Agent训练告别数值奖励:字节跳動NLAC让AI用“人话”指导,性能最高提升24%

当今,我们正目睹 LLM Agent(大语言模型智能体)的浪潮,它们被寄予厚望,以期能自主处理网页浏览、工具使用甚至与人对话等复杂任务。但一个棘手的问题始终摆在面前:如何高效地训练这些Agent?传统方法就像一位沉默的考官,只给最终得分,却从不解释错在哪里,导致训练过程既不稳定又极其耗费数据。
ArXiv URL:http://arxiv.org/abs/2512.04601v1
现在,来自字节跳动和加州大学伯克利分校的一项研究,或许将彻底改变这一现状。他们提出了自然语言行动者-评论家(Natural Language Actor-Critic, NLAC)算法。其核心思想石破天惊:让作为“评论家”的LLM不再输出冰冷的数值分数,而是直接生成自然语言的“批评”和“指导”。这相当于为Agent配备了一位能开口说话、循循善诱的专属教练。
传统Agent训练的困境:低效的“数字游戏”
目前,在没有专家示范数据的情况下,训练LLM Agent普遍依赖强化学习(Reinforcement Learning, RL),特别是像PPO这样的策略梯度方法。
这些方法存在两大痛点:
-
数据效率低下:它们大多是在线策略(on-policy)的,意味着模型每更新一次,就需要用当前最新的策略去采集全新的数据,极其浪费算力。
-
奖励信号稀疏:在长流程任务中,Agent可能要执行几十步操作才能获得一个最终的成功或失败信号(一个简单的$1$或$0$)。这种稀疏的标量奖励,很难让模型明白究竟是哪一步做得好、哪一步做得差。
这就像蒙着眼睛走迷宫,只有在撞墙或到达终点时才得到一次反馈,学习效率可想而知。
NLAC:会“说话”的评论家才是好教练
NLAC巧妙地将经典的行动者-评论家(Actor-Critic)框架与LLM的语言能力相结合,并改造成了更高效的离线策略(off-policy)学习。
整个框架包含两个核心角色,它们都由同一个LLM通过不同提示词(Prompt)来扮演:
-
行动者(Actor):即Agent策略本身,负责观察环境并做出决策。
-
评论家(Critic):负责评估行动者的行为,但它输出的不是数值,而是详细的文本评论。
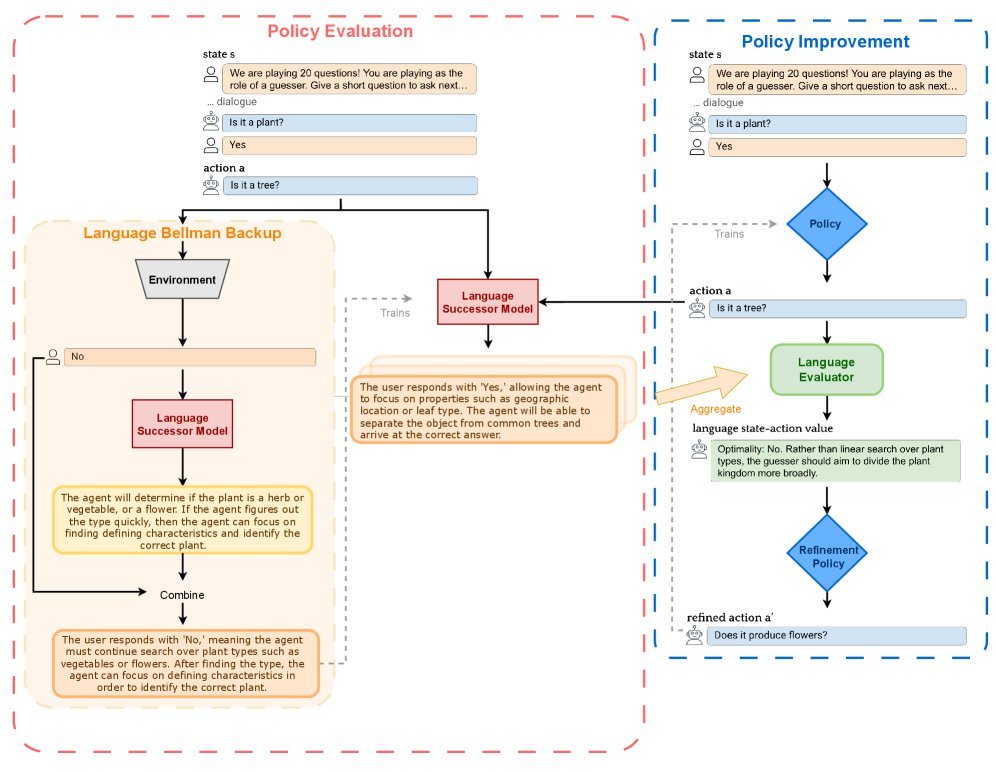
让我们看看这位“会说话”的教练是如何工作的。
策略评估:评论家如何生成精准的“批评”?
