Meta MobileLLM-Pro:10亿参数手机模型称王,四大创新超越Gemma与Llama 3.2
当强大的AI模型还在云端服务器上运筹帷幄时,一场变革正在我们的掌上设备中悄然发生。然而,让AI在手机上流畅运行,始终面临一个棘手的难题:大模型太笨重,小模型又不够聪明。
论文标题:MobileLLM-Pro Technical Report ArXiv URL:http://arxiv.org/abs/2511.06719v1
Meta Reality Labs最新的研究成果 MobileLLM-Pro,正是为了打破这一僵局而来。它是一个仅有10亿参数的轻量级语言模型,却在11项标准基准测试中,显著超越了Google的Gemma 3-1B和Meta自家的Llama 3.2-1B。
更惊人的是,它支持高达128K的上下文窗口,并在4-bit量化后,性能几乎没有衰减。这一切是如何实现的?答案藏在 MobileLLM-Pro 的四大核心创新之中。
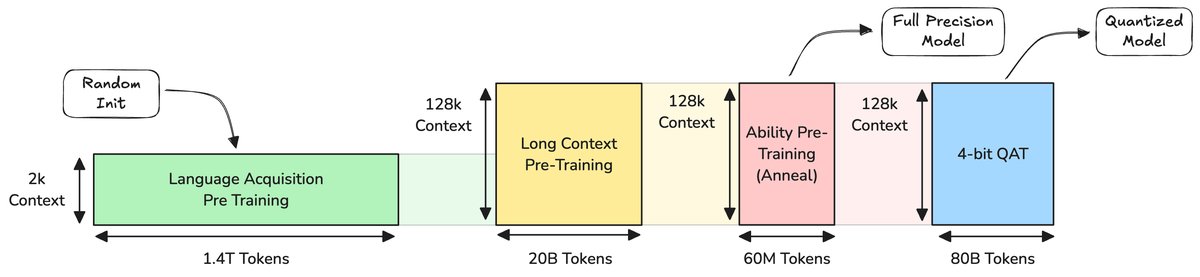
核心架构:小身材,大容量
MobileLLM-Pro的“骨架”基于成熟的Transformer架构,并借鉴了Llama系列的设计精髓。虽然只有10亿参数,但它拥有与Llama 4等前沿模型相同的202,048个词汇表,通过嵌入层共享(embedding sharing)技术,节省了约2.6亿参数。
为了在端侧设备上高效处理128K长文本,该研究采用了局部-全局注意力(Local-Global Attention)机制。模型大部分层使用滑动窗口为512个token的局部注意力,仅在少数关键层(每隔3层)使用全局注意力,从而在计算效率和长上下文能力之间取得了绝佳平衡。
创新一:隐式位置蒸馏,巧学长文本
传统模型要学会处理长文本,通常需要“投喂”大量长序列数据。但这不仅计算成本高昂,还容易导致模型在学习新位置信息时,忘记已有的知识。
MobileLLM-Pro提出了一种名为隐式位置蒸馏(implicit positional distillation)的全新技术。
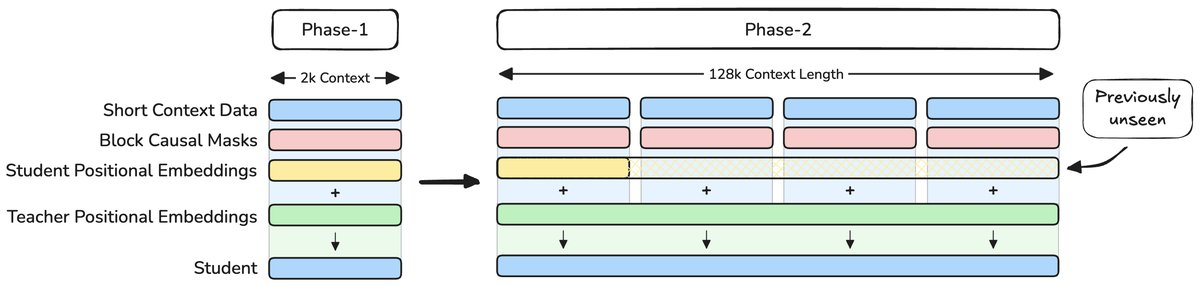
它的核心思想是:让一个看过128K长文本的强大教师模型(Llama 4-Scout),将长距离依赖关系和位置理解能力,“蒸馏”提炼出来,再传授给学生模型(MobileLLM-Pro)。整个过程中,学生模型根本不需要看到完整的长文本数据。
这就好比一位经验丰富的导师,不需要让学生完整阅读一部巨著,而是通过讲解书中关键章节的关联,就能让学生领悟整本书的脉络。这种方法巧妙地扩展了模型的上下文能力,同时避免了从短文本到长文本训练时的分布剧变问题。
创新二:专家模型融合,不增参数能力更强
为了让小模型变得“博学多才”,研究者们通常会在训练数据中混合代码、推理、知识等不同领域的内容。但这可能导致不同能力在训练中相互“竞争”和干扰。
