Mixture-of-Depths Attention
LLM越深越“健忘”?字节MoDA架构:性能+2.11%,开销仅3.7%

大模型(LLM)的竞赛似乎很简单:堆更多的层,模型就会更强大。但现实却给了我们一记重拳——模型越深,反而越容易“忘记”浅层学到的关键信息。这种现象被称为信号衰减(signal degradation)。
ArXiv URL:http://arxiv.org/abs/2603.15619v1
每一层网络都在努力学习,但随着层层堆叠,有价值的特征信号在反复的残差更新中被稀释,导致深层网络难以有效利用浅层信息。
为了解决这个“健忘症”,来自字节跳动和华中科技大学的研究者们提出了一个全新的注意力机制:深度混合注意力(Mixture-of-Depths Attention, MoDA)。它让模型在处理当前序列信息的同时,还能“回头看”,动态地从前面所有层中提取最有用的信息。
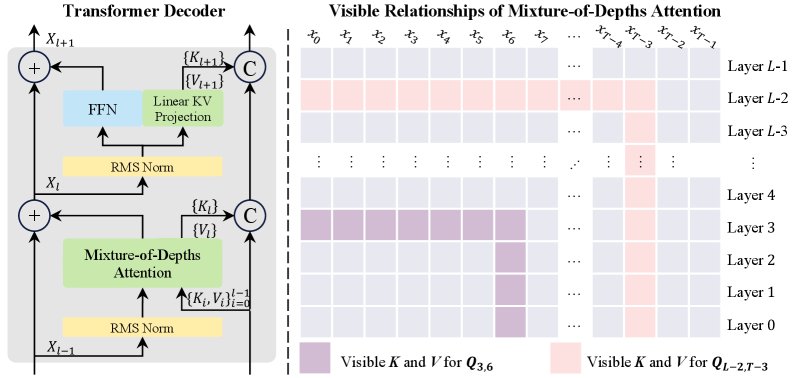
图1:MoDA允许Query在关注当前层序列KV对的同时,也关注来自前面所有层的深度KV对。
结果如何?在1.5B参数模型上,MoDA仅用3.7%的额外计算开销,就将下游任务平均性能提升了2.11%,困惑度(Perplexity)降低0.2。这证明了,让模型“温故知新”是一种极具潜力的深度扩展策略。
信号衰减:LLM加深的“拦路虎”
要理解MoDA的巧妙之处,我们先得看看模型加深时会遇到什么问题。
目前主流的Transformer架构通过残差连接(Residual Connection)来构建深层网络。这种方式虽然缓解了梯度消失问题,但它将所有历史信息都压缩进了一个单一的隐藏状态流中。
这就好比玩“传话游戏”,信息每经过一个人(一层网络),都可能发生微小的失真或丢失。层数一多,最初的“悄悄话”就可能面目全非了。
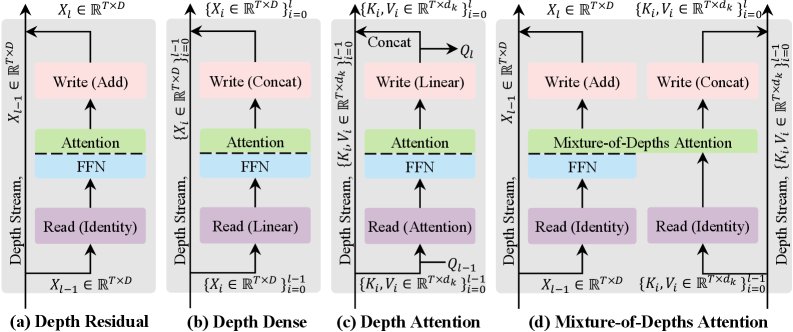
图3:(a) 标准残差连接;(b) DenseNet式的密集连接,计算开销大;(c) 深度注意力,只关注历史KV;(d) MoDA,统一处理序列和深度信息。
过去的一些方法,如密集连接(Dense Connection),尝试让每一层都连接到之前的所有层。这虽然保留了更丰富的历史信息,但参数量和计算量会随着深度呈二次方增长,对于动辄上百层的LLM来说,成本高到无法接受。
MoDA则提供了一个更优雅的平衡点:它不采用固定的密集连接,而是引入了注意力的思想,让模型以一种数据依赖的方式,动态地“读取”历史层的知识。
MoDA:统一序列与深度的注意力机制
MoDA的核心思想非常直观:将注意力的作用范围从“横向”(序列长度)扩展到“纵向”(网络深度)。
