大模型推理太“话痨”?ORION压缩16倍思考路径,成本直降9倍

大模型在数学、编码等复杂推理任务上越来越强,但你是否注意到,它们为了得到正确答案,往往需要生成一段极其冗长的“思考过程”?这种“话痨式”推理不仅导致高昂的计算成本和延迟,还常常引入冗余甚至矛盾的步骤。
ArXiv URL:http://arxiv.org/abs/2511.22891v1
最近,来自哈佛、MIT和Hippocratic AI的研究者们给出了一个全新的解决方案——ORION。受人类“思维语言假说”的启发,该研究让大模型学会用一种极其压缩的符号语言进行思考,推理路径缩短4-16倍,推理延迟降低5倍,训练成本更是锐减7-9倍!最惊人的是,在如此高效的同时,它依然保持了原模型90-98%的准确率,甚至在部分数学基准上超越了GPT-4o和Claude 3.5 Sonnet。
“话痨”的困境:大模型为何想得太多?
自“思维链”(Chain-of-Thought, CoT)技术问世以来,让模型“想一步,说一步”已成为提升其推理能力的主流范式。像DeepSeek-R1、OpenAI o1等前沿模型,都依赖于生成详细的中间步骤来解决复杂问题。
然而,这种方式也带来了“过度思考”(Overthinking)的现象。如下图所示,即便是简单问题,模型也可能生成大量啰嗦、重复的文本,这与人类简洁、高效的思维方式形成了鲜明对比。

这种冗长不仅浪费Token,增加了推理时间和成本,还可能因为步骤过多而累积错误,反而降低准确性。如何让模型既能深思熟虑,又能言简意赅?这正是ORION要解决的核心问题。
Mentalese:一种为机器打造的“思维语言”
该研究的灵感来源于认知科学中的思维语言假说(Language of Thought Hypothesis)。该假说认为,人类的认知并非直接通过自然语言进行,而是在一种更抽象、更符号化的内部语言(称为Mentalese)上运作。
基于此,研究者们设计了一种名为Mentalese的紧凑符号推理格式。它摒弃了自然语言的繁琐,用一系列结构化的操作符(如\(SET\), \(CALC\), \(SOLVE\))和表达式来描述推理的核心逻辑。

一个Mentalese推理轨迹由一系列定义清晰的步骤组成,每一步都只包含解决问题所必需的核心信息。这种方式使得推理过程既高度压缩,又保持了逻辑的严谨性和可解释性。
两阶段训练法:从对齐到优化
为了让模型掌握这种高效的“思维语言”,ORION采用了一个巧妙的两阶段训练流程。
阶段一:监督微调(SFT)对齐Mentalese
首先,研究者构建了一个包含4万个数学问题的\(MentaleseR-40k\)数据集,其中每个问题都配有专家编写的Mentalese推理路径。
然后,他们使用这个数据集对预训练好的基础模型(如DeepSeek R1 Distilled 1.5B)进行监督微调(SFT)。目标是让模型学会模仿这种简洁的符号推理风格。
但这里出现了一个问题:SFT虽然成功地压缩了推理过程,却也导致了模型性能的大幅下降(平均准确率下降约35%)。这是因为严格的符号格式限制了模型在推理过程中的探索和自我修正能力。
阶段二:用SLPO进行强化学习
为了在不牺牲简洁性的前提下恢复模型性能,研究团队引入了强化学习,并提出了本文的核心创新之一:更短长度偏好优化(Shorter Length Preference Optimization, SLPO)。
传统的长度惩罚方法过于“一刀切”,可能会惩罚那些解决难题所必需的较长思考。而SLPO则聪明得多:
在模型为同一问题生成的多个正确的解决方案中,SLPO会给予最短的那个方案更高的奖励。
它的奖励函数设计如下:
\[R\_{\text{SLPO}}(y\_{\text{curr}})=\begin{cases}1,&\text{if } \mid \mathcal{C}(x\_{i}) \mid =1\ \text{or }\big( \mid \mathcal{C}(x\_{i}) \mid >1\ \text{\& }L\_{\min}=L\_{\max}\big),\[6.0pt] R\_{\text{correctness}}+\alpha\cdot\dfrac{L\_{\max}-L\_{\text{curr}}}{L\_{\max}-L\_{\min}},&\text{if } \mid \mathcal{C}(x\_{i}) \mid >1\ \text{and }L\_{\min}\neq L\_{\max},\[10.0pt] 0,&\text{if } \mid \mathcal{C}(x\_{i}) \mid =0,\end{cases}\]简单来说,如果所有正确答案一样长,或者只有一个正确答案,它们都会得到满分奖励。只有当存在多个长度不同的正确答案时,SLPO才会偏爱更短的那个。这种自适应的奖励机制,既鼓励了简洁,又允许模型在面对难题时进行必要的深入思考。
通过SFT对齐Mentalese,再用SLPO进行强化学习,ORION模型成功地在保持简洁性的同时,恢复了绝大部分损失的性能。

