mHC: Manifold-Constrained Hyper-Connections
DeepSeek魔改残差连接:mHC仅增6.7%开销,完美驯服大模型训练不稳定性

在过去十年里,深度学习架构的每一次飞跃,几乎都离不开一个核心组件——残差连接(Residual Connection)。从ResNet到Transformer,再到如今的LLM(如Llama、DeepSeek-V3),公式 $\mathbf{x} + \mathcal{F}(\mathbf{x})$ 简直就是现代AI的“地基”。
ArXiv URL:http://arxiv.org/abs/2512.24880v1
但是,这个地基真的完美无缺吗?
最近,DeepSeek-AI团队发布了一项引人注目的研究——流形约束超连接(Manifold-Constrained Hyper-Connections, mHC)。这项技术直面了当前大模型架构设计中的一个核心矛盾:如何在增加网络拓扑复杂度的同时,保证大规模训练的绝对稳定?
DeepSeek给出的答案既优雅又硬核:通过数学上的“流形投影”来驯服狂野的参数,再配合极致的系统级优化,最终在仅增加6.7%训练开销的情况下,实现了更强的性能和扩展性。
为什么要动“残差连接”?
在经典的Transformer架构中,残差连接的形式非常简洁:信号无损地从浅层传递到深层。这种“恒等映射”(Identity Mapping)属性是训练深层网络不发生梯度消失或爆炸的关键。
然而,研究人员发现,简单的相加可能限制了信息的交互能力。于是,超连接(Hyper-Connections, HC)应运而生。
如图1(b)所示,HC通过将残差流的宽度扩展 $n$ 倍,并引入可学习的矩阵($\mathcal{H}^{\mathrm{res}}$)来混合不同流之间的特征。这就好比把原来的单车道扩建成了多车道高速公路,并且允许车辆在车道间自由变道。
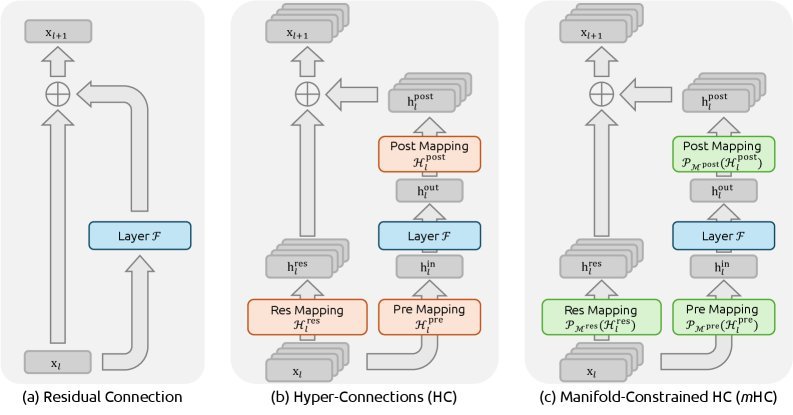
但问题随之而来: 这种“自由变道”是完全不受控的。
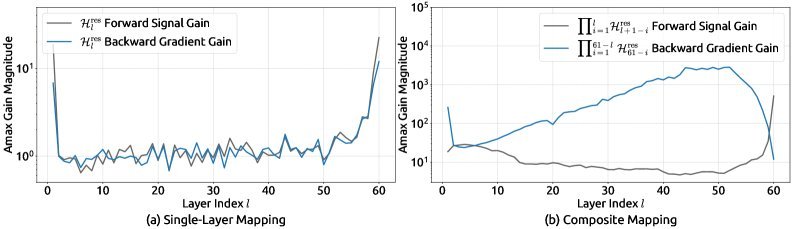
在HC中,随着层数的叠加,信号经过无数个矩阵 $\mathcal{H}^{\mathrm{res}}$ 的连乘,原本的“恒等映射”属性被破坏了。这会导致信号强度在深层网络中要么指数级爆炸,要么消失殆尽(如图3所示),从而引发严重的训练不稳定。此外,变宽的通道也带来了巨大的显存访问(I/O)压力,撞上了著名的“内存墙”。
DeepSeek的解法:给矩阵戴上“流形”的镣铐
DeepSeek提出的 mHC(图1(c)),核心思想非常直观:既然HC破坏了恒等映射,那我们就用数学手段把它强制找回来。
他们没有简单地把矩阵设为单位阵(那样就退回去了),而是将残差连接矩阵 $\mathcal{H}^{\mathrm{res}}$ 投影到一个特殊的流形上——双随机矩阵(Doubly Stochastic Matrices)构成的Birkhoff多胞形。
什么是双随机矩阵?
简单来说,这种矩阵满足三个条件:
-
所有元素非负。
-
每一行的和为1。
-
每一列的和为1。
这就好比在进行特征混合时,严格遵守“能量守恒定律”:输入信号的总能量被均匀地分配和重组,既不会凭空增加,也不会无故消失。
为了实现这一点,DeepSeek引入了经典的 Sinkhorn-Knopp 算法。在每次前向传播时,通过几次迭代,将任意的 $\mathcal{H}^{\mathrm{res}}$ 矩阵“拉”回到这个流形上。
这样做的好处是立竿见影的:
-
恢复了恒等映射属性:双随机矩阵的乘积依然是双随机矩阵,这意味着无论网络多深,信号的均值和范数都能保持稳定。
-
保留了表达能力:相比于死板的单位阵,在这个流形上的矩阵依然允许特征在不同流之间进行复杂的交互。
极致的系统优化:打破“内存墙”
理论上的优雅往往伴随着工程上的噩梦。mHC引入了更宽的残差流($n$ 倍宽度)和额外的投影计算,如果直接实现,训练速度会大打折扣。
DeepSeek团队展示了他们深厚的系统功底,通过一系列“基建优化”解决了这个问题:
-
算子融合(Kernel Fusion):利用 TileLang 开发了定制化算子,将RMSNorm、线性投影和流形约束计算融合在一起,大幅减少了对显存的读写次数。
-
重计算(Recomputing):为了节省显存,前向传播时不存储中间激活值,而是在反向传播时重新计算。他们巧妙地选择了重计算的层数块大小 $L_r$,与流水线并行的阶段边界对齐。
-
DualPipe中的通信重叠:在DeepSeek-V3使用的DualPipe流水线并行策略基础上,mHC进一步优化了调度(如图4)。通过将MLP层的计算放在高优先级流上,并允许注意力计算被抢占,成功掩盖了mHC带来的额外通信延迟。

总结
mHC 是对现有大模型基础架构的一次精彩修正。它并没有盲目追求复杂度的增加,而是敏锐地捕捉到了“数值稳定性”这一痛点。
通过将数学上的流形约束与底层的系统工程相结合,DeepSeek证明了:我们完全可以在享受更宽、更复杂网络拓扑带来的性能红利的同时,依然保持如ResNet般如丝顺滑的训练体验。
实验数据显示,在扩展率 $n=4$ 的情况下,mHC仅带来了 6.7% 的额外时间开销,却换来了卓越的扩展性和稳定性。对于正在探索万亿参数模型架构的研究者来说,这无疑指明了一个极具潜力的进化方向。