破解AI智能体训练“死亡螺旋”:LLDS让Qwen2.5性能大涨37.8%

当AI智能体(Agent)学会使用搜索引擎等外部工具时,它们解决复杂问题的能力将发生质的飞跃。然而,一条“捷径”式的训练方法——组相对策略优化(Group Relative Policy Optimization, GRPO)却隐藏着一个致命缺陷:模型在训练中常常毫无征兆地“突然死亡”,性能一落千丈。
ArXiv URL:http://arxiv.org/abs/2512.04220v1
这究竟是为什么?最近,来自UBC、UC Berkeley等顶尖机构的研究者们,终于揪出了导致这场“悲剧”的幕后黑手,并提出了一种极其简单有效的“解药”,不仅稳定了训练过程,还让Qwen2.5系列模型在多项问答任务上性能飙升,最高提升达37.8%!
AI智能体的“阿喀琉斯之踵”:GRPO与训练崩溃
让大模型学会使用工具,强化学习(RL)是一条必经之路。
GRPO因其收敛快、无需价值函数等优点,在工具集成强化学习(Tool-Integrated Reinforcement Learning, TIRL)领域备受青睐,知名工作Search-R1就采用了该方法。
然而,美好的表象下是残酷的现实。
研究人员发现,使用GRPO训练的智能体,尤其是在需要多轮工具交互的复杂任务中,经常会遭遇灾难性的训练崩溃。
模型奖励值会突然断崖式下跌,仿佛一夜之间忘记了所有技能。
尽管人们早已观察到这一现象,但其背后的根本原因一直是个谜。
揭开谜底:懒惰似然位移与“死亡螺旋”
这篇研究首次系统性地指出了问题的根源:懒惰似然位移(Lazy Likelihood Displacement, LLD)。
这是一个听起来有点拗口,但现象却非常直观的概念。
简单来说,就是在GRPO的优化过程中,模型对正确答案和错误答案的“信心”(即生成概率的似然值)都出现了停滞甚至系统性下降。
整个过程可以分为三个触目惊心的阶段:
-
早期停滞:训练初期,尽管任务奖励在上升,但正确答案的似然值却原地踏步。
-
稳定衰减:随着训练进行,似然值开始单调下降,危险信号已经出现。
-
加速崩溃:似然值急剧下跌,导致梯度爆炸,最终引发奖励雪崩。
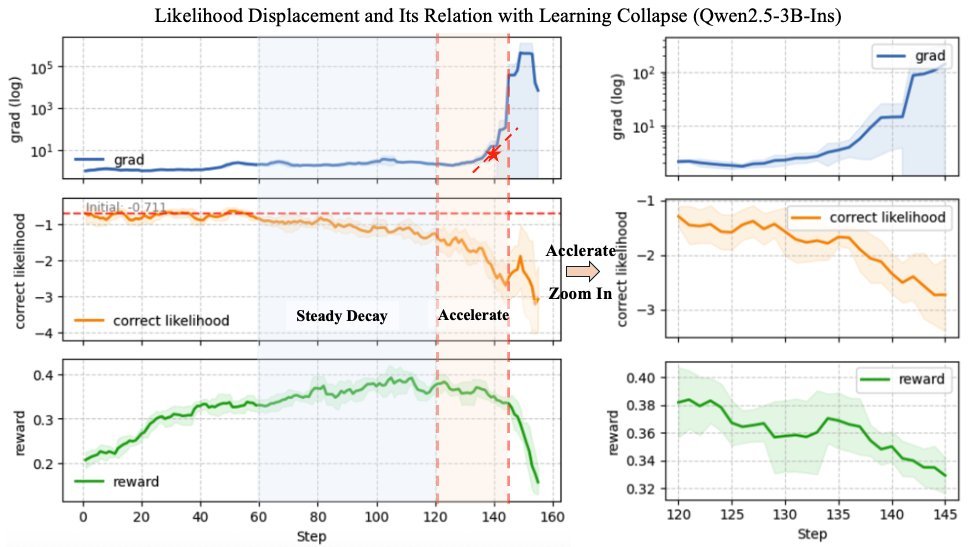
研究者将这个自我强化的恶性循环命名为LLD死亡螺旋(LLD Death Spiral):
似然下降 ➡️ 模型信心不足 ➡️ 来自低似然错误答案的负梯度被放大 ➡️ 进一步扼杀正确答案的似然 ➡️ 梯度爆炸 ➡️ 彻底崩溃!
