MIT联手英伟达发布FlashMoBA:稀疏注意力提速14.7倍,长文本处理迎来新篇章

当大语言模型(LLM)试图理解长视频、分析海量文档时,一个巨大的瓶颈便显现出来:自注意力机制的计算成本会随序列长度二次方增长。为了解决这个问题,稀疏注意力应运而生,而混合块注意力(Mixture of Block Attention, MoBA)是其中的佼佼者。它通过一个智能“路由器”,让每个查询只关注少数几个关键信息块,从而大大降低计算量。
论文标题:Optimizing Mixture of Block Attention
ArXiv URL:http://arxiv.org/abs/2511.11571v1
然而,MoBA虽好,却面临两大难题:它的工作原理像个黑箱,没人说得清如何设计才最优;同时,它缺乏高效的GPU实现,导致理论上的优势在实践中大打折扣。
现在,来自MIT和NVIDIA的研究者们,不仅揭开了MoBA的神秘面纱,还为其插上了硬件加速的翅膀!
揭秘MoBA的“黑箱”:一个信噪比模型
MoBA成功的关键在于,它的路由器能否在成千上万个文本块中,精准地为查询找到那几个包含“真命天子”信息的块——这就像在草堆里找针。
为了搞清楚这个过程,研究者们建立了一个统计模型。模型的核心发现是,路由器的选择准确性由一个信噪比(Signal-to-Noise Ratio, SNR)决定:
\[\text{SNR} \propto \sqrt{\frac{d}{B}}\]其中,$d$是注意力头的维度,$B$是块(block)的大小。
这个简洁的公式带来了两个极其重要的设计原则:
-
减小块尺寸 $B$:块越小,信噪比越高,路由器就越容易区分相关信息和无关噪声。
-
增强信号:在Key上应用一个短卷积,可以帮助将相关的信号“聚集”起来,让路由器更容易发现。
简单来说,要想让MoBA更聪明,要么把“草堆”切得更小,要么让“针”变得更亮。
FlashMoBA:为理论插上实践的翅膀
理论上,小块(small block)效果更好,但在GPU上却是个灾难。小块意味着内存访问变得零散、不连续,路由开销剧增,导致GPU大量时间被浪费在等待数据上,实际速度甚至比不上传统的稠密注意力。
为了解决这个“理论与实践脱节”的问题,研究团队推出了 FlashMoBA——一个专为小块MoBA设计的、硬件感知的CUDA内核。
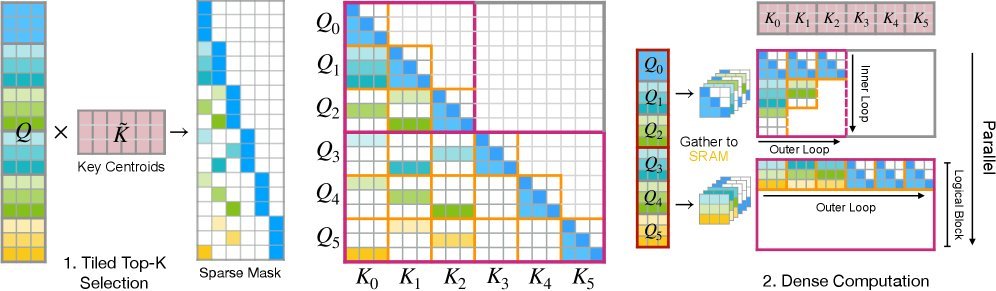
图1:FlashMoBA前向传播示意图。它通过“Tiled Top-k Selection”高效找到目标块,再用“Gather-and-Densify”策略将零散计算转化为密集的、对GPU友好的计算。
