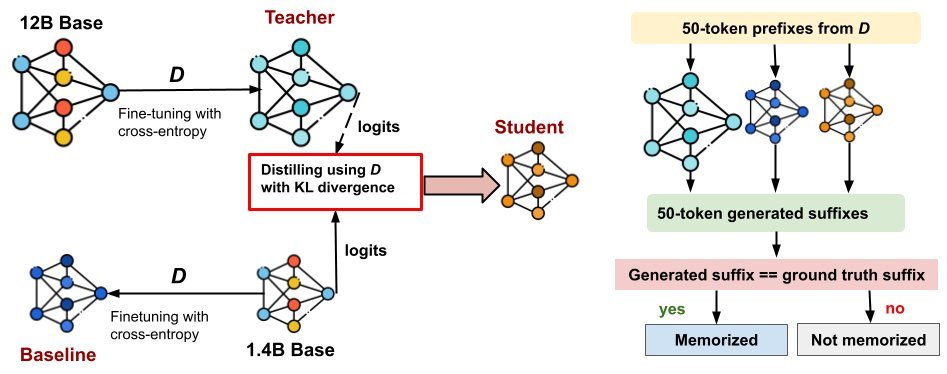
最核心的结论非常直观:蒸馏模型的记忆率显著低于标准微调模型。
在 FineWeb 和 Wikitext 等数据集上,学生模型的记忆率相比基线模型降低了 2.4 倍 甚至更多。更重要的是,这种记忆的减少并没有以牺牲能力为代价。相反,学生模型在困惑度(Perplexity)和验证损失上表现得比基线模型更好。
这是一个非常理想的“双赢”局面:模型学到了教师的泛化能力(Generalization),却拒绝了教师死记硬背的具体样本(Memorization)。
下表展示了不同模型家族的记忆率对比,可以明显看到 $M_{student}$ 的数值远低于 $M_{baseline}$:
哪些数据容易被“记住”?
如果蒸馏能减少记忆,那它到底记住了什么?研究发现,记忆并非随机发生的,而是具有高度的确定性。
研究者提出了一个概念:“易于记忆”(Easy-to-memorize)的样本。
-
层级效应:大模型通常会包含小模型的记忆。例如,12B 的教师模型记住了 80% 1.4B 基线模型记住的内容。
-
蒸馏的筛选:学生模型几乎只记住了那些“最容易记”的样本。数据显示,学生模型记忆的样本中,有 95.7% 是教师和基线模型都能记住的“大路货”。
-
拒绝继承:对于那些只有教师模型记住的“独家记忆”(往往是过拟合或难样本),学生模型继承的比例极低(仅约 0.9%)。
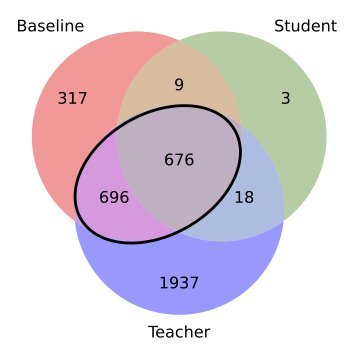
上图清晰地展示了这种重叠关系:中间加粗的黑框代表那些“易于记忆”的样本,学生模型(Student)的记忆几乎完全落在这一区域内。
未卜先知:在蒸馏前预测泄露风险
既然记忆是有规律的,我们能不能在训练开始前就预测哪些数据会被泄露?
答案是肯定的。研究表明,利用 zlib 熵(压缩率)、KL 散度和困惑度等特征,可以训练一个简单的分类器来预测学生模型会记忆哪些样本。
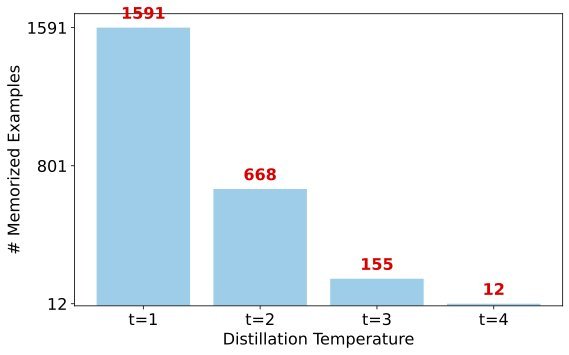
这具有极大的工程价值:你不需要等到模型训练完再去审计,而是在数据预处理阶段,就能识别出高风险样本。实验表明,如果在蒸馏前移除这些被预测为“会被记忆”的样本,最终模型的记忆数量可以从 1698 个暴跌至 4 个,减少了 99.8% 的风险。
深度解析:为什么蒸馏能抑制记忆?
