NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
NextFlow横空出世:6万亿Token打造统一自回归,5秒生成1024高清图

长期以来,AI 领域存在着一道“隐形柏林墙”:大语言模型(LLMs)在逻辑推理和文本理解上独步天下,而扩散模型(Diffusion Models)则统治着视觉生成的像素世界。虽然我们一直梦想着一个“大一统”的模型能同时精通这两者,但现实往往很骨感——要么是拼接缝合的怪胎,要么是虽然统一了架构但在生成速度上慢如蜗牛。
ArXiv URL:http://arxiv.org/abs/2601.02204v1
特别是对于纯自回归(Autoregressive, AR)模型来说,生成高分辨率图像简直是噩梦。传统的“光栅扫描”式(Raster-scan)预测,就像老式打印机一样逐个Token生成,生成一张 $1024 \times 1024$ 的图可能需要几分钟,这在实际应用中几乎不可接受。
今天我们要解读的这篇论文 NextFlow,由字节跳动、莫纳什大学和清华大学联合推出,它不仅打破了这堵墙,更解决了一个核心痛点:速度。
NextFlow 是一个基于 6 万亿(6T)Token 训练的统一 Decoder-only Transformer 模型。它最炸裂的特性在于:抛弃了传统的逐像素扫描,采用了“下一尺度预测”,仅需 5 秒即可生成 1024px 高清图像,速度比同类 AR 模型快了数个数量级,且画质媲美顶尖的扩散模型!
核心理念:从“下一个Token”到“下一尺度”
传统的自回归模型(如 GPT-4)处理文本时,是预测“下一个词”(Next-Token Prediction)。早期的视觉自回归模型(如 Chameleon, Emu)也生搬硬套了这个逻辑,将图像展平成长序列,从左上角预测到右下角。
但图像和文本本质是不同的:文本是严格序列化的,而图像是层级化的(从轮廓到细节)。
NextFlow 的核心创新在于“因地制宜”:
-
对文本:保留经典的 下一个Token预测(Next-Token Prediction)。
-
对图像:采用 下一尺度预测(Next-Scale Prediction)。
