NVIDIA Nemotron 3: Efficient and Open Intelligence
英伟达Nemotron 3发布:Mamba+MoE混合架构,百万上下文与NVFP4训练揭秘

在大模型领域,”堆算力”似乎已成常态,但英伟达(NVIDIA)刚刚发布的研究展示了另一条路径:通过架构创新实现极致效率。NVIDIA Nemotron 3 系列模型(Nano, Super, Ultra)横空出世,它不仅是一个新的模型家族,更是对当前主流架构的一次大胆挑战——它抛弃了纯Transformer结构,转而采用了 混合Mamba-Transformer架构。
ArXiv URL:http://arxiv.org/abs/2512.20856v1
这一系列模型不仅支持高达 100万Token 的上下文窗口,更在推理吞吐量和准确性之间取得了惊人的平衡。特别是Super和Ultra版本,更是引入了 NVFP4训练 和 LatentMoE 等前沿技术。本文将带你深入解读Nemotron 3背后的硬核技术。
混合架构:Mamba与MoE的强强联手
Nemotron 3 最核心的创新在于其架构设计。为了在推理效率(特别是长文本推理)和模型性能之间找到最优解,该研究并未采用标准的Transformer,而是设计了一种 混合Mamba-Transformer专家模型 (Hybrid Mamba-Transformer MoE)。
传统的Transformer模型在生成过程中,KV Cache会随着序列长度线性增长,导致显存占用和计算量激增。而 Mamba-2 层(基于状态空间模型)在生成时只需要存储恒定的状态,极大地降低了推理成本。
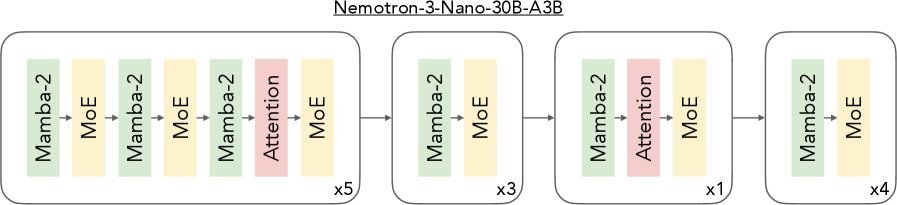
Nemotron 3 的策略是:
-
主要使用Mamba-2层:与MoE层交替,负责高效的序列建模。
-
保留少量Attention层:仅在关键位置插入自注意力层,以确保高质量的全局信息路由。
-
稀疏参数扩展:利用MoE架构,在不增加推理计算量的前提下大幅扩展模型参数容量。
这种设计使得Nemotron 3在保持高精度的同时,实现了”同类最佳”的推理吞吐量。
LatentMoE:硬件感知的专家设计
在Super和Ultra模型中,英伟达引入了一种名为 LatentMoE 的新颖方法,旨在提升”每字节的准确性”。
传统的 混合专家模型 (Standard MoE) 通常使用较大的隐藏层维度和较少的专家数量。而LatentMoE则反其道而行之,它使用较小的潜在维度(latent dimension $\ell=1024$)和更多的专家总数(512个专家,激活22个),相比之下标准MoE可能使用 $d=4096$ 和128个专家。
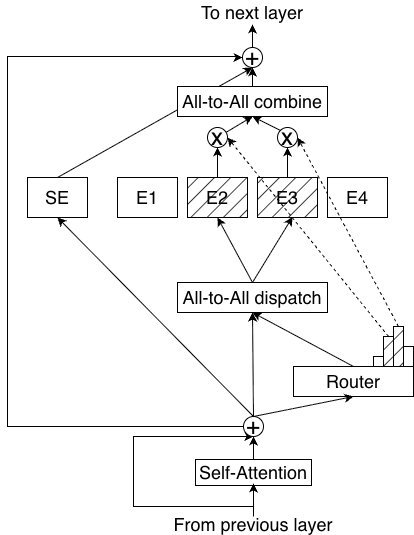
(a) Standard MoE architecture.
