Mesh-Attention: A New Communication-Efficient Distributed Attention with Improved Data Locality
挑战Ring-Attention霸主地位:Mesh-Attention实现3.4倍加速,通信暴降85%

在大模型(LLM)的“军备竞赛”中,上下文窗口(Context Window)的长度已经成为各大厂商争夺的制高点。从Gemini的100万token到Llama 4 Scout号称的1000万token,我们对模型处理超长文本、视频的需求似乎永无止境。
ArXiv URL:http://arxiv.org/abs/2512.20968v1
然而,理想很丰满,现实很骨感。随着上下文长度的增加,Attention(注意力机制)的计算量和显存需求呈二次方爆炸式增长。为了解决这个问题,分布式注意力(Distributed Attention)技术应运而生,其中最著名的莫过于 Ring-Attention。
但是,Ring-Attention 真的完美吗?在超大规模集群上,它正面临着严重的通信瓶颈。
今天我们要解读的这篇论文 Mesh-Attention,由字节跳动、普渡大学、清华大学和UIUC联合提出。它通过一种全新的二维“分块”视角,彻底重构了分布式注意力的设计空间。实验表明,在256个GPU的集群上,Mesh-Attention 相比 Ring-Attention 实现了 3.4倍的加速,并将通信量惊人地减少了 85.4%。
Ring-Attention 的“阿喀琉斯之踵”
要理解 Mesh-Attention 的强悍,我们先得看看它的前辈 Ring-Attention 是怎么工作的。
Ring-Attention 的核心思想是将长序列切分,让 KV(Key-Value)数据块在 GPU 之间像“转轮”一样传递。这在一定程度上解决了显存墙的问题。然而,这种设计有一个致命的弱点:通信量过大。
在 Ring-Attention 中,每个 GPU 虽然只负责一部分 Q(Query),但它需要“看见”所有的 KV 块才能完成计算。这意味着,随着序列长度的增加,通信量是线性增长的。
论文中的实验数据显示,在128个GPU上处理100万token长度时,Ring-Attention 竟然有 91.5% 的时间都在单纯等待通信,计算单元几乎处于“停工待料”的状态。这显然是不可接受的。
Mesh-Attention:从一维“环”到二维“网”
Mesh-Attention 的核心洞察在于:为什么我们只能按行(Row)或者按列(Column)来切分计算任务?
作者提出了一种基于 矩阵模型(Matrix-based Model) 的新视角。如果我们将 Attention 的计算看作一个巨大的矩阵(行是 Q,列是 KV),Ring-Attention 实际上是将这个矩阵按行切分给了不同的 GPU。
Mesh-Attention 提出:不如给每个 GPU 分配一个 二维图块(Tile)。
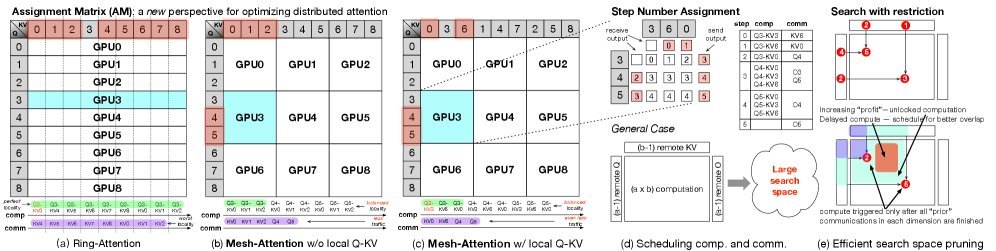
