MIT新突破:Transformer实现火箭全程自主驾驶,成本仅高出最优解3%

火箭发射、级间分离、最终入轨……这些惊心动魄的阶段,传统上需要多个独立的控制器接力完成。这就像一场F1比赛,赛车每次进站都要换一个新车手,不仅操作复杂,而且任何交接失误都可能导致灾难性的后果。现在,来自麻省理工学院(MIT)的一项研究,让Transformer化身“全能舵手”,仅用一个AI模型就搞定了从地面到太空的全程轨迹优化。
论文标题:Multi-Phase Spacecraft Trajectory Optimization via Transformer-Based Reinforcement Learning
ArXiv URL:http://arxiv.org/abs/2511.11402v1
这项工作引入了一个基于Transformer的强化学习框架,用单一、统一的策略,无缝衔接了航天器飞行的多个动态迥异的阶段,为未来的自主太空任务规划奠定了坚实的基础。
分段控制:阿波罗时代的“遗产”
自阿波罗时代以来,受限于计算能力,复杂的太空任务总是被分解为一个个独立的阶段,例如发射、上升、轨道保持、交会对接等。每个阶段都由一个专门设计的控制器负责。
这种“分段式”方法虽然在当时是可行的,但其弊端也显而易见:
-
操作复杂:需要为每个阶段单独设计和验证控制器。
-
交接脆弱:在不同阶段的控制器切换时,容易出现不稳定甚至失败。
-
适应性差:难以应对突发状况或动态变化的环境。
随着太空活动日益频繁,我们需要更智能、更自主的控制系统。
Transformer的“长时记忆”优势
为什么Transformer能担此重任?答案在于其强大的自注意力机制(self-attention mechanism)。
传统的循环神经网络(Recurrent Neural Networks, RNNs)虽然有记忆能力,但随着时间序列变长,容易出现“梯度消失”问题,难以记住久远之前的重要信息。而Transformer可以直接访问序列中的任何一个时间点,建立长距离依赖关系。
对于航天任务而言,这意味着AI在决定入轨阶段的引擎推力时,依然能“回想起”发射初期的飞行状态,从而做出全局最优的决策。这正是实现多阶段统一控制的关键。
核心架构:GTrXL + PPO
该研究提出的框架,将门控Transformer-XL(Gated Transformer-XL, GTrXL)与近端策略优化(Proximal Policy Optimization, PPO)算法相结合。
-
GTrXL:这是对标准Transformer的改进,专为强化学习任务设计,解决了训练不稳定的问题。它通过一个滑动的记忆窗口,让Agent能够“记住”最近几十到上百个时间步的状态和动作,从而在没有明确指令的情况下,通过上下文感知到任务阶段的变化。
-
PPO:作为一种先进的强化学习算法,PPO通过限制每次策略更新的幅度,确保了训练过程的稳定性和收敛性。
这个组合让AI Agent能够在与环境的不断交互中,自主学会一套能够贯穿所有飞行阶段的通用驾驶策略。
从理论到实践:三步验证
为了证明该框架的有效性,研究者进行了一系列由简到难的仿真实验。
第一步:基础测试
在经典的“双积分器”控制问题上,这个Transformer策略的表现与理论上的最优解——线性二次调节器(Linear-Quadratic Regulator, LQR)——进行了比较。结果显示,AI策略的总成本仅比最优解高出平均3%,证明了其学习基本最优控制策略的能力。
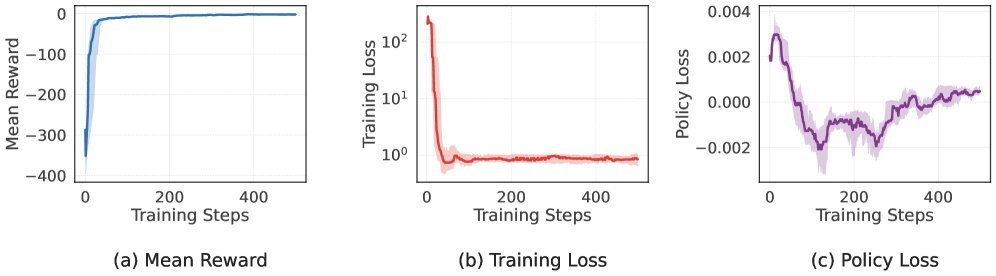
第二步:非线性挑战
接着,研究团队在更复杂的非线性系统“范德波尔振荡器”上进行测试。实验证明,该框架同样能够有效地处理非线性动力学,并引导系统在多个预设航点之间穿梭。
第三步:终极考验——多阶段火箭发射
最激动人心的部分,是将该框架应用于一个真实的、复杂的多阶段火箭发射任务:将火箭送入地球同步转移轨道(Geostationary Transfer Orbit, GTO)。
这个任务包含四个截然不同的阶段:大气层内飞行、第一级分离、第二级工作、进入最终轨道。整个过程动力学模型会发生突变(如质量瞬间减小),控制目标也随之改变。
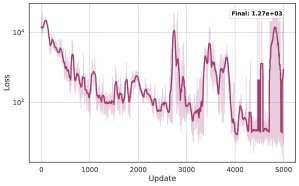
结果令人印象深刻:
-
单一策略完成全程:无需任何人工切换,AI自主完成了从发射到入轨的全过程。
-
高精度入轨:最终的轨道参数与目标值的误差均在5%以内,其中半长轴误差为1.8%,偏心率误差为1.5%。
考虑到AI完全是通过与环境交互“自学”成才,并未被告知任何轨道力学公式,这一成果充分展示了该框架的巨大潜力。
结论
这项研究成功证明,基于Transformer的强化学习框架可以构建一个统一、自适应的航天器控制策略,告别了过去数十年来沿用的分段控制模式。
通过利用Transformer的“长时记忆”能力,AI能够自主识别任务阶段的转换并调整策略,这不仅大大降低了任务规划的复杂性,也为应对未来太空任务中的不确定性和突发状况提供了新的可能。一个更自主、更智能的太空探索时代,或许正加速到来。