FlashMoBA的核心思想是“化零为整”,它通过以下设计克服了小块的性能瓶颈:
-
分块Top-k选择:它不再生成一个巨大的分数矩阵,而是在GPU片上内存中分块计算并选出Top-k,极大地减少了内存读写。
-
收集-稠密化(Gather-and-Densify):对于每个查询选中的稀疏块,FlashMoBA会将它们“收集”起来,在GPU内部形成一个临时的稠密矩阵,然后调用类似FlashAttention-2的高效逻辑进行计算。
这种设计最大化了内存访问的连续性和计算的并行度,让小块MoBA在GPU上也能飞速运行。
实验效果:质量与速度双丰收
理论和工程都到位了,实际效果如何?研究者们从头开始训练了多个模型进行验证。
1. 质量:小块尺寸显著提升性能
实验结果完美印证了SNR模型的预测。如下图所示,在3.4亿参数模型上,将块大小从512减小到128,模型的困惑度(Perplexity)和长文本检索(RULER)准确率都得到了显著改善。
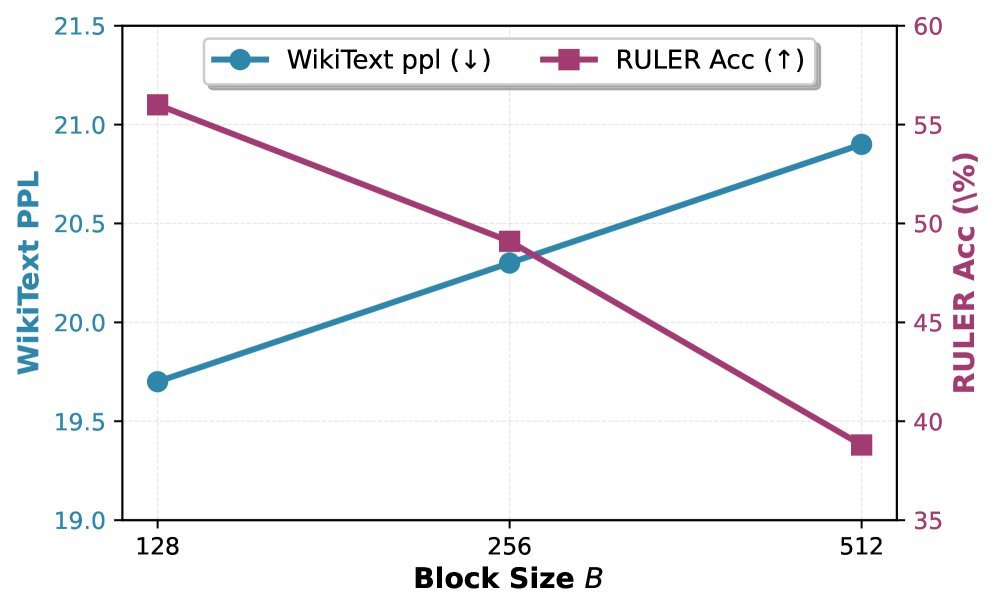
图2:更小的块尺寸($B$)带来了更低的困惑度和更高的RULER准确率。
更令人惊喜的是,经过优化的MoBA模型,其性能不仅没有因为稀疏化而下降,反而在多个基准测试中媲美甚至超越了计算量远大于它的稠密注意力模型!这证明了MoBA通过集中注意力,有效缓解了长文本中注意力“稀释”的问题。
2. 速度:最高14.7倍加速
FlashMoBA的性能表现堪称惊艳。在64K的长序列下,FlashMoBA比原始MoBA实现快7.4倍,内存占用减少6.1倍。
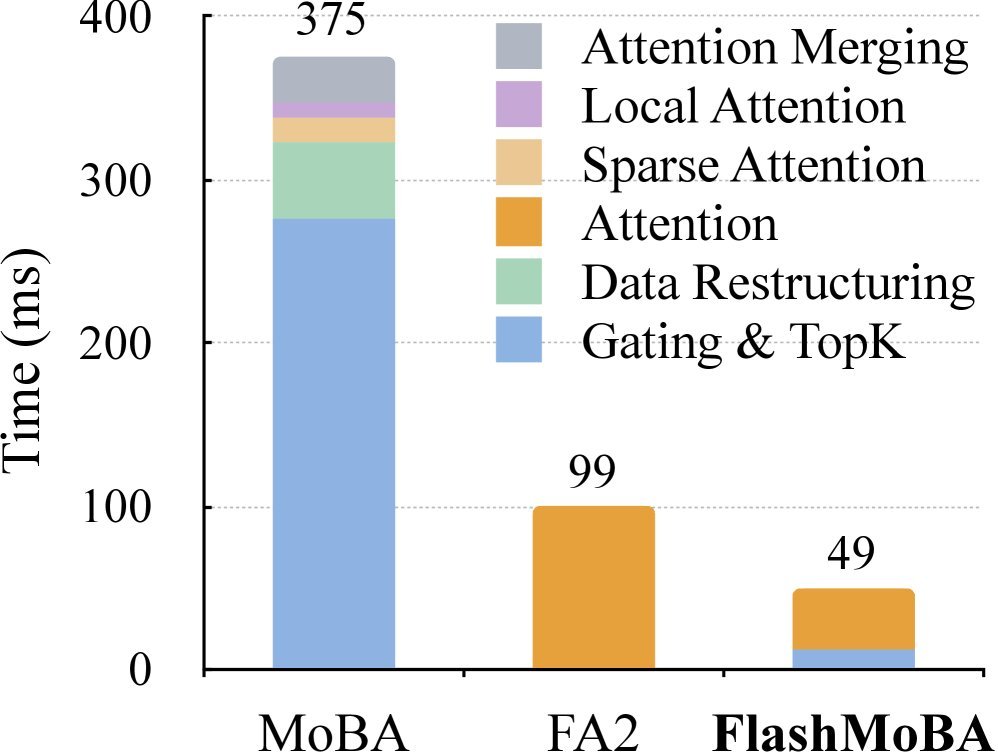
图4:在64K序列长度下,原始MoBA的开销主要在路由和索引上,而FlashMoBA通过融合内核大幅降低了这部分开销,总耗时甚至低于FlashAttention-2。
与业界标杆FlashAttention-2相比,FlashMoBA在处理长序列和小块时,最高可实现 14.7倍 的速度提升,同时将LLM的上下文处理能力扩展到512K甚至更长。
总结
这项研究为我们展示了一条清晰的路径:通过严谨的理论分析找到优化的方向,再结合高超的硬件感知工程实现,从而突破现有技术的瓶颈。
该研究提出的SNR模型揭示了MoBA的工作机理,而FlashMoBA内核则让理论上最优的设计在实践中变得可行。对于追求百万级甚至更长上下文窗口的AI应用而言,这项工作无疑是迈向未来的重要一步。