在标准的自注意力机制中,一个Token的Query只会与当前层所有Token的Key进行计算。而在MoDA中,每个Query不仅会关注当前层的序列KV对(Sequence KV pairs),还会同时关注所有前面层的深度KV对(Depth KV pairs)。
这意味着,在第 $l$ 层,注意力机制的计算对象变成了:
\[\text{Attention}(Q_l, \text{Concat}(\text{SequenceKV}_l, \text{DepthKV}_{0..l-1}))\]通过一个统一的 $softmax$ 操作,模型可以自主决定在当前位置,是更依赖于序列中的其他Token,还是更需要从过去的某一层中“复习”一下旧知识。
这种设计巧妙地解决了信息稀释问题,因为它为信息流动开辟了一条“直达快车道”,让深层网络可以直接访问和利用浅层提取的原始特征。
硬件感知设计:让MoDA快如闪电
一个好的想法如果不能高效实现,也只能停留在纸面上。直接用PyTorch实现MoDA,会因为对历史KV缓存的非连续内存访问而导致GPU利用率极低。
为了让MoDA在实际训练中跑得起来,研究者们设计了一套硬件感知的高效算法(hardware-aware efficient algorithm)。
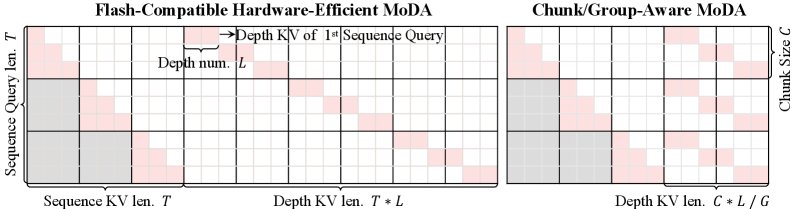
图4:通过分块(Chunk-aware)和分组(Group-aware)优化,MoDA大幅提升了深度KV缓存的访问效率。
这个算法主要包含三项关键优化:
-
Flash兼容的KV布局:将所有历史层的深度KV缓存“展平”,变成一个连续的内存块。这使得原本零散的内存读取操作,变成了GPU最高效的块读取模式。
-
分块感知的KV布局:将Query按块处理,并重新组织深度KV的存储顺序,使得每个计算块需要访问的深度数据范围大幅缩小。
-
分组感知的索引计算:在分组查询注意力(Grouped Query Attention, GQA)的基础上,让共享相同KV头的多个Query组能够复用深度KV的计算结果,进一步减少冗余计算。
这一系列优化效果惊人。在64K的长序列下,MoDA的效率达到了FlashAttention-2的97.3%。与朴素实现相比,优化后的MoDA在端到端(前向+后向)计算中取得了约1458倍的惊人加速!
实验效果:全面超越基线
口说无凭,实验为证。研究者在7亿和15亿参数规模的模型上,使用与OLMo2模型相同的400B Token数据进行了训练和对比。
性能稳定提升
在1.5B模型规模下,与强大的开源基线OLMo2相比,MoDA在10个下游任务上的平均性能提升了2.11%,并在10个验证集上的平均困惑度降低了0.2。

图2:在1.5B参数规模下,MoDA在C4验证集以及多个下游任务上均优于OLMo2基线。
无论是在常识推理(如HellaSwag, WinoGrande)还是在更具挑战性的科学问答(如ARC-C)任务上,MoDA都展现出了一致且显著的优势。
深度注意力真的在起作用吗?