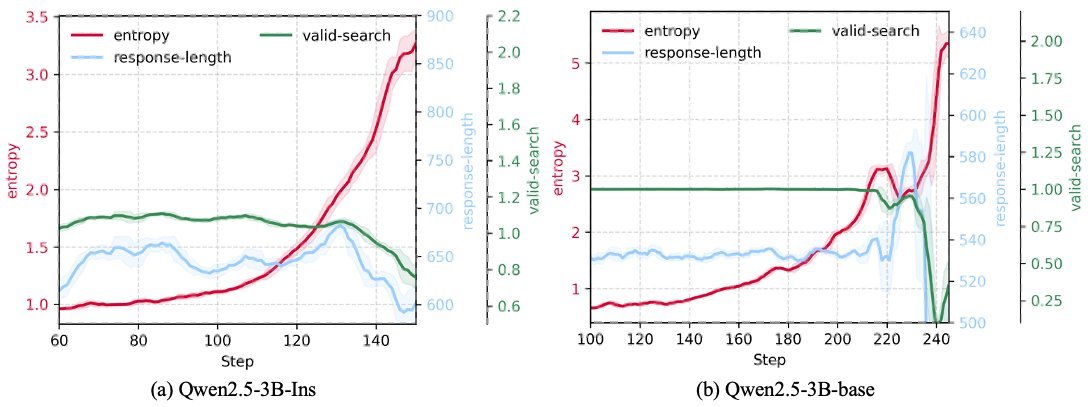
如下图所示,在崩溃前夕,模型的熵(不确定性)会急剧飙升,这正是LLD问题恶化的一个明确信号。
精准“手术”:轻量级正则化方法LLDS
找到了病因,如何对症下药?研究者提出了一种名为LLDS(Likelihood-Preserving Regularization)的轻量级似然保持正则化方法。
LLDS的设计堪称“外科手术”般的精准与优雅。
它只在必要的时候、对必要的部分进行干预,其核心是两层巧妙的选择机制:
-
响应级门控:只在一个轨迹(response)的整体似然值下降时,正则化项才会被激活。
-
令牌级选择性:激活后,只惩罚那些导致似然下降的特定Token。
用公式表达其核心思想如下:
\[L\_{\rm LLDS} = \mathbf{1}\!\left[\Delta\_{\text{total}} > 0\right] \cdot \sum\_{y\_{i}\in\mathbf{y}} \max\left(0, \Delta\_{y_i}\right)\]其中$ \mathbf{1}[\cdot] $是响应级门控,只有当整个响应的似然下降时($\Delta_{\text{total}} > 0$)才生效。而$ \max(0, \cdot) $则保证只对似然下降的Token($\Delta_{y_i} > 0$)施加惩罚。
