NRGPT: An Energy-based Alternative for GPT
NRGPT重构GPT底层逻辑:推理即能量下降,抗过拟合能力显著提升

在大语言模型(LLM)的统治时代,Transformer 架构几乎成为了唯一的真理。无论是 GPT-4 还是 Llama,本质上都是在做同一件事:将输入序列通过层层映射,预测下一个 Token。
ArXiv URL:http://arxiv.org/abs/2512.16762v1
但如果我们将视角切换一下:如果推理过程不是简单的函数映射,而是一个物理系统寻找“最低能量状态”的动力学过程,会发生什么?
来自布朗大学、佐治亚理工、IBM 研究院和 MIT 的研究团队联合提出了一种全新的架构——NRGPT(eNeRgy-GPT)。这项研究并非简单的架构微调,而是试图在数学底层将主流的 GPT 架构与经典的 基于能量的模型(Energy-based Models, EBM)进行大一统。
最令人兴奋的是,该研究证明:我们熟知的 Transformer 前向传播,竟然可以被重新解释为在能量景观(Energy Landscape)上的梯度下降。而且,这种新架构在长周期训练中表现出了比传统 GPT 更强的抗过拟合能力。
为什么要把 GPT 变成“能量模型”?
基于能量的模型(EBM)在 AI 历史上有着悠久的传统,最早可追溯到 Hopfield 网络。在 EBM 的框架下,神经网络被定义为一个标量能量函数。生成的样本如果“合理”(像训练数据),能量就低;如果“离谱”,能量就高。推理的过程,就是寻找能量最小值的过程。
然而,EBM 和 GPT 长期以来“水火不容”:
-
EBM 擅长“完形填空”(如 Energy Transformer),即给定部分信息,通过能量下降补全缺失部分(类似图像修复)。
-
GPT 擅长“因果预测”,即根据上文预测下文,且必须遵循严格的时间顺序(Causal Masking)。
NRGPT 的核心突破在于:它通过极其精妙的数学设计,修改了 GPT 的设置,使其既保留了自回归生成的特性,又完全符合 EBM 的动力学框架。
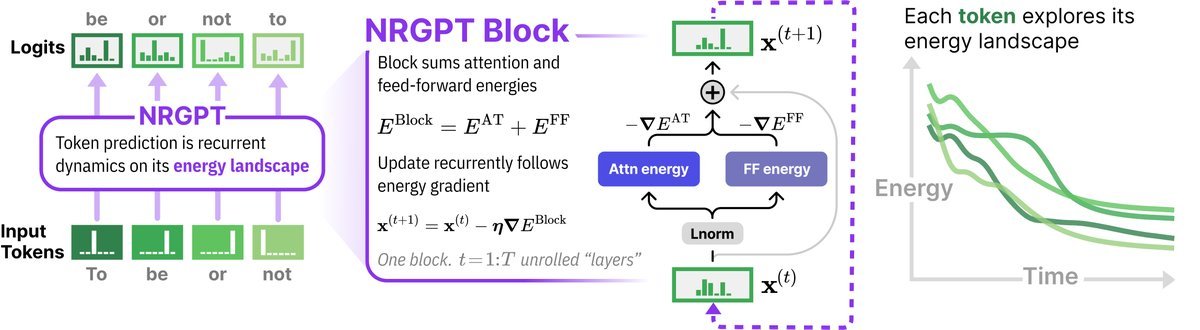
图 1:NRGPT 将标准 GPT 设置转化为基于能量的框架。网络被定义为注意力能量和前馈能量的总和。每个 Token 通过探索能量景观转化为下一个 Token。
NRGPT 的核心魔法:推理即梯度下降
