CMU揭秘大模型推理训练“三部曲”:性能飙升60%的黄金法则

强化学习(RL)真的能教会大模型新的推理能力,还是仅仅在“抛光”它已有的知识?尽管像DeepSeek和OpenAI的o1这样的模型通过RL在推理上取得了惊人进展,但这个根本问题一直悬而未决。
ArXiv URL:http://arxiv.org/abs/2512.07783v1
其中的一大挑战是,现代大模型的训练过程就像一个“黑箱”。我们不清楚海量的预训练数据里到底包含了什么,这使得我们很难判断,模型推理能力的提升究竟是RL的功劳,还是仅仅激活了预训练时就已学会的潜能。
为了拨开这层迷雾,卡内基梅隆大学(CMU)的研究者们设计了一套堪称“洁癖”的实验框架。他们通过完全可控的合成数据,首次清晰地剖析了预训练(Pre-training)、中训练(Mid-training)和强化学习后训练(RL-based Post-training)这“三部曲”在塑造模型推理能力时各自扮演的角色,并得出了颠覆性的结论。
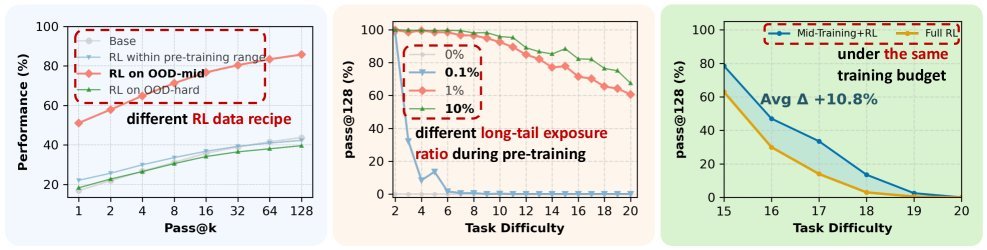
图1:论文核心发现概览。左:RL仅在任务难度略超预训练范围时才产生真正的外推收益(校准后最高提升42%)。中:只需极少量(≥1%)的预训练曝光,RL就能实现强大的跨情景泛化(最高提升60%)。右:在固定算力下,加入中训练阶段比单独使用RL在OOD任务上性能高出10.8%。
为大模型推理能力打造一个“受控实验室”
要精确测量每个训练阶段的贡献,就必须摆脱真实世界语料的“污染”和不可控性。该研究为此构建了一个精巧的合成数据生成框架。
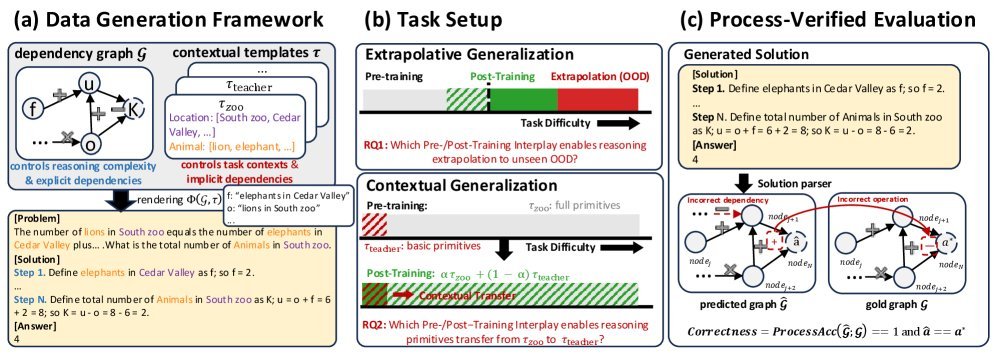
图2:数据生成、任务设置与过程验证评估框架概览。
这个框架的核心思想是:
-
结构与情景分离:每个推理问题都源自一个有向无环图(DAG),它定义了推理的逻辑结构。而具体的故事背景、人物和数字则像是“皮肤”,可以随时替换。
-
难度精确控制:通过增减DAG中的计算步骤数量($op(\mathcal{G})$),可以精确控制问题的推理深度。
-
过程可验证:由于每个问题的正确推理步骤都是已知的,模型不仅要给出正确答案,其推理过程的每一步也必须正确,从而杜绝“蒙对答案”的现象,即过程验证(Process Verification)。
基于此,研究者们从两个维度评估模型的泛化能力:
-
外推泛化(Extrapolative Generalization):模型能否解决比训练中见过的更复杂(推理步骤更多)的问题?
