MiMo-V2-Flash Technical Report
仅15B激活参数硬刚DeepSeek!MiMo-V2-Flash揭秘:混合注意力与多教师蒸馏的极致效率

在通往AGI的赛道上,推理能力(Reasoning)和智能体(Agent)工作流已成为两大核心驱动力。然而,构建能够处理超长上下文、同时保持极快响应速度的模型,始终是一个巨大的挑战。通常情况下,高性能意味着巨大的参数量和昂贵的推理成本。
ArXiv URL:http://arxiv.org/abs/2601.02780v1
MiMo-V2-Flash 的出现打破了这一僵局。这款由小米团队推出的新模型,虽然拥有309B的总参数量,但每次推理仅激活 15B参数。更令人惊讶的是,它在推理和智能体能力上竟能与DeepSeek-V3.2和Kimi-K2等顶级开源模型分庭抗礼,而参数量仅为它们的1/2甚至1/3。本文将深入剖析其背后的三大技术杀手锏:混合注意力机制、多Token预测以及创新的多教师蒸馏范式。
架构之美:混合注意力与MoE的精妙共舞
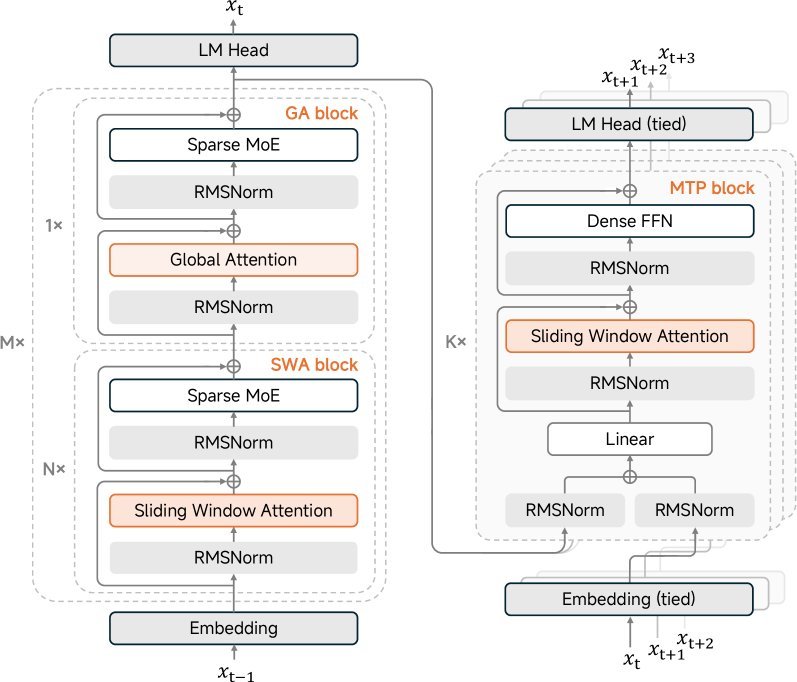
MiMo-V2-Flash的核心架构基于Transformer,但引入了混合专家(Mixture-of-Experts, MoE)和混合注意力机制(Hybrid Attention)的强力组合。
为了解决长文本处理中KV缓存和计算量的二次方增长问题,该模型并没有采用全全局注意力,而是采用了一种激进的策略:滑动窗口注意力(Sliding Window Attention, SWA)与全局注意力(Global Attention, GA)交替使用。
具体来说,模型采用了5:1的混合比例(每5层SWA后接1层GA),且滑动窗口大小仅为128个Token。这种设计将长上下文的KV缓存存储和注意力计算量减少了近6倍。
你可能会问,如此小的窗口(128 Token)是否会丢失长距离依赖?