NRGPT 的核心思想是:将 Transformer 的一层前向传播,看作是能量函数的一次梯度下降更新。
在标准 Transformer 中,第 $t+1$ 层的输出 $\mathbf{x}^{(t+1)}$ 通常由第 $t$ 层经过 Attention 和 MLP 后相加得到(残差连接)。而在 NRGPT 中,这个更新规则被改写为:
\[\mathbf{x}^{(t+1)}=\mathbf{x}^{(t)}-\mathbf{\eta}^{(t)}\mathbf{\nabla}E(x^{(t)})\]这里,$\mathbf{\eta}$ 是推理率(Inference Rate),而 $E$ 是能量函数。为了让这个公式成立,研究团队必须反向推导出一个特殊的能量函数 $E$,使得它的梯度 $\nabla E$ 恰好长得像 Transformer 的 Attention 和 Feedforward 层。
1. 注意力即能量 (Attention Energy)
研究者发现,标准的 Softmax Attention 机制可以由以下能量函数的梯度推导出来:
\[E^{\mathrm{AT}}\_{A}(\mathbf{g}) =-\frac{1}{\beta}\sum\_{h}\alpha\_{h}\log\Big[\sum\_{B<A}\exp\big(\beta\mathbf{g}\_{B}^{T}{\mathbf{J}}\_{h}\mathbf{g}\_{A}\big)\Big]\]当你对这个能量函数求导时,神奇的事情发生了:标准的 $Query-Key-Value$ 结构自然涌现,Softmax 操作变成了能量最小化的必然结果。这意味着,Transformer 里的注意力机制,本质上是在通过拉近相关 Token 的距离来降低系统的“总能量”。
2. 前馈网络即能量 (Feedforward Energy)
同样的,前馈网络(FFN)也可以被视作另一个能量项 $E^{\mathrm{FF}}$ 的梯度。任何关于 Token 的加性标量函数都可以作为有效的 FFN 能量。
3. 归一化的物理意义
我们知道 Transformer 离不开 LayerNorm 或 RMSNorm。在 NRGPT 中,这些归一化操作不再是单纯的数值稳定技巧,而是对“推理率” $\mathbf{\eta}$ 的约束。