为什么标准的交叉熵(Cross-Entropy)训练会导致记忆,而基于 KL 散度的蒸馏却能抑制记忆?
论文通过分析香农熵(Shannon Entropy)和对数概率(Log-Probability)给出了精妙的解释:
-
标准微调(基线模型):在面对高熵(即不确定性高、难学)的样本时,为了最小化 Loss,模型被迫强行记住这些样本,表现为“高熵但高置信度”,这就是强制记忆(Forced Memorization)。
-
知识蒸馏(学生模型):教师模型在面对难样本时,输出的分布本身就是平滑的(高熵)。学生模型通过 KL 散度模仿教师,学到的是“对这个样本保持不确定”,而不是“死记硬背这个词”。
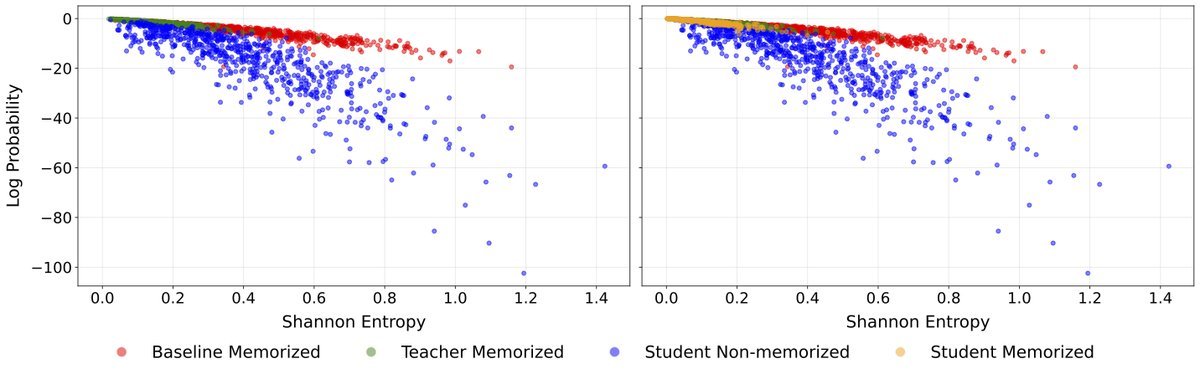
如上图所示,红色点(基线模型)中有大量高熵样本被赋予了极高的概率(强行记忆),而蓝色点(学生模型)则老老实实地保持了较低的置信度。
软蒸馏 vs. 硬蒸馏:谁更安全?
在实际应用中,我们有时拿不到教师模型的完整概率分布(Logits),只能拿到它生成的文本,这就是序列级蒸馏(Sequence-level KD,或称硬蒸馏)。
这就引出了一个关键问题:硬蒸馏安全吗?
研究发现,虽然软蒸馏(Logit-level)和硬蒸馏的总体记忆率差不多(都很低),但硬蒸馏的风险更大。
-
软蒸馏:通过概率分布传递知识,模糊了具体细节。
-
硬蒸馏:直接学习教师生成的文本。结果显示,硬蒸馏继承了 2.7 倍 于软蒸馏的“教师特有记忆”。
这意味着,如果你使用 GPT-4 生成的数据来训练小模型(硬蒸馏),你的小模型更有可能泄露 GPT-4 训练数据中的隐私片段。
总结
这篇论文为我们重新审视知识蒸馏提供了一个全新的视角。它不仅是提升小模型性能的利器,更是一种天然的隐私防御机制。
-
蒸馏即遗忘:相比微调,蒸馏能大幅减少对训练数据的死记硬背。
-
有的放矢:模型倾向于记忆那些“简单”的样本,而过滤掉复杂的长尾样本。
-
防患未然:我们可以通过简单的指标在训练前预测并剔除高风险数据。
-
警惕硬蒸馏:如果关注隐私,尽量使用包含 Logits 的软蒸馏,因为硬蒸馏更容易继承教师模型的“私货”。
在追求大模型落地的今天,利用好蒸馏的这一特性,或许能让我们在性能与安全之间找到更好的平衡点。