通过可视化注意力热力图,我们可以直观地看到MoDA是如何工作的。
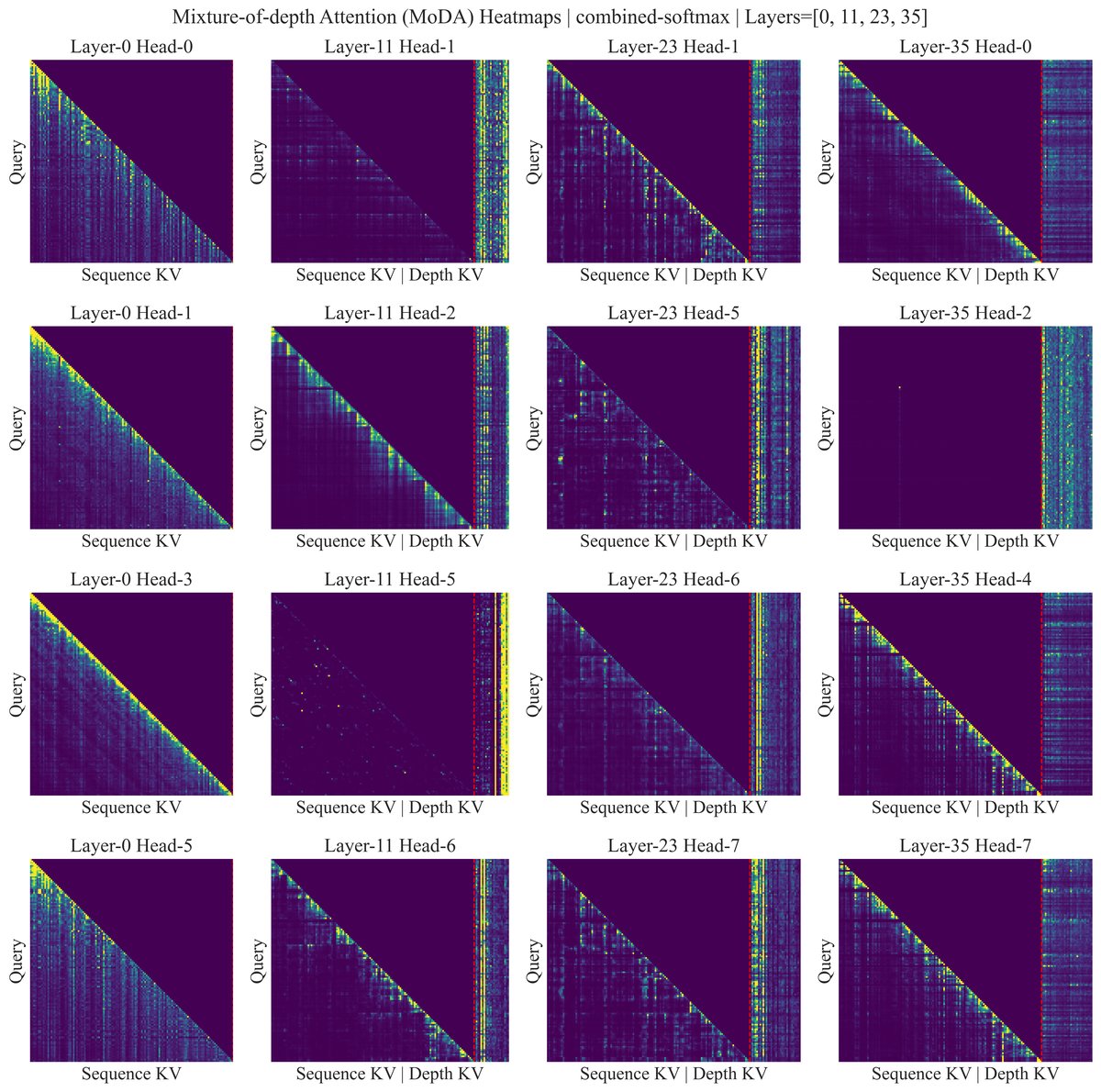
图5:注意力热力图。红色虚线右侧是深度KV区域。可以看到,模型在不同层、不同头都分配了相当大的注意力权重给深度信息,证明MoDA确实在有效利用历史层知识。
从图中可以清晰地看到,在序列KV和深度KV的拼接空间中,模型将大量的注意力权重分配给了深度KV部分(图中红色虚线右侧区域)。这有力地证明了,模型确实学会了从历史层中检索信息来辅助当前决策。
结论
面对LLM深度扩展带来的“信号衰减”难题,MoDA提供了一个既有效又高效的解决方案。它通过一个统一的注意力机制,让模型能够动态地混合序列信息和深度信息,打破了层间信息传递的壁垒。
更重要的是,通过精巧的硬件感知设计,MoDA在带来显著性能提升的同时,几乎没有增加额外的推理延迟,计算开销也微乎其微。
这项研究表明,显式地从历史层中检索信息,是扩展Transformer深度的一条极具前景的道路。MoDA作为一个即插即用的架构组件,未来不仅可以用于构建更强大的语言模型,也有望在多模态、视觉理解等领域发挥重要作用。