评论家的任务是评估一个行为的好坏。NLAC的评论家通过三步来完成这项工作:
-
预测未来(语言后继模型):首先,评论家要学会预测“如果采取这个行动,未来可能会发生什么?”。它会生成一段文本,描述接下来可能发生的一系列事件和最终结果。这被称为语言后继模型(language successor model)。
-
离线学习未来(语言贝尔曼回溯):为了高效训练这个预测模型,研究者提出了一个名为语言贝尔曼回溯(language Bellman backup)的巧妙机制。它借鉴了传统RL中的贝尔曼方程思想,但操作对象是文本。这使得模型可以利用已有的、非当前策略产生的数据(即离线数据)进行学习,极大提升了数据利用率。
\[M^{\pi} =\arg\min\_{M}\mathbb{E}\_{(s\_{t},a\_{t}s\_{t+1})\sim\mathcal{D}}\left[D\_{f}\left(M(\cdot\mid s\_{t},a\_{t})\ \mid \mid \ \mathcal{B}\_{L}\,M(\cdot\mid s\_{t},a\_{t})\right)\right]\,\] -
汇总并生成评论:在预测了多种可能的未来后,评论家会像一个分析师一样,将这些可能性汇总起来,并最终生成一段综合性的文本评论$Q^{\pi}_{L}(s_{t},a_{t})$。这段评论会明确指出当前行为是否最优,并引用可能的未来结果作为论据。
策略改进:行动者如何听懂“人话”并进步?
拿到了评论家给出的详细书面反馈,行动者(Agent策略)该如何学习呢?
它不再是盲目地朝着一个更高的分数去试探,而是进入一个“自我反思和改进”的阶段。
具体来说,模型会接收到原始行为和评论家给出的反馈,然后被要求生成一个经过改进的(refined)新行为$a_{t}^{r}$。这个过程被称为策略提炼(policy distillation)。
\[\pi^{\prime}=\arg\max\_{\pi}\mathbb{E}\_{s\_{t}\sim\mathcal{D}}\left[D\_{f}\left(\pi(\cdot\mid s\_{t})\ \mid \mid \ \pi^{r}(\cdot\mid s\_{t},a\_{t}^{1},\ldots,Q^{\pi}\_{L}(s,a_{t}^{m}))\right)\right]\,\]通过这种方式,Agent的学习从“随机探索”变成了“有指导的修正”,学习路径更明确,也更高效。
理论与实践双重验证
你可能会问,这种用语言当奖励的方法,听起来很直观,但它在理论上站得住脚吗?