-
情景泛化(Contextual Generalization):模型能否将学到的推理逻辑应用到从未见过的新故事背景中?
RL的“甜蜜点”:在能力边界上实现突破
第一个关键问题是:RL究竟在什么时候才能带来真正的能力提升?
实验发现,RL并非万能药。它的效果高度依赖于两个前提条件:
-
预训练留有“进步空间”:如果一个任务在预训练阶段就已经被模型基本掌握,那么RL能带来的提升微乎其微,更多是“锦上添花”。
-
RL数据位于“能力边界”(Edge of Competence):RL训练数据不能太简单(模型已掌握),也不能太难(模型完全无法理解)。只有当任务难度恰好处于模型“跳一跳才能够得着”的区域时,RL才能发挥最大作用,实现真正的能力外推。
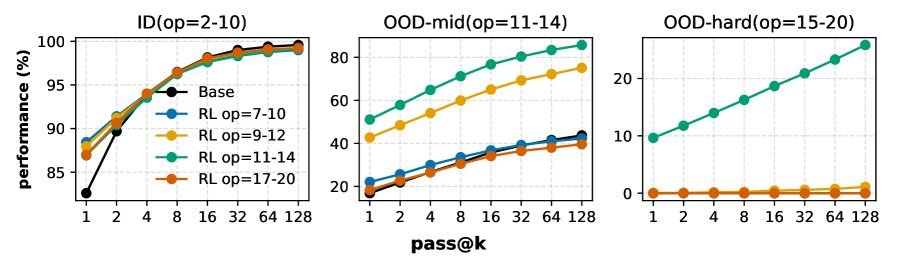
图3:RL在外推泛化中的作用。当RL数据(op=11-12)处于模型能力边界时,性能提升最显著(+42% pass@128)。
当这两个条件被满足时,RL能够带来高达 42% 的性能提升(pass@128)。这澄清了业界关于RL效果的争议:它既不是万能的创造者,也不是简单的精炼器,而是一个依赖于特定条件的“能力放大器”。
预训练“播种”:为RL的成功奠定基础
既然RL的成功有赖于基础,那么预训练需要做到什么程度呢?
研究发现,RL无法凭空创造能力。要想让模型在新的情景下也能正确推理,预训练数据中必须包含相应推理技能的“种子”。
令人惊讶的是,这个“种子”不需要很多。实验表明,即使某个情景在预训练数据中只出现了 1% 的极低频率,也足以让RL在此基础上进行有效泛化,最终在新情景的复杂任务上取得高达 60% 的性能飞跃。
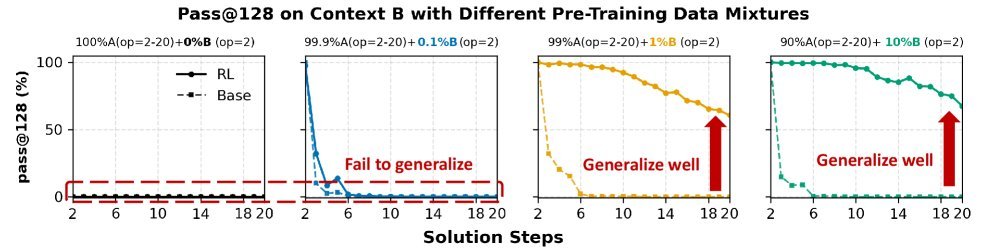
图4:预训练曝光对情景泛化的影响。即使只有1%的稀疏曝光,RL也能实现强大的跨情景泛化。
这个发现为数据策略提供了重要指导:与其追求在预训练阶段覆盖所有复杂的长尾场景,不如确保基础推理原语和技能有广泛但稀疏的覆盖。
被忽视的“中场发动机”:中训练的关键作用
在预训练和RL后训练之间,还有一个经常被忽视的阶段——中训练(Mid-training),有时也称为持续预训练(CPT)。它的作用是在大规模、通用的预训练和高度专业化的RL之间架起一座桥梁。
