MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
MetaClaw:AI Agent的在职进化论,准确率从21.4%飙升至40.6%

你是否曾感到沮丧,你的AI助手虽然聪明,却似乎从不吸取教训?今天你纠正了它的一个错误,明天它可能在同样的地方再次跌倒。这种“静态智能”是当前AI Agent在处理复杂、多变任务时的一大瓶颈。
ArXiv URL:http://arxiv.org/abs/2603.17187v1
但如果,一个Agent可以在为你工作的同时,不断学习、自我进化,甚至不需要停机更新呢?
来自卡内基梅隆大学、加州大学伯克利分校等顶尖机构的最新研究 MetaClaw,就将这个设想变为了现实。该研究提出了一个创新的持续元学习框架,让AI Agent能在真实使用场景中“边干边学”。
通过一套巧妙的双速进化机制,MetaClaw能让基于Kimi的Agent在基准测试中的准确率,从21.4%一举跃升至40.6%,几乎翻了一番!
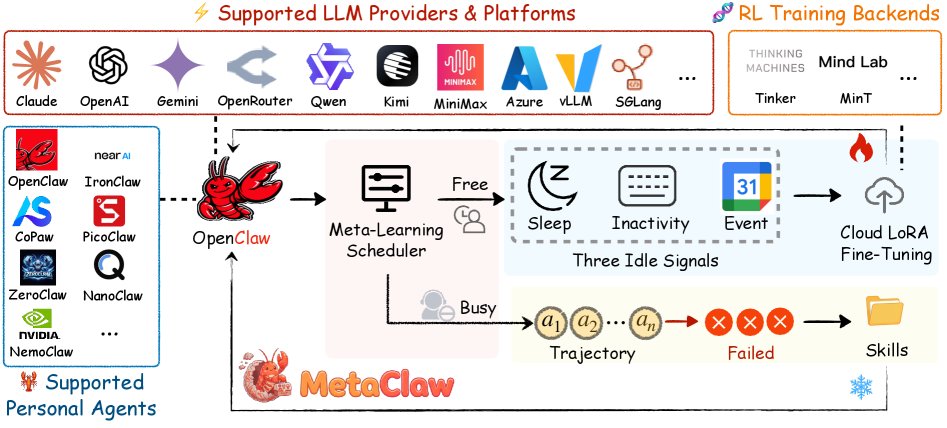
图1: MetaClaw框架通过两个不同时间尺度的互补循环来提升模型。
静态Agent的困境
当前部署的LLM Agent大多是“一次性训练,永久服务”的模式。然而,真实世界用户的需求是动态变化的。这周你可能需要它处理文件系统操作,下周就变成了多Agent协作。一个固化的模型很快就会与实际使用模式脱节,在新的任务类型上屡屡碰壁。
现有的解决方案各有短板:
-
记忆方法:存储原始对话历史,但信息冗余,难以提炼出可迁移的行为模式。
-
技能库方法:将经验压缩成可复用的指令,但技能库通常是静态的,与模型权重优化脱节。
-
强化学习方法:可以更新模型权重,但通常需要服务中断来进行再训练,并且面临一个棘手问题:当Agent学会新技能后,旧的经验数据可能已经“过时”,会污染训练过程。
有没有一种方法,能集各家之所长,让Agent既能即时学习,又能深度优化,还不用打扰用户呢?
MetaClaw的双速进化引擎
MetaClaw的核心思想是:将Agent的进化分为两种速度,并让它们相辅相成。
研究者将Agent的能力定义为一个元模型(meta-model):$ \mathcal{M}=(\theta,\mathcal{S}) $。
其中,$ \theta $ 代表了LLM本身的模型权重(策略),决定了其基础能力;而 $ \mathcal{S} $ 则是一个不断演进的技能库(行为指令),存储了从经验中提炼出的操作技巧。
MetaClaw通过两个循环来共同优化这两部分:
1. 技能驱动的快速适应 (Skill-driven Fast Adaptation)
这就像人类从错误中秒级学会一个“小窍门”。
当Agent执行任务失败时,一个LLM进化器(LLM evolver)会分析失败的轨迹,并自动合成一条新的、可复用的自然语言技能。
比如,Agent因为直接读取一个不存在的文件而失败,它可能会学到一条新技能:“在读取文件前,务必先验证其路径是否存在。”
这条新技能会立刻被添加到技能库 $ \mathcal{S} $ 中,并在下一次任务中生效。整个过程是无梯度(gradient-free)的,意味着它不触及模型权重,因此可以实现零停机(zero downtime)的即时改进。
2. 机会主义的策略优化 (Opportunistic Policy Optimization)
这更像是系统性的深度复盘和训练。
在学会新技能后,Agent会继续执行任务,并收集更多成功的经验轨迹。这些轨迹因为是在新技能指导下产生的,质量更高。
