MoEBlaze: Breaking the Memory Wall for Efficient MoE Training on Modern GPUs
MoEBlaze:打破显存墙!Meta提出MoE训练新框架,速度飙升4倍

在当今的大模型时代,混合专家模型(Mixture-of-Experts, MoE) 已经成为了扩展模型参数量的首选架构。从 Mixtral 8x7B 到 DeepSeek-V3,MoE 凭借其“稀疏激活”的特性,让我们能在不显著增加推理成本的前提下,训练出万亿参数级别的巨兽。
ArXiv URL:http://arxiv.org/abs/2601.05296v1
但 MoE 的训练并非一帆风顺。你是否想过,为什么即使拥有 H100 这样强大的 GPU,MoE 的训练依然经常卡在“显存不足”(OOM)上?
这就引出了一个核心痛点:显存墙(Memory Wall)。
传统的 MoE 训练为了处理稀疏的 Token 路由,需要开辟巨大的缓冲区(Buffer),还要存储大量的中间激活值(Activation)。这些开销就像隐形的枷锁,限制了 Batch Size 和序列长度的扩展。
为了解决这个问题,Meta 和 Thinking Machines Lab 联合提出了一项名为 MoEBlaze 的新技术。这项研究直击 MoE 训练的显存痛点,通过重新设计数据结构和内核,实现了惊人的性能提升:训练速度提升超过 4 倍,显存占用减少超过 50%!
今天,我们就来深入解读 MoEBlaze 究竟是如何做到的。
核心挑战:MoE 训练中的“显存黑洞”
在深入技术细节之前,我们需要先理解为什么 MoE 训练这么耗显存。
传统的 MoE 计算流程可以简单概括为:分发(Dispatch) -> 计算(Compute) -> 聚合(Combine)。
-
Token 路由:Gating 网络决定每个 Token 去哪个专家。
-
物理搬运:系统通常会把分配给同一个专家的 Token 物理地“搬运”并打包到一个连续的缓冲区中。
-
中间激活:在专家内部(通常是 MLP),现代大模型喜欢用 SwiGLU 这种复杂的激活函数,这会产生大量的中间变量需要保存,以便反向传播时使用。
问题出在哪?
-
冗余的路由缓冲区:为了把 Token 整理好喂给专家,传统方法(如 Megablocks 之前的早期实现)往往需要预分配巨大的 Buffer,甚至涉及 Padding(填充)或 Drop(丢弃)Token,既浪费显存又可能影响精度。
-
激活值爆炸:随着序列长度(Sequence Length)增加,保存中间状态所需的显存呈线性增长。特别是 SwiGLU 这种包含多个投影和逐元素操作的结构,显存占用更是惊人。
MoEBlaze 的破局之道:极致的“零拷贝”与“智能重算”
MoEBlaze 的核心哲学非常直接:既然搬运数据和存数据最耗显存,那我们就尽量不搬运,也不存中间值。
它通过两大核心技术实现了这一目标:
1. 零缓冲的 Token 路由(Memory-Efficient Token Routing)
传统的做法是把 Token 真的“搬”到专家对应的 Buffer 里。MoEBlaze 说:不,我们只记录索引(Index)。
MoEBlaze 设计了一套轻量级的索引数据结构:
-
\(expert_token_indices\):记录每个专家分到了哪些 Token ID。
-
\(token_expert_indices\):记录每个 Token 被分到了哪些专家 ID。
这有什么好处?
