Modular Prompt Optimization: Optimizing Structured Prompts with Section-Local Textual Gradients
像搭积木一样优化Prompt:CMU新作MPO,分块微调击败TextGrad

你是否经历过这样的绝望时刻:为了让大模型输出理想的结果,你小心翼翼地修改Prompt(提示词)中的一个词,结果整个回答的逻辑却完全崩塌了?
ArXiv URL:http://arxiv.org/abs/2601.04055v1
对于许多开发者而言,Prompt Engineering(提示工程)更像是一门玄学而非科学。现有的自动提示优化方法(如TextGrad)往往将Prompt视为一整块不可分割的文本进行“全局手术”。这种粗放的方式不仅容易导致Prompt越改越长(出现“Prompt臃肿”),还经常引发指令冲突——修复了一个Bug,却引入了两个新Bug。
为了解决这一难题,卡内基梅隆大学(CMU)的研究团队提出了一种全新的思路:模块化提示优化(Modular Prompt Optimization, MPO)。MPO不再把Prompt看作一团混乱的文本,而是将其视为由固定语义模块组成的结构化对象,就像搭积木一样,对每个模块进行独立的“精修”。
告别“一锅炖”:Prompt的结构化革命
为什么小模型(如LLaMA-3 8B)在复杂任务上表现不稳定?很大程度上是因为它们对指令的结构非常敏感。
现有的自动优化方法通常采用“全局优化”策略:将整个Prompt丢给优化器,让它生成一个新的Prompt。这就像是因为代码里有一个函数报错,就试图重写整个软件项目一样,效率低下且风险极高。
MPO 的核心洞察在于:不同的Prompt片段承担着不同的功能角色。 因此,该研究提出将Prompt强制分解为五个固定的语义部分:
-
系统角色(System Role)
-
相关上下文(Relevant Context)
-
任务详情(Task Details)
-
约束条件(Constraints)
-
输出格式(Output Format)
这种结构化的划分,使得优化过程可以从“全局重写”转变为“局部微调”。
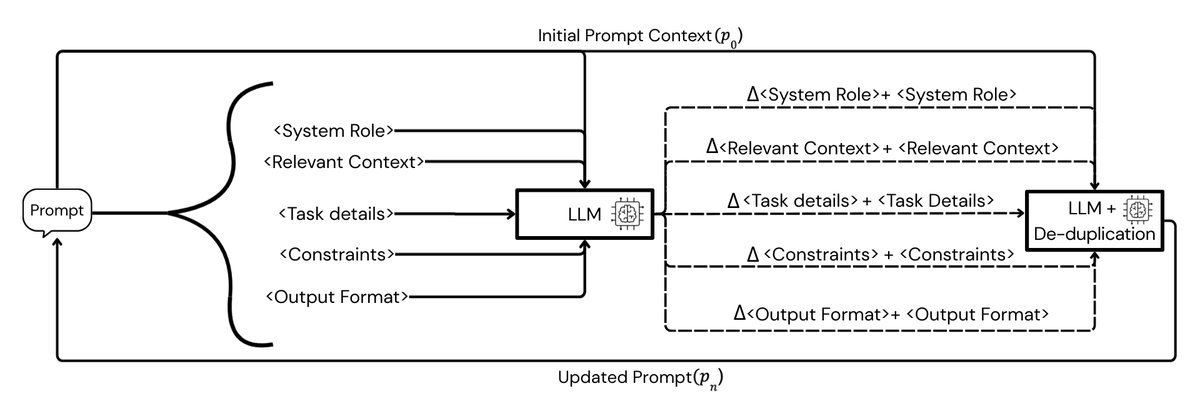
MPO是如何工作的?
