MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
告别微调!MemRL:用“记忆RL”让Agent在运行时实现自我进化

大模型(LLM)看似无所不知,但它们往往面临一个尴尬的困境:一旦训练完成,它们就停止了“学习”。
ArXiv URL:http://arxiv.org/abs/2601.03192v1
为了让 Agent 在部署后继续变强,传统的做法通常是微调(Fine-tuning)。但这不仅昂贵,还容易导致灾难性遗忘(Catastrophic Forgetting)——为了学会新技能,模型可能把旧知识忘得一干二净。另一种主流方案是 检索增强生成(Retrieval-Augmented Generation, RAG),它通过外挂知识库来补充信息。然而,RAG 往往是被动的:它只看检索内容和查询“像不像”(语义相似度),却不管这些内容到底“有没有用”。
如果 Agent 能像人类一样,不仅能回忆过去,还能根据过往经验的“成功率”来决定当下的策略,会发生什么?
今天要解读的论文 MemRL,提出了一种全新的框架:通过在情景记忆上进行非参数强化学习,实现 Agent 的自我进化。它不需要修改大模型的任何权重,却能让 Agent 在一次次试错中越来越聪明。
核心理念:不仅要“像”,更要“有用”
人类智能的一个标志是构建性情景模拟(Constructive Episodic Simulation):我们回忆过去的经历,不是为了简单复述,而是为了合成解决新问题的方案。更重要的是,我们会记住哪些经验是成功的,哪些是失败的。
MemRL 正是模仿了这一机制。它将 Agent 的能力解耦为两部分:
-
稳定的推理能力:由冻结的 LLM 提供,保证核心智商不掉线。
-
可塑的进化记忆:由动态的外部记忆模块提供,负责适应新任务。
这就好比给一个天才(LLM)配了一本会自己打分的笔记本(MemRL)。天才的大脑不需要动手术(不微调),只需要不断优化笔记本里的笔记权重即可。
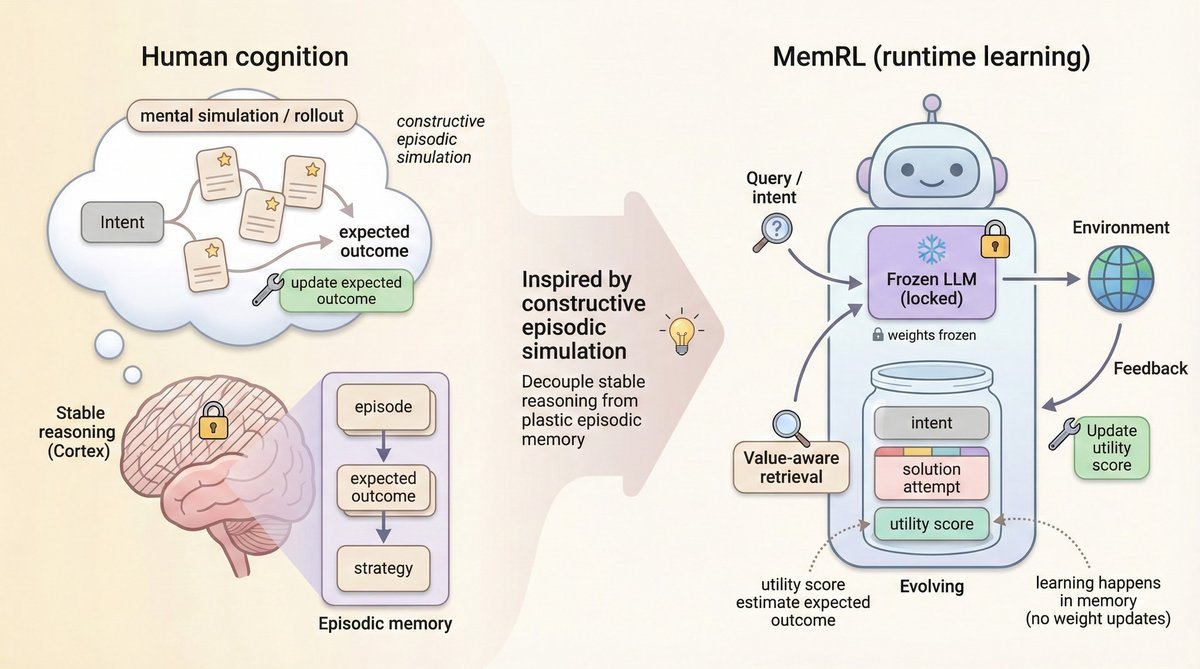
技术拆解:让记忆学会“打分”
MemRL 的核心创新在于将记忆检索建模为一个马尔可夫决策过程(Markov Decision Process, MDP)。它不再盲目相信语义相似度,而是引入了强化学习(Reinforcement Learning, RL)中的价值概念。
1. 记忆结构:意图-经验-效用三元组
传统的 RAG 存储的是 \((Key, Value)\) 对。而 MemRL 存储的是一个三元组:
\[\mathcal{M}=\{(z_{i},e_{i},Q_{i})\}_{i=1}^{ \mid \mathcal{M} \mid }\]-
$z_{i}$:意图嵌入(Intent Embedding),代表任务或查询的向量。
-
$e_{i}$:经验(Experience),比如一段成功的代码或推理路径。
-