论文中的 命题 2.1 证明:只要推理率矩阵 $\mathbf{\eta}$ 满足特定条件(与归一化参数相关),NRGPT 的每一步更新都能保证总能量 $E$ 单调下降(或在短暂波动后下降)。这为大模型的推理过程提供了坚实的数学保障——Token 的生成不再是黑盒的跳跃,而是沿着能量曲面稳步滑向“最优解”。
实验表现:抗过拟合的意外之喜
NRGPT 本质上是一种循环神经网络(Recurrent Neural Network),因为它在每一步“层”的更新中复用相同的能量函数(即权重共享)。研究团队在 ListOps(代数任务)、Shakespeare(莎士比亚文集)和 OpenWebText 上进行了测试。
能量轨迹的可视化
为了验证理论,研究者可视化了 Token 在推理过程中的能量变化。
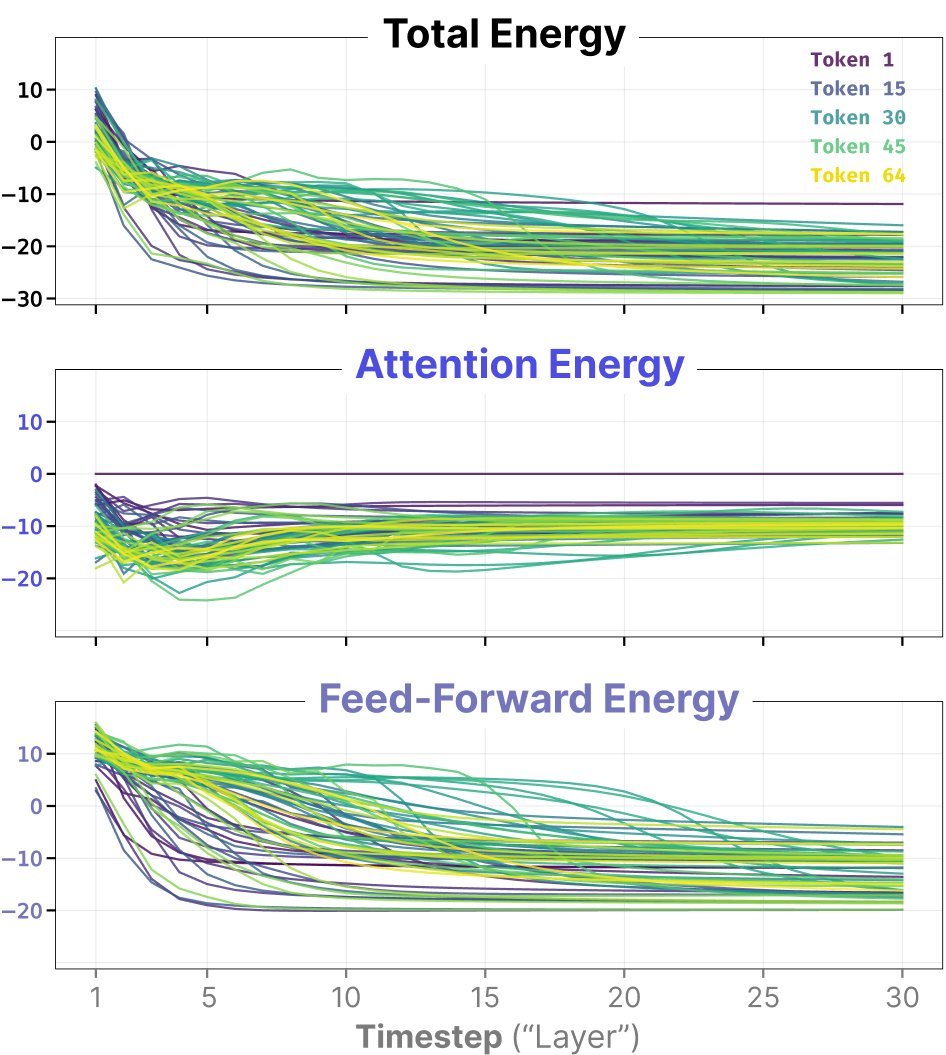
图 2:NRGPT 中 Token 的能量轨迹。可以看到,在经过短暂的瞬态阶段后,随着推理步数(层数)的增加,Token 的能量确实在单调下降,最终收敛到稳定的低能量状态。
性能与抗过拟合
在性能上,NRGPT 与参数量相当的 循环 GPT(Recurrent GPT)表现持平。但在莎士比亚数据集的实验中,研究者发现了一个有趣的现象:
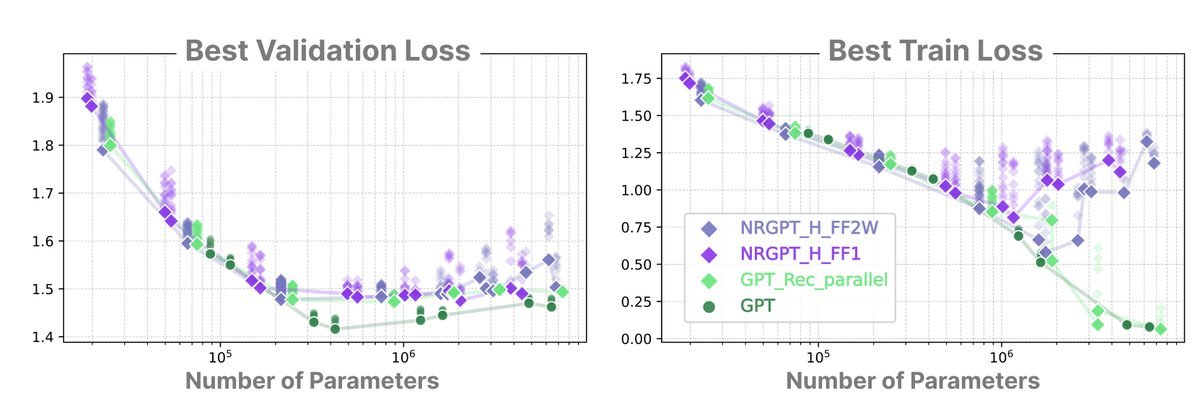
图 3:莎士比亚数据集上的 Scaling 表现。注意看右侧的大参数量区域,标准 GPT(蓝色)和循环 GPT(橙色)在训练后期容易出现过拟合(验证集 Loss 上升),而 NRGPT(红色/紫色)则表现出了更强的鲁棒性。
研究团队观察到,NRGPT 在大规模参数下似乎对过拟合具有天然的抵抗力。这可能归功于能量框架对参数空间的隐式约束,使得模型不会轻易记死训练数据,而是学习数据背后的能量分布。
总结与展望
NRGPT 为我们理解大语言模型提供了一个全新的物理视角。它告诉我们,Transformer 的成功可能并非偶然,其架构内部隐含着物理学中“能量最小化”的普适原理。
尽管目前 NRGPT 由于权重共享的限制(Recurrent 性质),在灵活性上还不如这种“每层权重都不同”的标准深层 Transformer,但它带来了两个重要的启示:
-
理论统一:成功将 GPT 纳入了 EBM 的严谨数学框架。
-
训练稳定性:展示了基于能量的动力学在防止过拟合方面的潜力。
未来的 LLM 会不会从“层层堆叠”转向“能量演化”?NRGPT 迈出了极具探索性的一步。