这种“点到为止”的设计,既能有效阻止似然值的无故下滑,又最大限度地减少了对GRPO正常优化的干扰。
效果惊人:全面稳定与性能飞跃
LLDS的效果立竿见影。
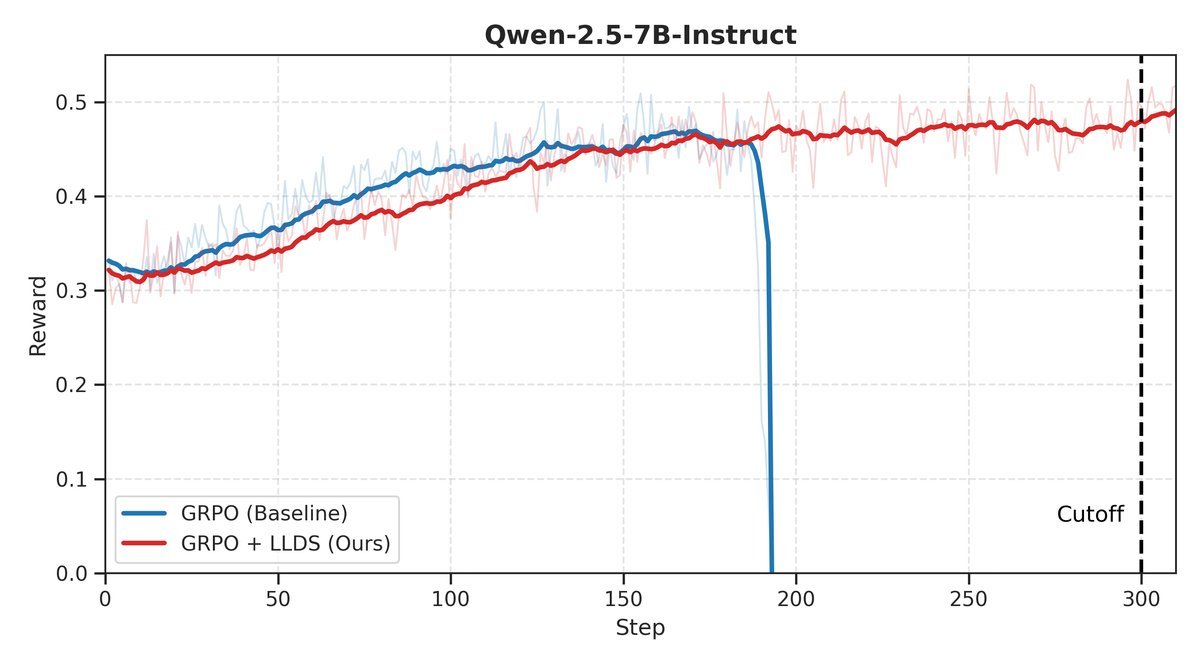
研究者在Qwen2.5-3B和7B的Base与Instruct版本上进行了实验。结果显示,原生的GRPO训练无一例外地在300步内崩溃。
而加入了LLDS之后,所有模型的训练都变得异常稳定,奖励持续攀升,成功摆脱了“死亡螺旋”的宿命。
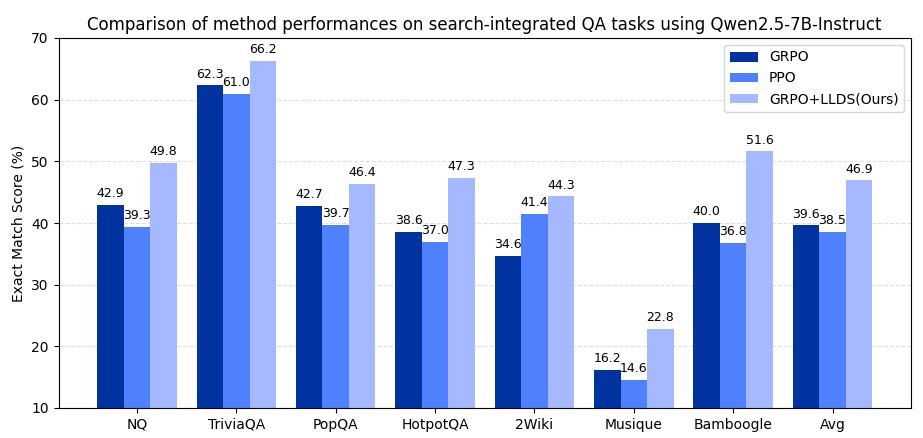
更重要的是,稳定的训练带来了实打实的性能提升。
在覆盖通用问答和多跳问答的7个基准测试中,LLDS方法取得了全面胜利。
-
在Qwen2.5-3B模型上,性能平均提升+37.8%。
-
在Qwen2.5-7B模型上,性能平均提升+32.0%。
这些数据雄辩地证明,LLDS不仅是GRPO的“救星”,更是释放其潜力的“催化剂”。
结语
这项研究不仅为我们揭示了GRPO在工具集成场景下频繁崩溃的深层原因——懒惰似然位移(LLD),还提供了一个即插即用、效果显著的解决方案LLDS。
它也给所有AI研究者和工程师带来了一个重要的启示:在训练AI智能体时,别只盯着奖励曲线!
似然值的动态变化是更早、更可靠的“健康晴雨表”。通过监控并维持似然值的稳定,我们才能构建出更强大、更可靠的AI智能体,让它们在通往通用人工智能的道路上行稳致远。