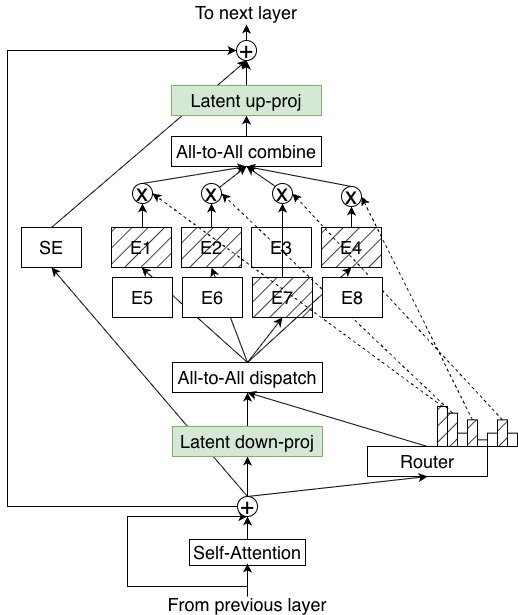
(b) LatentMoE architecture.
实验数据显示(见表1),在参数总量(73B)和激活参数量(8B)相同的情况下,LatentMoE在代码、数学和常识理解任务上全面超越了标准MoE架构。这证明了通过细粒度的专家划分,模型可以更高效地利用参数空间。
NVFP4训练:压榨硬件极限
作为GPU霸主,英伟达在模型训练上也展示了其硬件优势。Nemotron 3 Super和Ultra模型使用了 NVFP4 数据格式进行训练。
这并非简单的模拟,而是真正的原生支持。权重、激活和梯度张量都被量化为NVFP4格式,利用了Blackwell架构(如GB200)上NVFP4 GEMM的高吞吐能力(峰值吞吐量是FP8的3倍)。
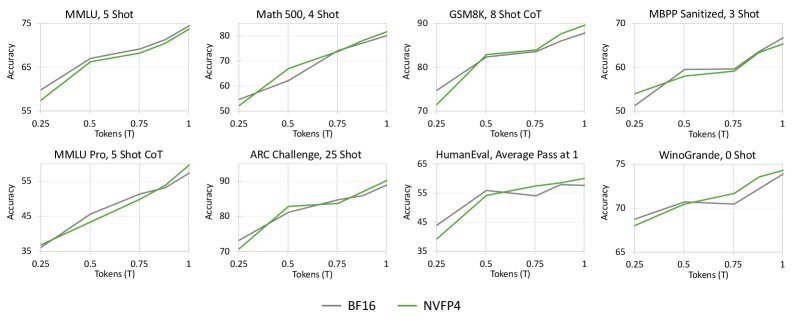
大家最关心的问题是:精度损失大吗?
研究结果令人惊喜。如图4所示,在Nano模型上,NVFP4与BF16的相对Loss差距小于1%;而在更大的8B激活参数MoE模型上,这一差距进一步缩小至 0.6% 以下。这再次印证了一个趋势:模型越大,对量化带来的精度损失越不敏感。
100万上下文与推理预算控制
Nemotron 3 支持长达 100万Token 的上下文窗口。这里有一个架构带来的天然优势:由于Mamba层提供了隐式的相对位置信息,Nemotron 3 的Attention层不需要使用旋转位置编码(RoPE)。这意味着模型在扩展上下文时,不会遇到RoPE常见的”外推”难题。
此外,该系列模型还引入了类似OpenAI o1的 推理预算控制 (Reasoning Budget Control)。
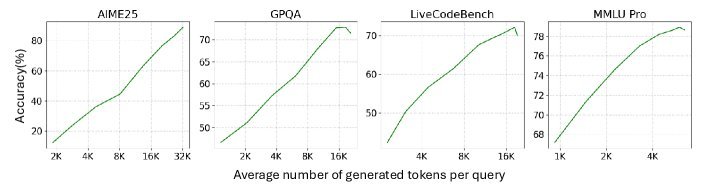
通过多环境强化学习(Multi-environment RL)后训练,模型学会了使用 \(</think>\) Token。用户可以在推理时指定”思考预算”(即允许模型生成多少思考Token),从而在响应速度和推理深度之间进行精细的权衡。如图8所示,随着思考预算的增加,模型在复杂任务上的准确率呈现明显的上升趋势。
总结
Nemotron 3 不仅仅是英伟达发布的一组新模型,它更像是一份关于”未来高效模型该长什么样”的技术白皮书。通过 Mamba+MoE混合架构、NVFP4训练 以及 多Token预测 (MTP) 等技术的组合,Nemotron 3 在保持开放(权重、数据、配方全开源)的同时,将AI的效率推向了新的高度。目前Nano版本已发布,更强大的Super和Ultra版本将在未来几个月陆续登场。