关键来了:MetaClaw不会立即用这些数据训练模型,而是等待“机会”。通过一个名为机会主义元学习调度器(Opportunistic Meta-Learning Scheduler, OMLS)的组件,系统会监测用户的空闲信号,例如:
-
用户设定的睡眠时间。
-
系统键盘长时间无活动。
-
Google Calendar上的会议或休息时段。
一旦检测到用户处于空闲状态,OMLS就会自动触发策略优化。它会利用云端的LoRA微调技术,通过强化学习(具体为RL-PRM)来更新模型的核心权重 $ \theta $。
两大协同机制:进化得以持续的关键
MetaClaw的精妙之处在于,上述两个循环并非各自为战,而是形成了一个强大的良性循环:
-
更优的策略(来自慢优化)能产生信息量更丰富的失败案例,为技能合成(快适应)提供更好的素材。
-
更丰富的技能(来自快适应)能指导Agent产生更高质量、更高回报的成功轨迹,为策略优化提供更优质的训练数据。
通过这种方式,Agent不仅在学习解决任务,更是在学习如何更好地去适应,这正是“元学习”的精髓。
为了保证这个循环的纯洁性,MetaClaw还引入了技能生成版本控制(Skill Generation Versioning)机制。它严格区分了两种数据:
-
支持数据(Support Data):导致技能产生的失败轨迹。
-
查询数据(Query Data):在新技能生效后收集的轨迹。
只有“查询数据”才会被用于策略优化。每当技能库更新时,旧版本数据就会被清空,从而避免了“用昨天的经验来指导今天的训练”这种“数据污染”问题。
实验效果:数据不说谎
为了验证MetaClaw的真实能力,研究团队构建了一个全新的基准测试 MetaClaw-Bench。它模拟了长达44个工作日的连续任务流,更能反映真实世界中Agent的持续适应能力。
实验结果非常亮眼:
-
整体性能飞跃:在Kimi-K2.5模型上,完整的MetaClaw框架将端到端任务准确率从 21.4% 提升至 40.6%。
-
快速适应的威力:仅使用“技能驱动的快速适应”,就能带来高达 32% 的相对准确率提升。
-
持续学习能力:如下图所示,随着时间的推移(模拟工作日增加),任务难度不断上升,但MetaClaw(蓝色和绿色实线)相较于基线模型(虚线),能更好地维持其性能,尤其在任务复杂度中等的阶段(day11-22)优势最为明显。
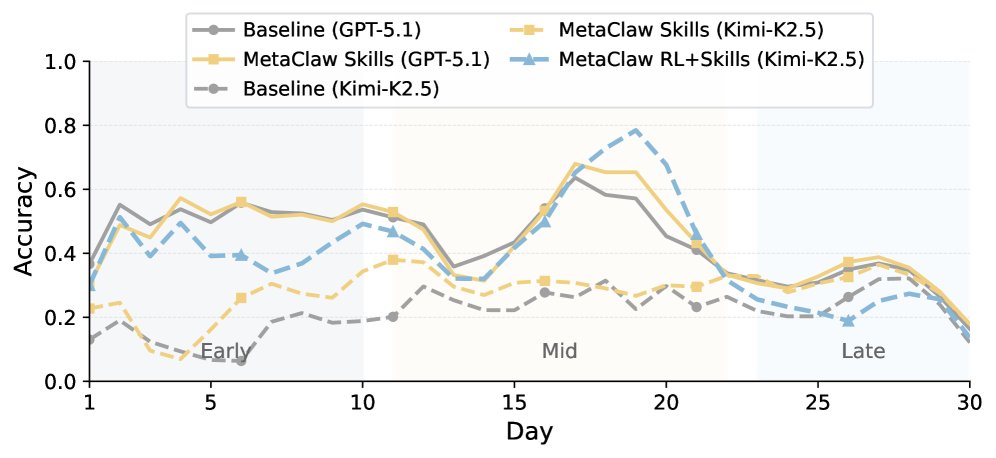
图2: 在MetaClaw-Bench上,MetaClaw(实线)相较于基线(虚线)展现出更强的持续适应能力。
此外,在另一个名为 AutoResearchClaw 的23阶段自主研究流水线任务中,仅仅注入MetaClaw的技能学习机制,就让系统的综合鲁棒性提升了 18.3%,证明了其在复杂、开放式任务中的泛化能力。
结论
MetaClaw为我们描绘了一幅激动人心的未来图景:AI Agent不再是出厂后就一成不变的工具,而是能够在使用中与我们共同成长的智能伙伴。
它通过一个优雅的双速学习框架,将即时的、无停机的“小步快跑”(技能学习)与深度的、伺机而动的“策略迭代”(权重优化)完美结合。最重要的是,这套系统建立在轻量级的代理架构上,无需本地GPU即可运行,为在个人设备上部署自进化Agent铺平了道路。
当然,该框架目前依赖用户配置来检测空闲窗口。但无论如何,MetaClaw无疑为构建真正能在“荒野”中生存和进化的AI Agent,奠定了坚实而有启发性的基础。