MUSIC: MUlti-Step Instruction Contrast for Multi-Turn Reward Models
别只看最后一句话!DeepMind新作MUSIC:合成数据攻克多轮对话评估难题

大模型(LLM)如今已经能写出漂亮的诗歌或代码片段,但你是否发现,一旦和它多聊几轮,它的逻辑就开始“掉链子”?
ArXiv URL:http://arxiv.org/abs/2512.24693v1
这背后的核心痛点在于:我们很难教会模型什么是“好的多轮对话”。 现有的评估数据大多只盯着对话的“最后一句话”看,就像评价一部电影只看最后五分钟,完全忽略了中间的情节是否连贯。
为了解决这个问题,Google DeepMind 与普林斯顿大学的研究团队联合推出了一项名为 MUSIC(MUlti-Step Instruction Contrast)的新技术。这项技术不需要昂贵的人工标注,通过无监督的方式合成数据,就能训练出“火眼金睛”的多轮奖励模型(Reward Model),让模型学会从整体上把控对话质量。
为什么现在的奖励模型“目光短浅”?
在 RLHF(Reinforcement Learning from Human Feedback)的流程中,奖励模型(RM)扮演着裁判的角色。然而,训练这个裁判的数据集(如 Skywork, UltraFeedback 等)存在一个巨大的缺陷:偏好对(Preference Pairs)通常只在最后一轮有差异。
通常的数据长这样:
-
好回答:[用户:你好] -> [AI:你好] -> [用户:写首诗] -> [AI:写了一首好诗]
-
坏回答:[用户:你好] -> [AI:你好] -> [用户:写首诗] -> [AI:写了一首烂诗]
前几轮完全一样,只有最后不同。这导致训练出来的 RM 变得“偷懒”,只关注最后一句,而忽略了多轮对话中至关重要的连贯性(Coherence)和一致性(Consistency)。
MUSIC:给对话“加点料”
为了让 RM 学会看全貌,研究团队提出了 MUSIC。这是一种无监督的数据增强策略,它的核心思想是:制造在多轮对话中持续存在的质量差异。
MUSIC 的工作流程非常巧妙,它利用 LLM 模拟用户和助手,生成两组对话轨迹:
-
种子上下文(Seed Context):从现有数据集中随机截取一段对话作为开头。
-
模拟对话(Simulation):让 LLM 分别扮演用户和助手,继续把对话聊下去。
-
制造差异(The Contrast):
-
Chosen(胜出组):助手正常遵循指令,生成高质量回复。
-
Rejected(落败组):这是 MUSIC 的精髓所在。系统会在中间某一步,悄悄修改用户的指令(Instruction Contrast),诱导助手回答一个“相关但错误”的问题。
-
比如,用户原本问“如何做红烧肉?”,在 Rejected 组中,系统在后台把指令改成“如何做回锅肉?”,助手虽然写出了完美的回锅肉菜谱,但对于用户原本的“红烧肉”需求来说,这就是一个严重的指令遵循错误。这种错误会随着对话的进行被保留下来,从而形成贯穿多轮的质量差异。
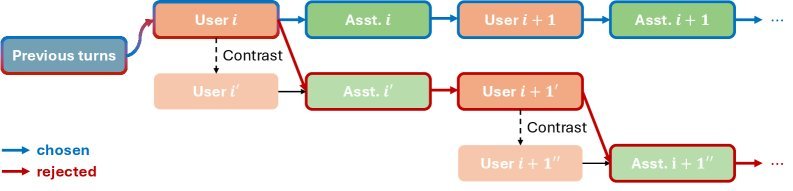
图 1:MUSIC 数据增强流程概览。通过引入对比指令提示(Contrastive Instruction Prompt),在 Rejected 分支中诱导质量下降,从而生成具有多轮差异的偏好对。
核心方法论