研究团队引入了可学习的注意力汇聚偏置(Learnable Attention Sink Bias)。实验发现,这种偏置机制能够显著增强SWA架构的建模能力。即便是在极端的长上下文推理任务(如GSM-Infinite)中,MiMo-V2-Flash从16K扩展到128K上下文时,性能也几乎没有衰减。这种设计迫使模型专注于局部信息,同时将长距离依赖“外包”给全局注意力层,实现了更清晰的分工。
速度为王:多Token预测带来的2.6倍加速
除了架构上的精简,MiMo-V2-Flash在训练和推理速度上也下足了功夫。它采用了多Token预测(Multi-Token Prediction, MTP)技术。
在预训练阶段,MTP通过预测未来的多个Token来增强模型的训练效率和质量。而在推理阶段,这一模块被巧妙地“再利用”——作为投机采样(Speculative Decoding)的草稿模型(Draft Model)。
由于MTP模块设计得非常轻量(使用密集的FFN而非MoE,且仅使用SWA),它不会成为推理的瓶颈。实验数据显示,利用三层MTP进行投机解码,MiMo-V2-Flash实现了高达3.6的接受长度,整体解码速度提升了 2.6倍。这对于需要大量推理步骤的强化学习(RL)训练来说,无疑是一个巨大的加速器。
训练新范式:多教师在线蒸馏(MOPD)
如果说架构是骨架,那么训练策略就是灵魂。MiMo-V2-Flash提出了一种全新的后训练范式:多教师在线蒸馏(Multi-Teacher On-Policy Distillation, MOPD)。
传统的RLHF通常依赖单一的奖励模型,容易导致能力不平衡。MOPD则采用了一个三阶段的过程:
-
监督微调(SFT):建立基础的指令遵循能力。
-
领域专业化训练:针对代码、数学、智能体等不同领域,分别训练专门的“教师模型”。这些教师模型在各自领域内通过大规模RL达到了顶尖水平。
-
多教师在线蒸馏:这是最关键的一步。学生模型(MiMo-V2-Flash)在训练时,不仅接收最终结果的奖励,还同时接收来自各领域教师模型的密集Token级奖励。
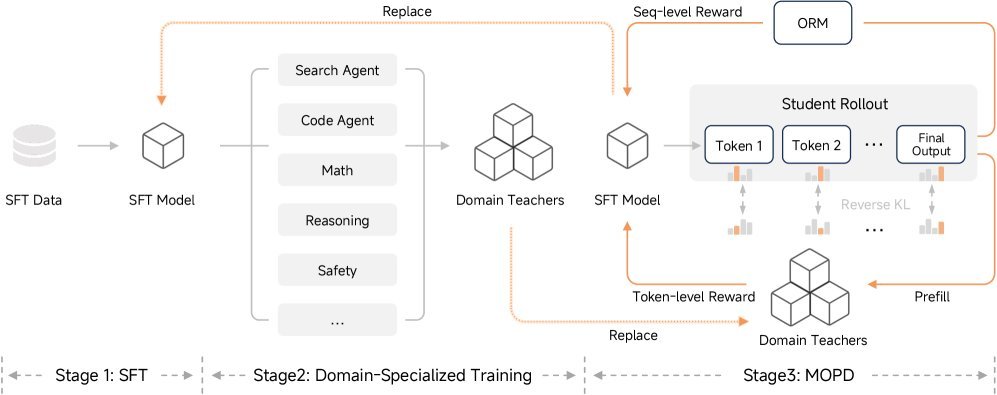
这种方法让模型能够同时汲取多个“专家”的精华,既掌握了特定领域的深度知识(如复杂的代码Debug),又保持了通用的对话能力,避免了传统模型合并带来的性能损失。
总结与展望
MiMo-V2-Flash展示了一条高效构建高性能LLM的新路径。它证明了通过极致的架构优化(混合SWA+MoE)和创新的训练范式(MOPD),中等规模的模型完全可以挑战巨头。
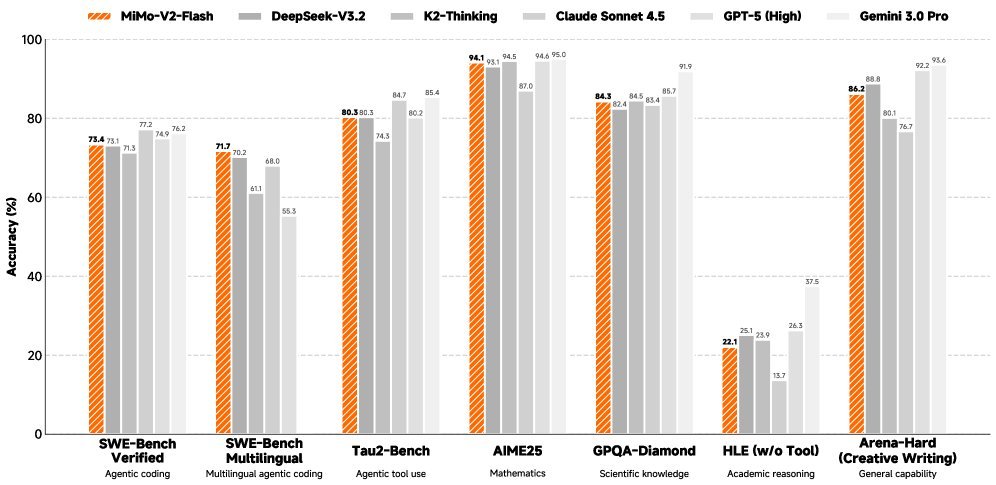
在性能上,它在SWE-Bench Verified上达到了73.4%的胜率,确立了其在软件工程任务中的领先地位。同时,其权重的开源(包括3层MTP权重)也为社区研究高效推理和长文本处理提供了宝贵的资源。对于那些渴望在有限算力下实现强推理和Agent能力的应用来说,MiMo-V2-Flash无疑是一个极具吸引力的选择。