如上图所示:
-
(a) Ring-Attention: 每个 GPU 负责一行。它不需要传输 Q,但需要接收所有的远程 KV。这导致了极高的通信-计算比(CommCom ratio)。
-
(b) Mesh-Attention: 每个 GPU 负责一个方形的 Tile(例如 3x3)。这样,每个 GPU 只需要和同行、同列的少数几个 GPU 通信。
这种二维切分带来的好处是立竿见影的:通信复杂度从 $O(N)$ 降低到了 $O(\sqrt{N})$(其中 $N$ 是 GPU 数量)。
为了进一步压榨性能,Mesh-Attention 还引入了一个巧妙的 索引旋转(Index Rotation) 机制(如上图 c 所示)。通过调整 KV 块的分配顺序,确保每个 GPU 尽可能多地处理“本地”数据(即 Q 和 KV 都在本地显存中),从而进一步减少了不必要的网络传输。
贪心算法:寻找最优的“流水线”
减少通信量只是第一步,如何让“计算”和“通信”完美重叠(Overlap),才是分布式训练的精髓。
在 Ring-Attention 中,调度相对简单:算一步,传一步。但在 Mesh-Attention 中,每个 GPU 需要接收来自不同方向的 Q、KV 以及部分输出结果,调度空间呈指数级爆炸。
为了解决这个问题,论文提出了一种 贪心调度算法(Greedy Algorithm)。
这个算法的核心逻辑非常直观:
-
最大化解锁计算:在选择下一步进行哪个通信操作时,优先选择那个能“解锁”最多计算块的通信。
-
适度延迟计算:不要一有数据就马上计算,而是将部分计算任务“攒”在手里,用来填补未来可能出现的通信等待时间。
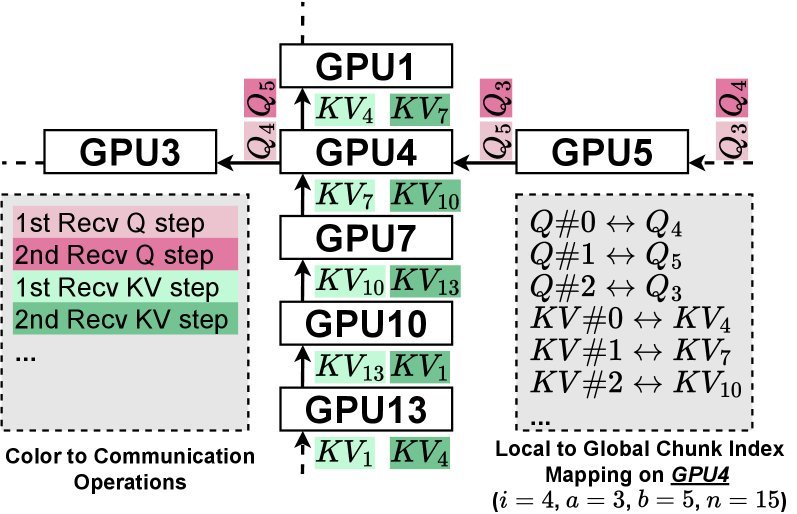
通过这种策略,Mesh-Attention 能够在复杂的通信模式下,依然保持极高的流水线效率,让 GPU 始终处于忙碌状态。
实验结果:全面碾压
研究团队在拥有 256 个 GPU 的集群上进行了广泛的测试。结果显示,Mesh-Attention 的优势是压倒性的:
-
速度飞跃:相比 Ring-Attention,Mesh-Attention 实现了平均 2.9倍,最高 3.4倍 的端到端加速。
-
通信暴降:通信数据量平均减少 79.0%,最高减少 85.4%。
-
极佳的可扩展性:在强扩展性测试中,当 GPU 数量增加到 128 个时,Ring-Attention 的性能开始剧烈下降(因为通信开销超过了计算收益),而 Mesh-Attention 依然保持了良好的线性加速比。
总结
Mesh-Attention 的出现,标志着分布式 Attention 机制从“一维流”向“二维网”的范式转变。
通过重新思考数据切分方式,并配合高效的贪心调度算法,Mesh-Attention 成功打破了长上下文训练中的通信墙。对于那些致力于训练千万级甚至亿级 token 上下文模型的团队来说,这无疑是一项激动人心的技术突破。
随着 AI 模型向着更大规模、更长上下文演进,类似 Mesh-Attention 这样对底层系统架构的极致优化,将成为决定模型性能上限的关键。