从数学角度看,MUSIC 旨在优化 Bradley-Terry (BT) 模型的目标函数。假设我们有一个多轮对话偏好数据集 ${\mathcal{D}}$,包含胜出对话 $C_{\text{chosen}}$ 和落败对话 $C_{\text{rejected}}$,训练目标是最小化负对数似然损失:
\[{\mathcal{L}}(\theta,{\mathcal{D}})=\mathbb{E}_{C_{\text{chosen}},C_{\text{rejected}}\sim{\mathcal{D}}}\log\sigma\left(R_{\theta}(C_{\text{chosen}})-R_{\theta}(C_{\text{rejected}})\right)\]MUSIC 的贡献在于构造了更具挑战性的 ${\mathcal{D}}_{\text{MUSIC}}$,并将其与原始数据混合,形成增强数据集 ${\mathcal{D}}_{\text{aug}}={\mathcal{D}}\cup{\mathcal{D}}_{\text{MUSIC}}$。
在生成 Rejected 样本时,研究者使用了一种特殊的 Prompt,要求助手生成一个“对修改后的指令是好回答,但对原始用户问题是坏回答”的回复。这种精细的控制确保了模型必须理解上下文才能判断好坏,而不能仅仅通过回复的流畅度来作弊。
实验结果:多轮能力大涨,单轮也没落下
研究团队基于 Gemma-2-9B-Instruct 模型,使用 Skywork 数据集进行了实验。他们对比了仅使用原始数据训练的 Baseline RM 和使用了 MUSIC 增强的 RM。
1. 多轮对话评估能力显著提升
在 Best-of-N (BoN) 推理任务中,MUSIC 增强后的 RM 能够挑选出质量更高的对话。经过 Gemini 1.5 Pro 的评审,MUSIC 指导下的对话在 Anthropic HH 和 UltraInteract 数据集上均优于 Baseline。
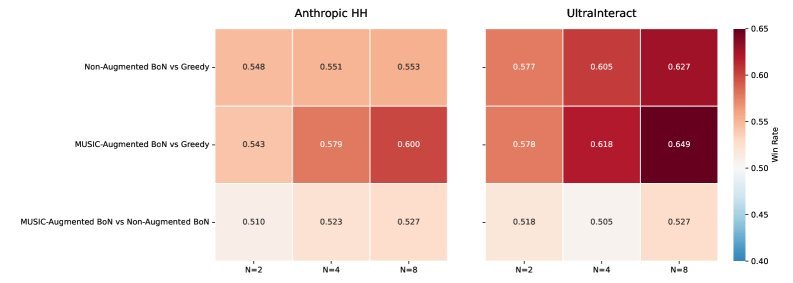
图 2:在 Best-of-N ($N\in{2,4,8}$) 设置下,MUSIC 增强 RM 与 Baseline RM 的胜率对比。随着 $N$ 的增加,MUSIC 利用候选池优势的能力更强。
2. 意外之喜:推理能力增强
一个常见的问题是:针对多轮优化的模型,会不会在传统的单轮任务上退化?
实验结果令人惊喜。在标准的 RewardBench 测试中,MUSIC 增强后的 RM 不仅没有退步,反而在推理(Reasoning)类别上取得了 3.9% 的提升。
| 模型 | Chat | Chat Hard | Safety | Reasoning | Average |
|---|---|---|---|---|---|
| Skywork (Baseline) | 96.9 | 73.0 | 90.9 | 83.1 | 86.0 |
| Skywork + MUSIC | 96.4 | 72.4 | 90.8 | 87.0 | 86.6 |
这表明,接触逻辑连贯的多轮对话数据,似乎隐式地增强了模型处理复杂推理步骤的能力。
总结与展望
MUSIC 的出现揭示了一个重要的道理:在对齐(Alignment)阶段,数据的“结构”比“数量”更重要。
通过合成具有多轮差异的对比数据,DeepMind 成功地让奖励模型学会了“顾全大局”。这种无需人工标注的方法具有极高的扩展性。未来,随着对话系统向更长、更复杂的 Agent 任务演进,类似 MUSIC 这样关注长程依赖(Long-horizon dependency)的评估方法,将成为打造更智能 AI 的关键拼图。