研究表明,这个“中间阶段”的作用远超想象。在固定的总算力预算下,将一部分算力分配给中训练,另一部分给RL,其效果远胜于将所有算力都用于RL。
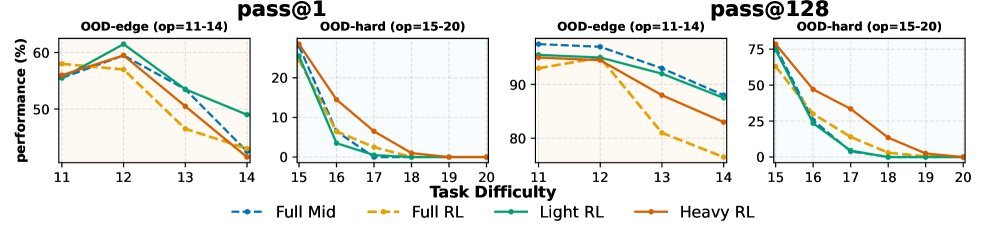
图6:中训练与RL的协同作用。在固定算力下,“中训练+RL”的组合在难任务上的表现比“仅RL”高出10.8%。
具体来说,在最具挑战性的域外高难度(OOD-hard)任务上,“中训练+RL”的组合比“仅RL”的方案性能高出 10.8%。这证明了中训练并非可有可无,而是在训练流程中扮演着巩固基础、承上启下的“中场发动机”角色。
超越正确答案:过程奖励对抗“奖励黑客”
传统RL通常只看最终答案是否正确(Outcome-based Reward),但这容易导致模型学会“奖励黑客”(Reward Hacking)——通过错误的、投机取巧的步骤得到正确答案。
为了解决这个问题,研究者将“过程验证”的思想引入奖励函数设计中,提出过程感知奖励(Process-aware Reward)。
\[R = \alpha R_{\text{out}} + (1-\alpha) R_{\text{pv}}\]这里的 $R_{\text{out}}$ 是传统的最终答案奖励,而 $R_{\text{pv}}$ 则是基于推理过程每一步正确性的“过程分”。实验证明,这种结合了过程监督的奖励机制能有效减少奖励黑客行为,提升模型推理的保真度和泛化能力。
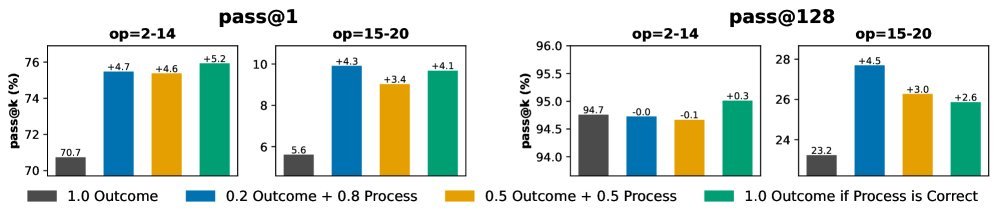
图7:过程奖励的效果。加入过程验证奖励后,模型在所有难度级别的任务上都表现出一致的性能提升。
结论
这项研究通过一个优雅的受控实验框架,清晰地揭示了大模型推理能力发展的“三部曲”:
-
预训练是“播种机”:它负责植入广泛的基础推理原语。哪怕覆盖率很低,也至关重要。
-
中训练是“助推器”:它在预训练和RL之间架起桥梁,巩固和扩展基础能力,性价比极高。
-
RL是“放大器”:它在模型的能力边界上效果最佳,能将已有的“种子”能力放大并组合,解决更复杂的问题。
这些发现为我们理解和构建更强大的推理大模型提供了宝贵的实践指南:与其盲目地堆砌数据和算力进行RL,不如精心设计预训练、中训练和RL的数据策略和算力分配,让每个阶段都发挥其最大效用。这或许就是通往更强通用人工智能的一条更清晰、更高效的路径。