MPO的工作流程非常像软件开发中的“单元测试”与“代码重构”。整个过程保持Prompt的整体架构(Schema)不变,只优化每个模块的内容。
1. 分块独立的“文本梯度”
在每一轮迭代中,MPO不会盲目地重写整个Prompt。相反,它引入了一个批评者模型(Critic Model)。这个批评者会独立地审视每一个模块(例如“任务详情”部分),并结合上下文生成针对该模块的改进建议。
这种改进建议被称为局部文本梯度(Section-Local Textual Gradients)。与传统深度学习中的数值梯度不同,这里的“梯度”是自然语言形式的反馈,明确指出了该部分应该如何修改以更好地完成任务。
2. 增量更新与去重
得到改进建议后,MPO将其应用到对应的模块上。为了防止Prompt变得冗长啰嗦,MPO引入了一个关键步骤:去重(De-duplication)。
数学上,如果我们把第 $t$ 轮的第 $k$ 个模块记为 $s_{t}^{(k)}$,批评者生成的建议记为 $\Delta s_{t}^{(k)}$,那么更新过程可以表示为:
\[\tilde{s}_{t+1}^{(k)}=s_{t}^{(k)}\oplus\Delta s_{t}^{(k)}\] \[s_{t+1}^{(k)}=\mathcal{D}\!\left(\tilde{s}_{t+1}^{(k)}\right)\]其中 $\mathcal{D}$ 代表去重操作。这一步确保了新生成的模块既吸收了改进意见,又保持了精简,避免了不同模块之间的指令打架。
实验结果:简单即是有效
研究团队在两个经典的推理基准测试集——ARC-Challenge 和 MMLU 上评估了MPO的效果,并使用了 LLaMA-3 8B-Instruct 和 Mistral-7B-Instruct 作为求解模型。
对比对象包括:
-
未微调的结构化Prompt:仅使用了上述分块结构,但未进行迭代优化。
-
TextGrad:目前最先进的将Prompt视为整体进行优化的基线方法。
结果令人印象深刻:
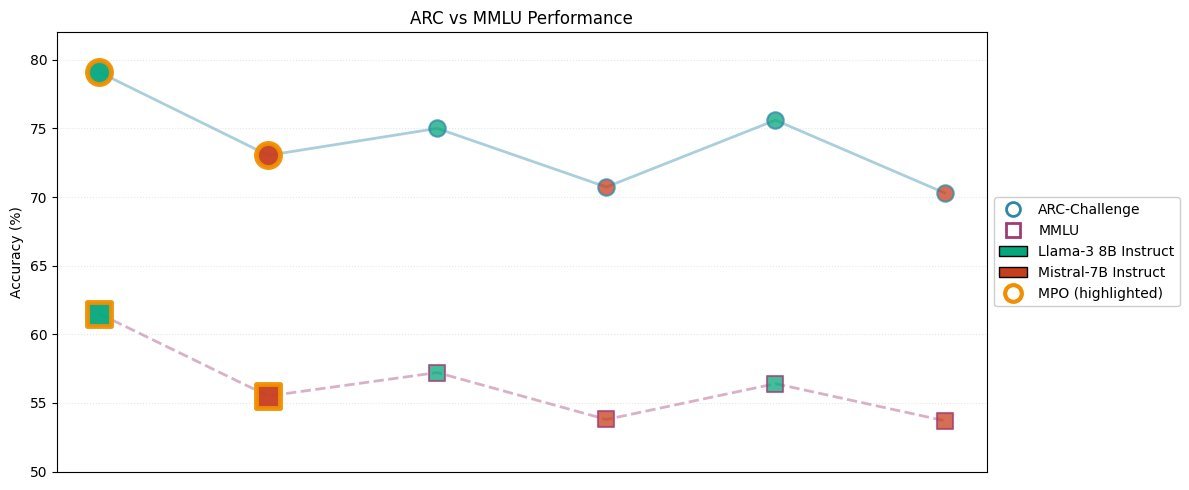
从上图可以看出,MPO在所有测试中均取得了一致的性能提升。
-
在 ARC-Challenge 上,MPO显著超越了TextGrad和基线Prompt。
-
在 MMLU 上,TextGrad甚至出现了副作用(性能低于未微调的Prompt),而MPO依然保持了稳定的增长。
这表明,通过保持固定的Prompt架构并进行局部的、分块的优化,不仅能提升模型的推理能力,还能避免传统方法中常见的“优化崩塌”问题。
总结
MPO的成功向我们展示了一个朴素但深刻的道理:结构即力量。
在大型语言模型的应用中,我们往往过于关注模型参数的调整或Prompt内容的“炼丹”,却忽视了Prompt本身的结构设计。MPO通过将Prompt工程转化为一个模块化的、可解释的优化过程,为提升开源小模型的推理能力提供了一条清晰且低成本的路径。
对于正在构建AI Agent或复杂RAG系统的开发者来说,MPO提供了一个极具价值的启示:与其在一个几千字的Prompt里大海捞针般地找错误,不如先把你的Prompt“模块化”,然后逐个击破。