$Q_{i}$:效用(Utility),这是一个可学习的 Q 值,代表这条经验在类似任务中获得成功的预期回报。
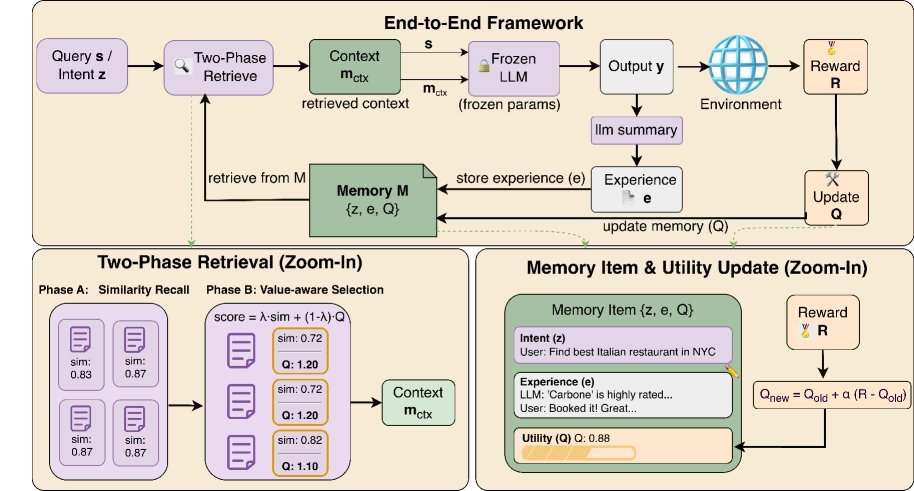
2. 两阶段检索:过滤噪声,锁定高价值
MemRL 并没有抛弃语义检索,而是将其作为第一步,形成了一个漏斗式的两阶段检索(Two-Phase Retrieval)机制:
-
阶段 A:基于相似度的召回(Similarity-Based Recall)
首先,利用余弦相似度从海量记忆中筛选出语义相关的候选集 $\mathcal{C}(s)$。这一步和传统 RAG 类似,目的是确保“相关性”。
-
阶段 B:价值感知选择(Value-Aware Selection)
这是 MemRL 的杀手锏。在候选集中,它不再只看相似度,而是结合相似度和 $Q$ 值进行综合打分:
\[\text{score}(s,z_{i},e_{i})=(1-\lambda)\cdot\hat{sim}(s,z_{i})+\lambda\cdot\hat{Q}(z_{i},e_{i})\]通过这个公式,MemRL 能够剔除那些“看着很像但实际上没用”的噪声经验(Distractors),优先选择那些历史上被证明能带来高回报的策略。
3. 运行时更新:非参数化的 RL
当 Agent 执行完任务后,环境会给出一个奖励信号 $r$(比如代码是否运行成功)。MemRL 会利用这个信号,通过类似蒙特卡洛方法的规则更新被选中记忆的 $Q$ 值:
\[Q_{\text{new}}\leftarrow Q_{\text{old}}+\alpha\big(r-Q_{\text{old}}\big)\]这是一个完全非参数化的过程。模型权重 $\theta$ 保持不变,变的是记忆库中的 $Q$ 值。这意味着 Agent 可以在运行时(Runtime)实时学习,无需停止服务去重新训练。
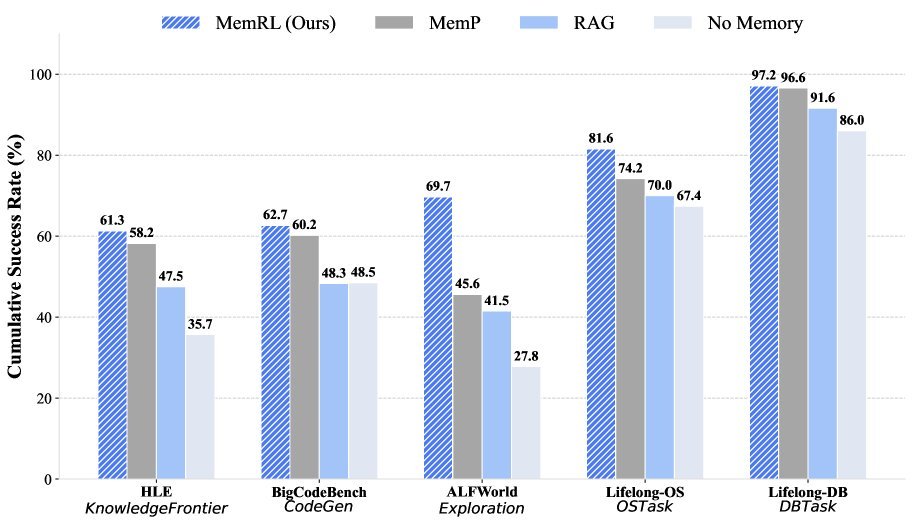
实验表现:在复杂任务中持续进化
研究团队在 HLE、BigCodeBench、ALFWorld 和 Lifelong Agent Bench 等多个高难度基准上测试了 MemRL。结果显示,MemRL 显著优于现有的记忆基线方法(如 MemP)和标准的 RAG 方法。
特别是在 Runtime Learning(运行时学习)的设定下,随着任务的进行,MemRL 的性能曲线呈现出明显的上升趋势,证明了它能够从过往的交互中有效汲取经验。
总结与展望
MemRL 巧妙地解决了 AI 领域的“稳定性-可塑性困境”(Stability-Plasticity Dilemma)。它通过模型-记忆解耦,让 LLM 保持稳定的推理能力,同时利用基于效用的记忆更新来实现灵活的适应能力。
这种方法不仅避免了微调带来的高昂成本和遗忘风险,更为 Agent 提供了一种在部署后持续自我进化的可行路径。未来的 Agent,或许不再需要频繁“回炉重造”,而是在每一次与世界的交互中,都能变得比上一秒更聪明一点。