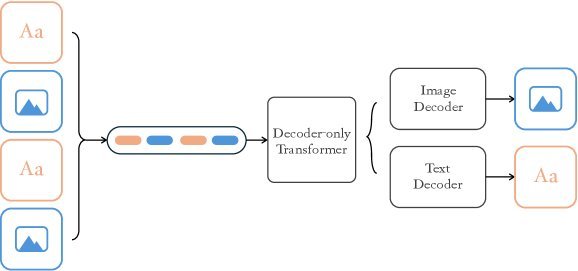
如上图所示,NextFlow 不是在一个平面上漫无目的地游走,而是像画家作画一样——先画构图(粗粒度 Token),再画轮廓,最后填充细节(细粒度 Token)。这种层级化的生成方式,使得模型能够以 $O(1)$ 的复杂度并行预测同一尺度的所有 Token,极大地释放了并行计算能力。
结果就是:生成一张 $1024 \times 1024$ 的图像,NextFlow 只需要 5 秒。相比之下,传统的 AR 模型可能需要 10 分钟以上。
架构揭秘:双码本与统一Transformer
NextFlow 的强大不仅仅在于速度,还在于它是一个真正的“全能选手”。它在一个统一的权重下,同时激活了多模态理解和生成能力。
1. 双码本 Tokenizer(Dual-Codebook Tokenizer)
为了让模型既懂语义(理解)又懂画质(生成),NextFlow 采用了基于 TokenFlow 的双码本设计:
-
语义分支:使用预训练的 SigLIP2 提取高层语义特征,确保模型“看懂”图片,这对多模态理解任务至关重要。
-
像素分支:使用 CNN 负责捕捉高频细节,确保生成的图片清晰逼真。
这种设计解决了以往 AR 模型生成的 Token 语义密度低、难以进行复杂推理的问题。
2. Decoder-Only Transformer
模型初始化自 Qwen2.5-VL-7B,继承了强大的多模态先验。研究团队发现,不需要为图像和文本设计独立的分支,统一的预测头(Unified Prediction Head)就能处理好两种模态。这意味着模型内部真正实现了模态融合。
6万亿 Token 的“炼丹”之旅
论文非常诚实地记录了他们的“Training Odyssey”(训练奥德赛),详细披露了从 256px 到 1024px 分辨率的进阶之路。
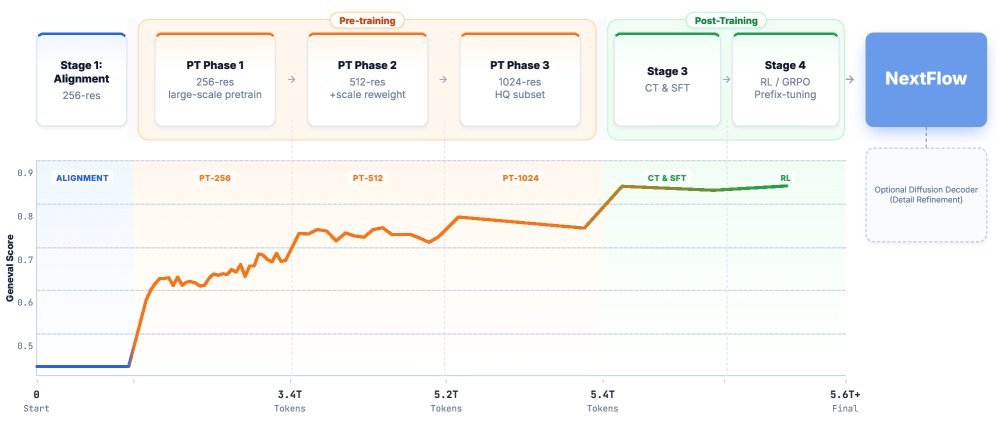
整个训练过程使用了高达 6 万亿(6T) 个 Token,涵盖了纯文本、图文对、交错图文以及视频数据。为了驯服这个庞然大物,团队引入了几个关键策略:
-
课程学习(Curriculum Learning):从 256 级预训练开始,逐步过渡到 512 级,最后在 1024 级分辨率上使用高质量数据进行冲刺。
-
强化学习(RL)与 GRPO:这是本文的一大亮点。NextFlow 引入了 群组相对策略优化(Group Reward Policy Optimization, GRPO)来对齐生成质量。
- 有趣的是,他们发现不需要优化所有步骤,只需对决定图像全局结构的“粗尺度”(Coarse Scales)前缀进行 Prefix-Tuning 即可。这不仅稳定了训练,还大幅提升了生成效果。
-
可选的扩散解码器:为了追求极致的细节(如微小的人脸或文字),NextFlow 还设计了一个可选的轻量级扩散解码器作为“后处理”插件,进一步提升视觉保真度。
实验表现:速度与质量的平衡艺术
NextFlow 的表现如何?一句话:不仅快,而且好。
在视觉质量上,NextFlow 能够生成具有极高保真度和美感的图像,足以媲美专门的扩散模型(如 SD3)。

更重要的是,由于保留了 LLM 的基因,NextFlow 天生具备 上下文学习(In-Context Learning, ICL)和 思维链(Chain-of-Thought, CoT)能力。
-
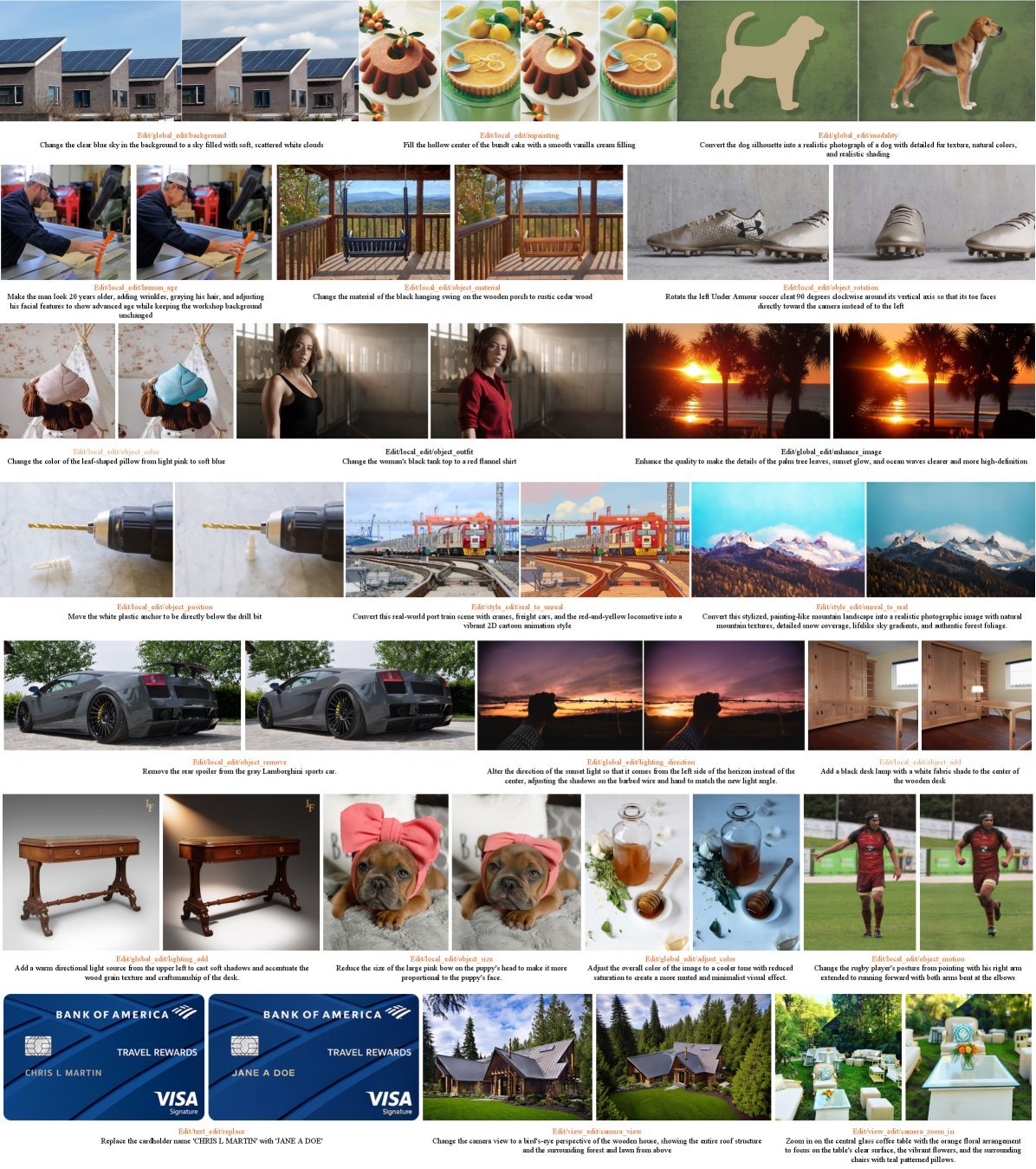
图像编辑:你可以像这就对话一样,让模型修改图片中的某个物体,而不需要重新生成整张图。
-
交错生成:模型可以流畅地生成图文并茂的文章,甚至进行简单的视频生成。
总结
NextFlow 的出现证明了统一自回归架构在多模态领域的巨大潜力。它成功挑战了“AR 模型生成慢”的刻板印象,通过 下一尺度预测 将推理速度提升了数个数量级。
这篇论文不仅提供了一个强大的模型,更重要的是它验证了一条路径:我们不需要在“理解”和“生成”之间做选择题,也不需要忍受龟速的生成体验。一个简单、统一、高效的 Transformer,或许就是通往 AGI 的那把钥匙。
对于开发者和研究人员来说,NextFlow 展示的 GRPO 强化学习策略 以及 双码本设计,都是非常值得借鉴的“炼丹”技巧。