在专家计算阶段,MoEBlaze 不再读取打包好的 Token Buffer,而是直接根据索引,从原始输入中“按需抓取(On-the-fly Gather)”数据进行计算。计算完的结果,也直接通过索引“按需归约(On-the-fly Reduction)”回输出张量。
这相当于把原来“物理搬运”的重资产模式,变成了一套“逻辑索引”的轻资产模式,彻底消除了中间巨大的路由缓冲区。
为了高效构建这些索引,MoEBlaze 还设计了一套无原子操作(Atomic-free)的并行构建算法,避免了 GPU 上的写冲突,保证了极高的构建速度。
2. 内核协同设计与智能激活检查点(Co-designed Kernels & Smart Checkpoint)
针对 SwiGLU 这种显存杀手,MoEBlaze 采用了内核融合(Kernel Fusion)和激活检查点(Activation Checkpoint)相结合的策略。
我们知道,SwiGLU 的公式是 $\text{SwiGLU}(x) = \text{SiLU}(xW_1) \cdot (xW_2)$。
传统训练中,为了计算梯度,必须把 $xW_1$、$xW_2$、$\text{SiLU}(xW_1)$ 等中间结果都存下来。
MoEBlaze 的策略是:只存最关键的,其他的算两遍。
它只缓存两个背靠背 MLP 之间的中间结果,而对于 MLP 内部繁杂的非线性操作产生的中间值,选择在反向传播时重算(Recompute)。
虽然“重算”听起来增加了计算量,但由于 MoEBlaze 高度融合了内核,减少了大量访问全局显存(Global Memory)的开销(这通常比计算更慢),最终的结果反而是既省了显存,又快了速度。
实验结果:全方位的碾压
研究团队在 NVIDIA H100 GPU 上进行了测试,对比了目前的行业标杆 Megablocks。结果令人印象深刻:
显存占用大幅下降
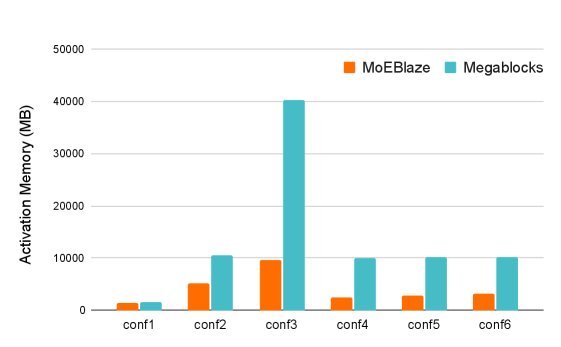
如下图所示,在 SwiGLU 激活函数下,MoEBlaze 的显存占用(橙色线)远低于 Megablocks(蓝色线)。在某些配置下(如 conf3),显存占用甚至不到对方的 1/4。这意味着在同样的硬件上,你可以训练 Batch Size 更大、序列更长的模型。
训练速度显著提升
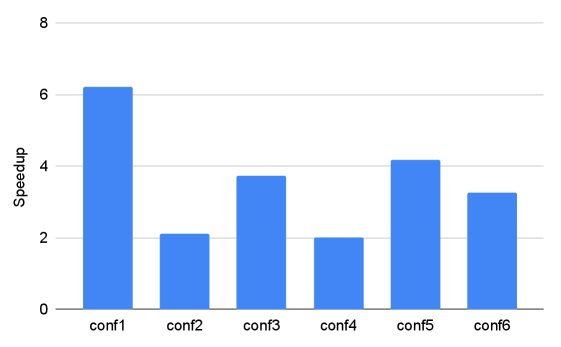
不仅省显存,跑得还更快。在 SwiGLU 配置下,MoEBlaze 实现了 2倍到 6.2倍 的速度提升。这主要归功于减少了数据搬运和高效的内核实现。
总结
MoEBlaze 的出现再次证明了在 AI 系统领域,“软硬结合”优化的巨大潜力。通过精细的数据结构设计和内核优化,它成功打破了 MoE 训练的显存墙。
对于正在尝试训练或微调大规模 MoE 模型的开发者来说,MoEBlaze 提供了一个极其重要的思路:不要让数据搬运成为瓶颈,让计算尽可能在芯片内部完成。
随着长上下文(Long Context)成为大模型的标配,像 MoEBlaze 这样极致压榨显存效率的技术,无疑将成为未来基础设施的重要基石。