惊人的实验效果:高效与高性能兼得
ORION的效果有多好?数据说明了一切。
研究者在AIME、MinervaMath、OlympiadBench等多个高难度数学推理基准上进行了广泛测试。
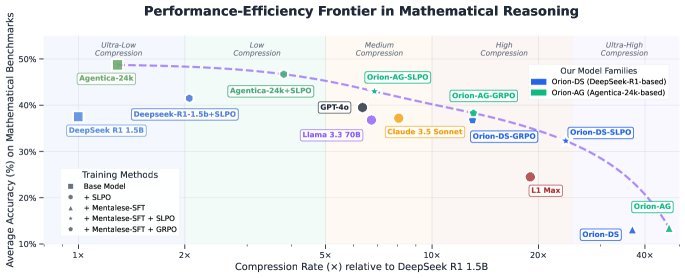
上图展示了不同模型在准确率和压缩率之间的权衡关系。ORION系列模型(图中橙色和绿色点)始终位于“帕累托前沿”(Pareto frontier)上,这意味着在同等压缩率下,它们的准确率最高;在同等准确率下,它们的压缩率最大。
具体来说:
-
极致压缩:与基线模型相比,ORION的推理路径缩短了4-16倍。
-
性能卓越:在多个数学基准上,ORION 1.5B模型的准确率比GPT-4o、Claude 3.5 Sonnet高出5%,同时推理长度仅为它们的一半。
-
成本骤降:由于Token数大幅减少,推理延迟最多降低5倍,训练成本也比传统的RL方法低7-9倍。
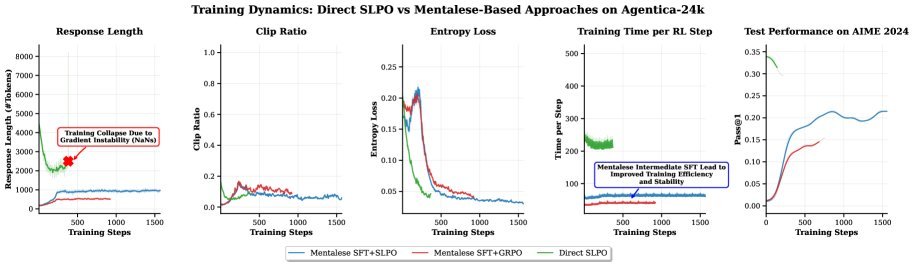
更有趣的是,研究发现,Mentalese对齐不仅提升了推理效率,还显著增强了强化学习阶段的训练稳定性,避免了模型因探索过长的推理路径而导致的“崩溃”现象。
总结与展望
ORION框架的提出,有力地证明了推理并不必然需要冗长的语言。通过将模型的思维过程重构为一种类似人类的、紧凑的符号语言,并结合智能的SLPO优化策略,我们可以在不牺牲(甚至提升)准确率的前提下,实现推理效率的巨大飞跃。
这项工作为部署高能效、低成本的推理模型开辟了新道路,尤其对于Agentic AI系统等对实时性和成本极其敏感的应用场景,意义重大。它让我们离那个能够像人类一样高效、精准思考的通用人工智能,又近了一步。