AI效率万倍增长神话破灭?MIT研究:90%的功劳来自Transformer的规模效应

过去十年,人工智能的训练效率据称飙升了惊人的22000倍!这听起来像是无数算法天才夜以继日、不断堆砌微小创新共同铸就的奇迹。但事实果真如此吗?
ArXiv URL:http://arxiv.org/abs/2511.21622v1
来自MIT和Olin学院的一项最新研究,对这个“算法进步神话”提出了颠覆性的挑战。他们的结论可能会让你大吃一惊:所谓的万倍效率提升,绝大部分并非源于那些零敲碎打的优化,而是几乎完全归功于一个关键的、且极其依赖“暴力计算”的架构变革。
“微不足道”的创新:小模型上的真实收益
为了探究这22000倍效率增益的来源,研究者们首先采取了一种直接的方法:消融实验(ablation experiments)。
他们在一个360万参数的小型Transformer模型上,系统性地“关闭”了近年来被认为是重大进步的各项技术,想看看每一个到底贡献了多少。
这些技术包括:
-
更高效的激活函数,如从 $GeLU$ 到 $SwiGLU$。
-
更先进的位置编码,如从正弦编码到旋转位置编码(Rotary Positional Encoding, RoPE)。
-
更稳定的归一化技术,如从 $LayerNorm$ 到 $RMSNorm$。
-
更强大的优化器,如从 $SGD$ 到 $AdamW$。
结果令人震惊。如下图所示,即便是像从 $SGD$ 切换到 $Adam$ 这样公认的巨大改进,也只带来了不到 $2\times$ 的效率提升。而其他大部分创新的增益更是微乎其微。
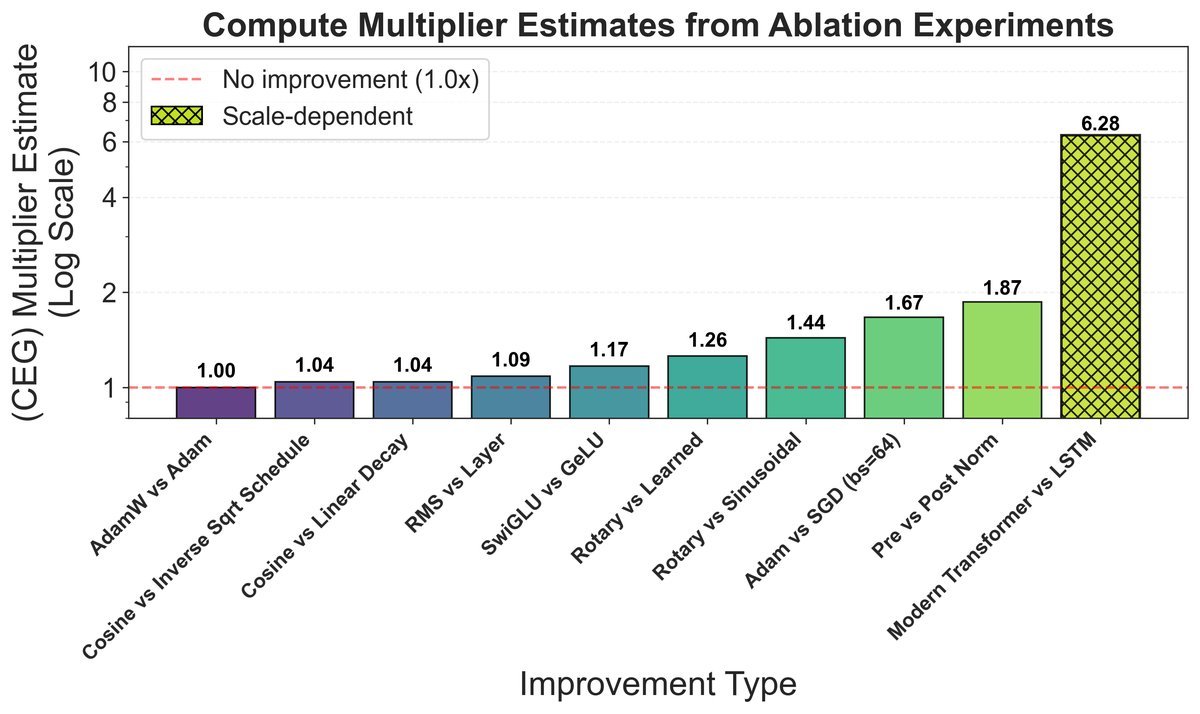
将这些在小模型上测得的、看似“重要”的创新全部加起来,总的效率增益还不到10倍!
这与22000倍的宏大叙事之间,存在着一道巨大的鸿沟。那么,丢失的那几个数量级的效率提升,究竟藏在哪里?
