LLM越大越强?谷歌DeepMind等雄文揭示其5大“理论天花板”

“大力出奇迹”——这似乎已成为AI领域的黄金法则。从GPT-1的1.17亿参数到GPT-4的万亿级别,模型规模的指数级增长带来了惊人的能力涌现。我们似乎相信,只要数据够多、参数够大,一切问题都能被“暴力”解决。
ArXiv URL:http://arxiv.org/abs/2511.12869v1
然而,一篇由谷歌DeepMind、Meta、斯坦福等多家顶尖机构联合发表的论文,为这股狂热的“规模崇拜”踩下了理论的刹车。研究指出,LLM的性能提升并非无限,而是受制于五个根本性的“理论天花板”。
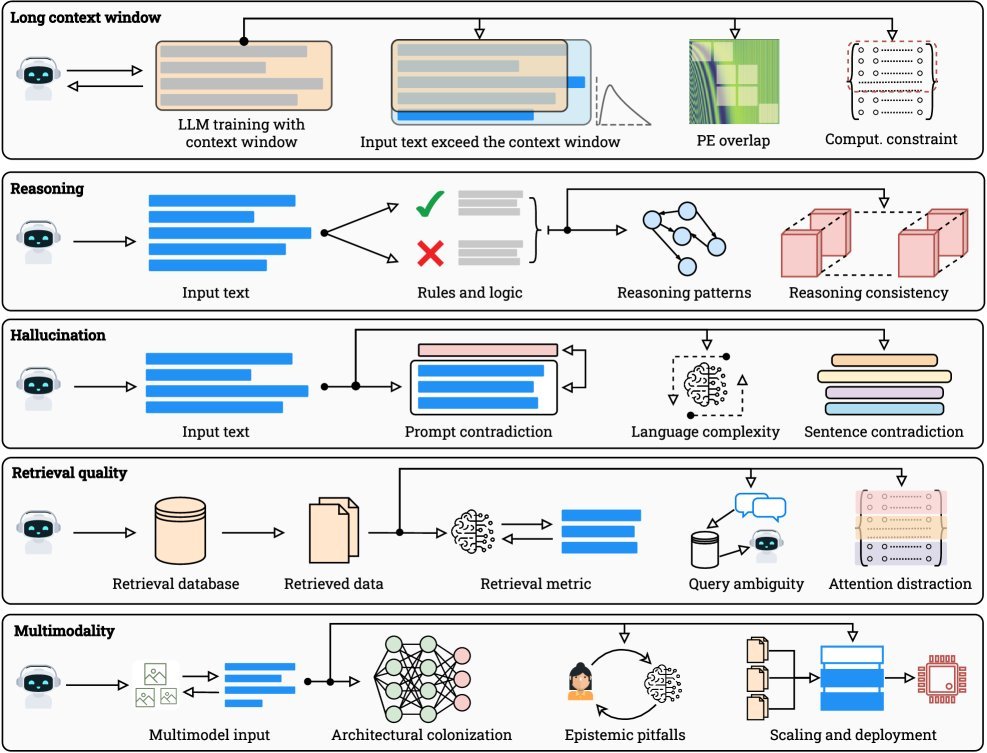
这篇雄文系统性地论证了,无论模型如何扩展,都无法完全摆脱这些与生俱来的枷锁。
LLM无法逾越的五大极限
该研究确定了五个相互关联、且无法仅通过扩大规模来解决的核心限制:
-
幻觉 (Hallucination):模型会“一本正经地胡说八道”。
-
上下文压缩 (Context Compression):长达百万的上下文窗口,有效利用率却远低于此。
-
推理退化 (Reasoning Degradation):模型更擅长模式匹配,而非真正的逻辑推理。
-
检索脆弱性 (Retrieval Fragility):RAG系统在检索和整合信息时存在固有缺陷。
-
多模态错位 (Multimodal Misalignment):语言和视觉等不同模态的信息难以完美对齐。
本文将重点解读论文中关于“幻觉”的深刻剖析,看看为何它是LLM无法根除的原罪。
为何幻觉无法根除?三大理论极限
许多人认为幻觉是数据不足或对齐不够导致的工程问题。但该研究从数学和理论层面证明,幻觉是不可避免的。
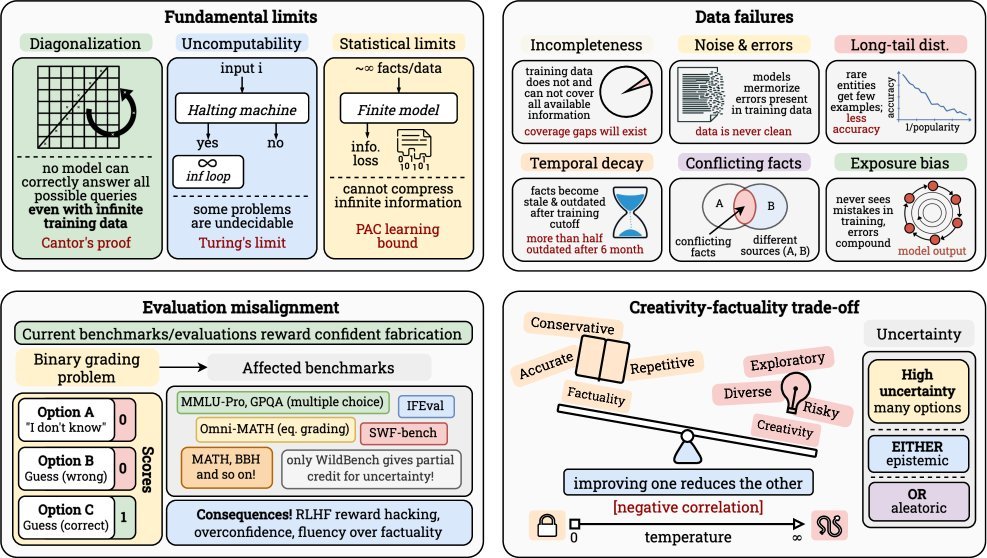
1. 可计算性与不可计算性边界
首先是可计算性理论(Computability Theory)的限制。一个惊人的结论源于哥德尔和图灵的理论:
-
对角论证(Diagonalization):对于任何一个可被列举出来的LLM模型集合,我们总能构造出一个“刁钻”的问题,使得集合中的每一个模型都会出错。这意味着不存在一个“全知全能”的LLM。
-
不可判定问题(Undecidable Problems):像著名的“停机问题”(Halting Problem)在理论上是无法被任何算法解决的。当LLM被问及这类问题时,它要么拒绝回答,要么必然产生幻觉。
简单说,LLM作为一种计算设备,其能力有着数学上的明确边界。