MobileLLM-Pro采用了专家模型融合(Specialist Model Merging)策略。在预训练的最后阶段,他们基于同一个模型检查点,并行训练出多个“领域专家”,比如一个编码专家、一个推理专家。
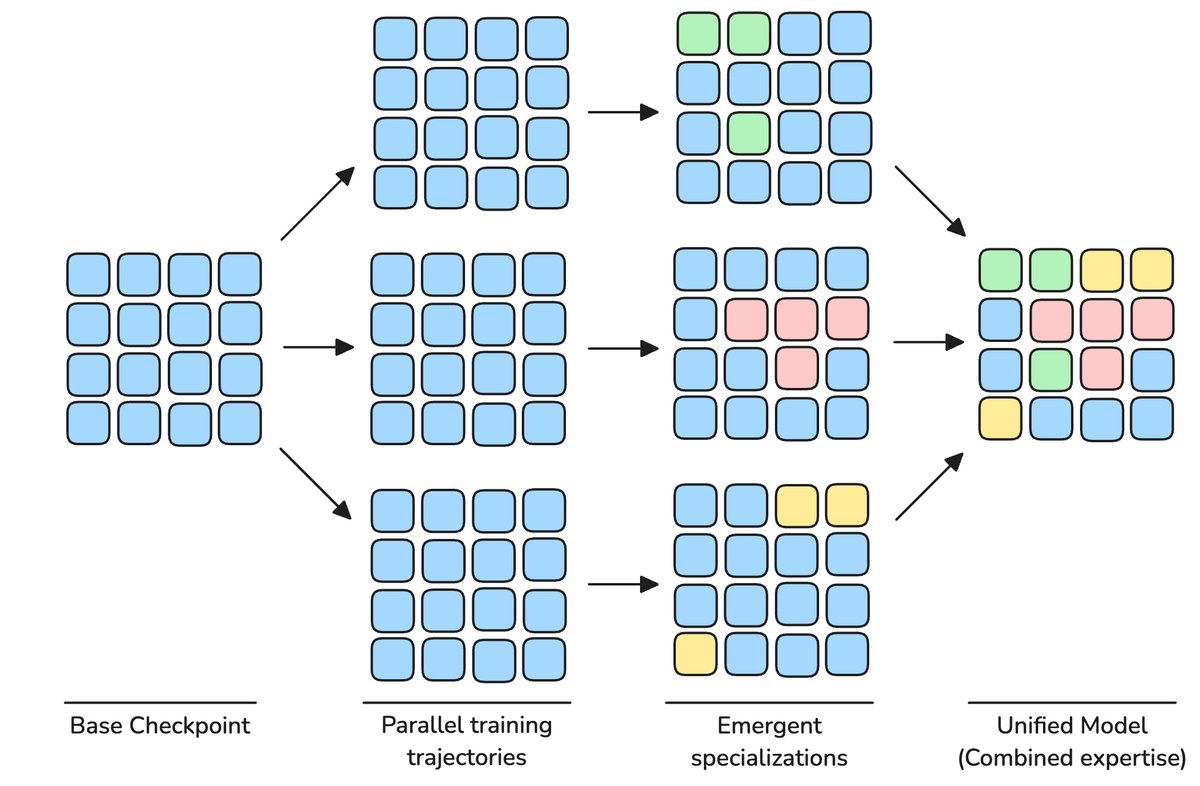
最后,通过非均匀权重平均(non-uniform weight averaging)的方法,将这些专家的“智慧”(模型权重)融合到一个模型中。这种方法不增加任何参数,却能创造出一个在各项能力上超越单个专家的“全能选手”。
创新三:模拟驱动的数据配比
小模型对训练数据的质量和配比极为敏感。不同领域数据(如代码、数学、通用知识)的比例稍有不慎,就可能导致性能下降。
该研究采用了可扩展数据混合器(Scalable Data Mixer, SDM)框架。通过一次模拟训练运行,自动估算不同数据领域对模型性能的贡献度,从而为正式训练找到一个最优的数据配比方案。这确保了模型在训练的每个阶段都能“吃”到最科学、最营养的“数据餐”。
消融实验表明,与均匀混合数据相比,这种方法让预训练性能提升了超过10%(绝对值)。
创新四:量化感知训练,4-bit部署不掉队
模型要部署到手机上,量化(Quantization)是必经之路,即将模型权重从32位浮点数压缩到4位整数(INT4)。然而,直接对训练好的模型进行训练后量化(Post-Training Quantization, PTQ)会导致MobileLLM-Pro性能严重下降。
为此,研究团队采用了量化感知训练(Quantization-Aware Training, QAT)。在训练过程中就将量化操作引入计算图中,让模型提前“感知”到自己未来将被量化的事实,并学会在这种约束下保持高性能。
此外,他们还结合了自蒸馏(self-distillation),让全精度的模型作为教师,指导量化模型进行学习,最大程度地保留了模型的推理和长上下文能力。最终,4-bit量化后的模型性能仅有约1%的轻微下降,在实际应用中几乎可以忽略不计。
性能表现:全面超越同级模型
无论是预训练还是指令微调,MobileLLM-Pro的表现都堪称惊艳。
在预训练阶段,它在MMLU、GSM8K等11个基准测试的平均分上,超过了Gemma 3-1B和Llama 3.2-1B。
在指令微调后,它在代码生成(MBPP, HumanEval)、函数调用(BFCLv2)、文本改写(OpenRewrite)等多个“助理风格”任务上同样领先于竞争对手,展现了作为端侧AI助手的巨大潜力。
总结
MobileLLM-Pro并非简单地对现有模型进行缩减,而是通过一系列精心设计的创新,系统性地解决了端侧模型面临的核心挑战:如何在有限的资源下实现强大的通用能力、长上下文理解和高效部署。
通过开源模型权重,Meta不仅为业界提供了一个可以直接使用的强大端侧模型,更重要的是,它为未来如何构建更高效、更智能的端侧AI系统提供了一份宝贵的“Pro”级蓝图。