答案是肯定的。研究证明,在一些合理的假设下,NLAC算法能够收敛到最优策略。这意味着,这位“语言教练”不仅能指导,还能保证把你教到最好。
在实践中,NLAC的表现同样令人印象深刻。研究团队在数学推理(MATH)、策略对话(20Q)和结合了对话与工具使用的客服任务(τ-bench)上进行了广泛测试。
从上表可以看出,无论是对于7B还是13B参数量的模型,NLAC在各项任务上都稳定优于PPO、GRPO等主流RL微调方法。特别是在需要跨领域泛化的客服任务(Airline)中,基于Llama2-7B的NLAC取得了32.1%的成功率,相比PPO的25.8%,实现了约24%的相对性能提升。
下面的例子生动地展示了NLAC的威力。

在20Q猜谜游戏中,基础Agent只会傻傻地顺着一个思路问下去(“是红色的吗?”“是蓝色的吗?”)。而NLAC的评论家一针见血地指出:“你正在对颜色进行线性搜索,这很低效。” 从而引导Agent采取更聪明的策略。
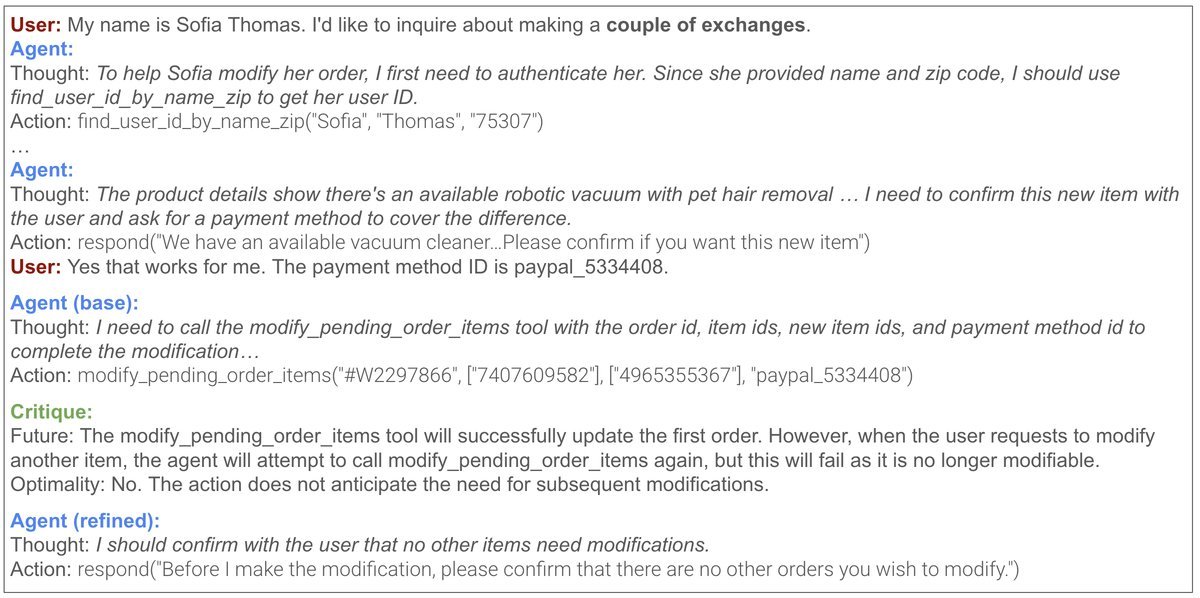
在复杂的客服场景中,Agent需要为用户处理多个换货请求。基础模型试图一次性处理所有请求,但这违反了“一次API调用只能处理一个请求”的内部规则。一个简单的数值奖励信号根本无法传达这种细微的错误。而NLAC的评论家则能清晰地指出:“根据政策,你应该先收集所有要交换的物品,然后再一次性处理。”
结语
NLAC的提出,标志着LLM Agent训练范式的一次重要演进。它不再将LLM视为一个只能被动接收数值信号的黑箱,而是充分利用其最核心的语言理解和生成能力,将训练过程从“基于分数的强化”转变为“基于理解的改进”。
这种用“人话”来指导AI的思路,不仅让训练过程更稳定、更高效,也为我们理解和调试复杂的Agent行为打开了一扇新的窗户。或许,未来的AI训练,将不再是冰冷的数字调优,而是一场充满智慧对话的“教学相长”。