规模的魔力:当算法收益依赖“暴力”
研究者们意识到,问题可能出在一个被长期忽视的假设上:并非所有算法的优势都能在小规模下体现。有些进步是规模依赖的(scale-dependent)。
为了验证这一点,他们进行了一系列缩放实验(scaling experiments),比较了不同架构在计算资源不断增加时的性能表现。
这次,他们将目光投向了AI历史上最重要的一次架构交替:从LSTM到Transformer。
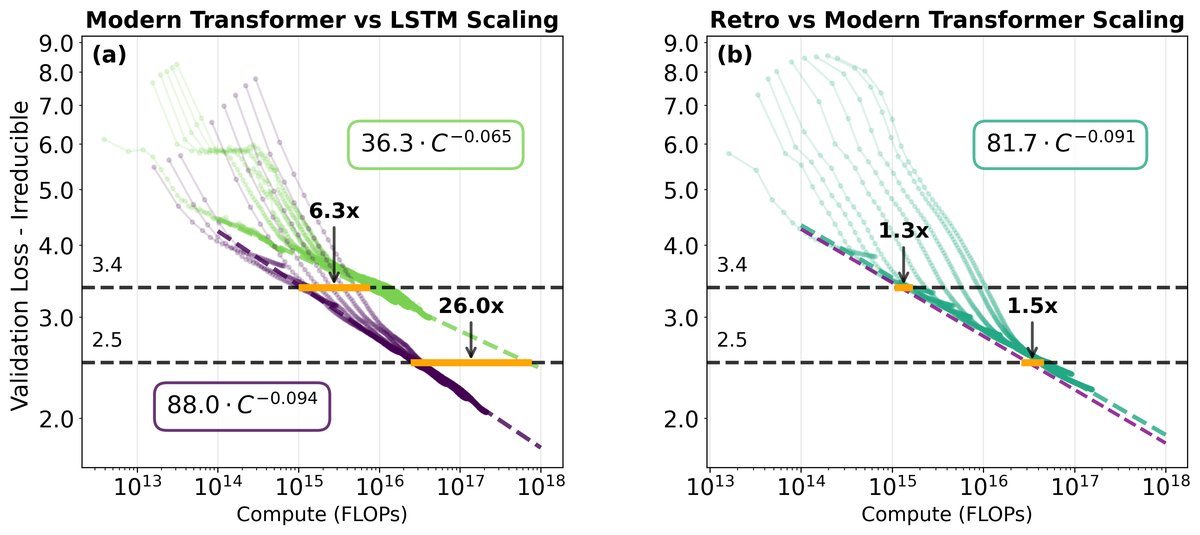
上图揭示了核心秘密。
左图(a)中,代表LSTM的绿线和代表Transformer的紫线,它们的斜率(即缩放指数)明显不同。随着计算量(横轴)的增加,两条线的差距越来越大。这意味着,Transformer相比于LSTM的效率优势,会随着计算规模的扩大而指数级增长!
而在右图(b)中,集成了多项改进的“现代Transformer”(紫线)与移除了这些改进的“复古Transformer”(蓝线)几乎是平行的。这证明了前一部分提到的那些小创新是规模不变的(scale-invariant),它们带来的效率提升是一个固定的常数,并不会随着模型变大而变得更强。
这一发现石破天惊:我们以为的许多“算法进步”,其实是Transformer架构在巨大计算规模下才能释放的潜力。
重新算笔账:两大“规模依赖型”进步
基于以上发现,研究团队重新构建了过去十年算法进步的全景图。他们发现,绝大部分效率增益主要来自两个具有强烈规模依赖性的变革:
-
从LSTM到Transformer的架构跃迁:这是最大的功臣。在小模型上,它的优势或许不明显,但在需要投入海量 $FLOPs$ 的前沿大模型上,它的效率优势被展现得淋漓尽致。
-
从Kaplan到Chinchilla的缩放法则:这关乎如何更优地分配计算资源给模型参数量和训练数据量。事实证明,采用Chinchilla(Chinchilla-scaling)提出的“数据与参数同步增长”策略,其效率红利同样会随着总计算量的增加而变大。
将这些因素综合考虑后,研究者们对算法进步的贡献进行了重新分解。
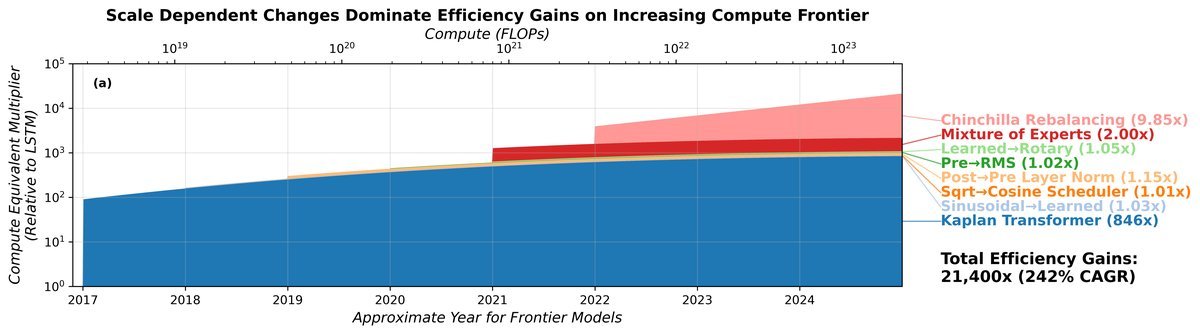
这张图清晰地显示,在迈向2025年计算前沿(约 $2 \times 10^{23}$ FLOPs)的过程中,从LSTM到Transformer的转变(图中橙色区域)占据了算法效率增益的绝大部分,估计贡献了超过90%!
最终,研究团队核算出的总效率增益约为6930倍,虽然仍是一个巨大的数字,但其构成与我们之前的想象完全不同。
结论:算法进步需要“大力出奇迹”
这项研究为我们描绘了一幅关于AI算法进步的全新图景:
它并非由无数微小创新平滑累积而成,而是由少数几次“革命性”的、且具有强烈规模依赖性的架构变革所驱动的。
这意味着,算法的进步与算力的增长是深度绑定的。许多最强大的算法创新,只有在巨大的计算尺度上才能完全释放其潜力。这也解释了为什么AI的发展越来越向拥有庞大计算资源的头部玩家集中。
下次当你再听到“算法效率提升XX倍”时,或许可以多问一句:这种提升,是在多大的计算规模上实现的?因为在这个时代,真正的“算法魔法”,似乎需要“暴力计算”作为施法材料。