2. 信息论与统计学限制
即便问题是可计算的,信息和统计规律也给出了另一重枷锁。
-
信息瓶颈:任何有限大小的模型(无论参数多大),其描述能力都是有限的。它无法无损地压缩和存储世界上无限的知识。就像用一张有限大小的图片去完美表示一幅无限细节的画,信息丢失和失真是必然的。
-
样本复杂度:要让模型准确记住所有“长尾知识”(即罕见事实),理论上需要天文数字般的训练样本。例如,要让模型对 $m$ 个独立事实的错误率低于 $\epsilon$,所需的样本量 $n$ 与 $m$ 成正比,即 $n = \Omega(m/\epsilon^2)$。这在实践中几乎不可能实现。
数据原罪:不完美的世界,不完美的模型
理论极限设定了幻觉的下限,而训练数据中的固有缺陷则在现实中将这个问题无限放大。
-
不完整与过时:训练数据只是世界的一个有限快照。知识在不断更新,而模型却被“困在”了过去。如下图所示,时效性强的信息在短短6个月后,其有效性就可能下降到50%以下。
-
噪声与长尾效应:网络数据充斥着错误、偏见和矛盾信息。同时,知识分布极不均衡,模型对高频知识滚瓜烂熟,对低频的“长尾”知识则常常出错。
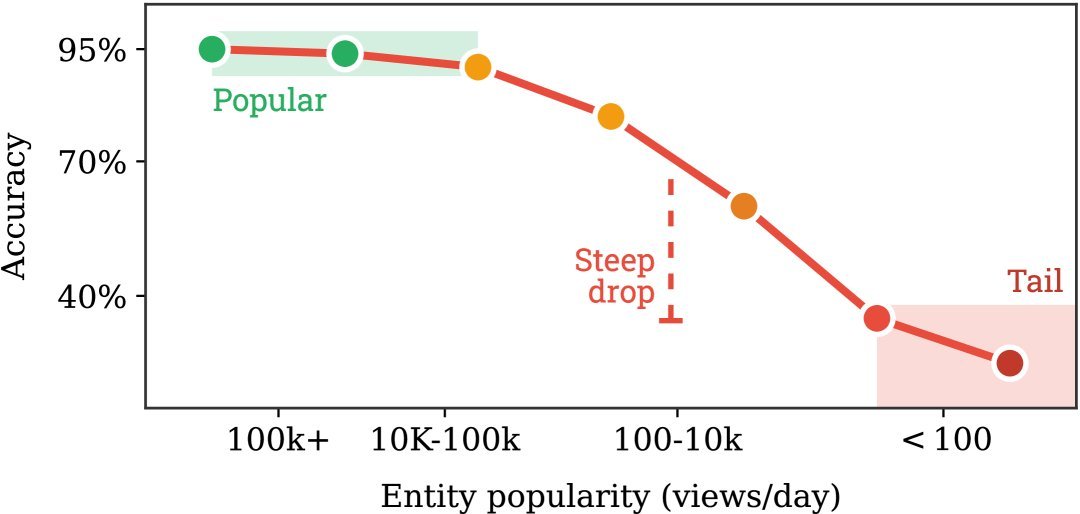
上图(a)显示,模型对热门实体(每天超10万次浏览)的准确率超过95%,但对冷门实体(每天少于100次浏览)的准确率骤降至40%以下。这清晰地揭示了数据分布不均带来的影响。
评估的陷阱:当“我不知道”成为一种惩罚
当前的评测体系也在无形中“鼓励”幻觉。
在MMLU、GPQA等主流基准测试中,回答“我不知道”和自信地编造一个错误答案,得到的分数都是零。这种机制激励模型去猜测,而不是诚实地表达不确定性。
此外,基于人类反馈的强化学习(RLHF)也可能加剧问题。人类标注者倾向于偏爱流畅、自信的回答,这使得模型学会了“粉饰太平”,即使内心不确定,也要表现得胸有成竹。这种“奖励黑客”(Reward Hacking)行为,让模型成了更会骗人的“自信的撒谎者”。
超越“大力出奇迹”
这篇论文并非唱衰LLM,而是为我们提供了一个更清醒、更科学的视角。它用严谨的理论框架告诉我们,AI的发展并非只有“扩大规模”一条路。
理解这些根本性限制,才能让我们摆脱对“大力出奇迹”的盲目信仰。幻觉、上下文压缩、推理退化等问题,是深植于计算、信息和学习理论本身的挑战。
未来的研究方向,或许不应仅仅是堆砌更多的参数和数据,而应更多地探索新的架构(如稀疏或层级注意力)、新的训练范式(如位置课程学习)和新的应用模式(如引入外部验证工具),从而在理论天花板之下,找到更智能、更可靠的路径。