Parrot: A Training Pipeline Enhances Both Program CoT and Natural Language CoT for Reasoning
-
ArXiv URL: http://arxiv.org/abs/2510.25310v1
-
作者: Qi Zhang; Senjie Jin; Yuhui Wang; Tao Gui; Xinbo Zhang; Hong Lu; Sirui Song; Zhiheng Xi; Yuhao Zhou; Peng Sun; 等12人
-
发布机构: ByteDance Research; Fudan University; Shanghai Innovation Institute; Shanghai Key Laboratory of Intelligent Information Processing
TL;DR
本文提出了一种名为 Parrot 的新颖训练流水线,旨在通过三个专门设计的子任务和混合训练策略,相互增强程序思维链(P-CoT)和自然语言思维链(N-CoT)的性能,从而同时提升两种范式下的数学推理能力。
关键定义
本文的核心是围绕如何结合两种推理范式。关键定义如下:
- 自然语言思维链 (Natural language chain-of-thought, N-CoT):通过自然语言生成一系列中间推理步骤来解决复杂问题的方法。它更易于理解,适用范围广,但容易出现计算错误和逻辑混淆。
- 程序思维链 (Program chain-of-thought, P-CoT):利用代码(如Python)生成可执行的推理步骤来解决问题。它计算精确且易于验证,但在问题理解和变量定义方面较弱。
- Parrot Pipeline:本文提出的核心训练流水线,包含三个有序的子任务,旨在结构化地结合 N-CoT 和 P-CoT 的优点:
- 信息检索 (Information Retrieval, IR.): 从问题中提取关键信息,为生成 P-CoT 做准备。
- P-CoT 生成 (P-CoT Generation, P-gen.): 基于提取的信息生成代码解法。
- 转换的N-CoT生成 (Converted N-CoT Generation, C-gen.): 基于已生成的 P-CoT 及其执行的中间结果,生成一个解释性的 N-CoT。
- 子任务混合训练 (Subtask Hybrid Training):一种多任务监督微调(SFT)策略,将 Parrot 的三个子任务以及标准的 P-CoT 和 N-CoT 数据统一起来进行混合训练,以促进不同任务间的知识迁移。
- 转换的N-CoT辅助奖励 (Converted N-CoT auxiliary reward):在强化学习(PPO)阶段,利用 \(C-gen\) 任务中生成的 N-CoT 的正确性作为辅助奖励信号,来优化 P-CoT 的生成,以缓解仅依赖最终答案正确性的稀疏奖励问题。
相关工作
当前的语言模型在解决数学推理问题时,主要依赖两种范式:自然语言思维链(N-CoT)和程序思维链(P-CoT)。N-CoT 善于语义理解和展示详细的推理过程,但常受困于计算错误和逻辑不一致。P-CoT 则凭借代码的精确性保证了计算的准确性和可验证性,但在深入理解问题、抽象推理和变量定义方面表现不佳。
现有研究通常尝试单向增强,即用 N-CoT 辅助 P-CoT 的生成,或用 P-CoT 的结果来验证 N-CoT。然而,这两种范式之间的协同促进潜力尚未被充分挖掘。
本文旨在解决上述问题,通过对两种范式错误类型的深入分析,提出一种能够让它们互相借鉴优势、弥补对方缺陷的训练框架,最终实现两种推理能力的同步提升。
本文方法
动机与框架
基于对 N-CoT 和 P-CoT 错误的分析,本文提出了 Parrot 训练流水线,其核心思想是利用两种范式的优势来相互弥补不足,实现共同提升。该流水线通过结构化的子任务,先关注关键信息以生成定义良好的 P-CoT,再基于 P-CoT 及其精确的中间结果生成逻辑清晰的 N-CoT。
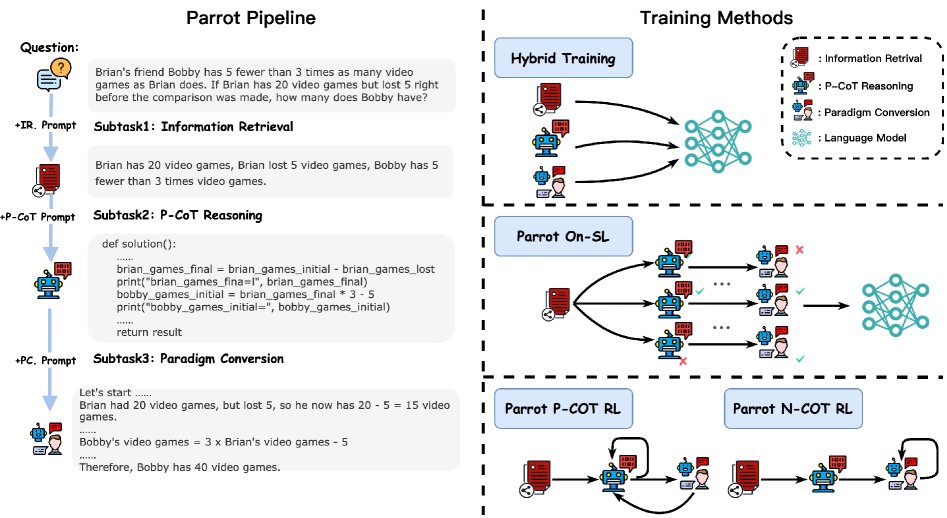
流水线子任务
Parrot 包含三个专门设计的子任务,模拟了人类解决问题的过程:
-
信息检索 (IR.): 首先,模型被训练从问题 $x$ 中提取关键的数字信息 $d_1$。这一步旨在解决 P-CoT 中常见的变量定义错误问题。
\[d_{1}\sim\Pi(\cdot \mid x\oplus p_{1})\] -
P-CoT生成 (P-gen.): 接着,模型利用上一步提取的关键信息 $d_1$ 来生成 Python 代码片段 $d_2$ 作为 P-CoT。
\[d_{2}\sim\Pi(\cdot \mid x\oplus p_{1}\oplus d_{1}\oplus p_{2})\] -
转换的N-CoT生成 (C-gen.): 最后,模型基于问题 $x$、已生成的 P-CoT ($d_2$) 及其执行产生的中间结果 $i$,生成一个更易于理解的 N-CoT ($d_3$)。
\[d_{3}\sim\Pi(\cdot \mid x\oplus p_{1}\oplus d_{1}\oplus p_{2}\oplus d_{2}\oplus i\oplus p_{3})\]这一步骤的创新点在于,它利用 P-CoT 简洁的推理步骤来缓解 N-CoT 的冗余问题,同时,P-CoT 的中间计算结果 $i$ 为 N-CoT 的生成提供了简单而有效的过程监督,显著减少了计算错误和逻辑不一致。
训练策略
子任务混合训练
本文没有按顺序训练三个子任务,而是采用了一种混合训练策略。所有子任务都被构造成统一的输入输出格式,并进行多任务监督微调(SFT)。这种策略旨在:
- 促进语义迁移:通过混合训练,N-CoT 详尽的推理过程可以帮助 P-CoT 更好地进行语义分析。
- 提升问题理解:P-CoT 和 N-CoT 两种不同形式的解法为模型提供了多样性,增强了对问题的理解。 最终目标是提升 P-CoT 的逻辑推理能力。
强化学习增强
在 SFT 初始化模型后,本文进一步引入强化学习来验证 Parrot 框架的有效性和数据效率。
- 在线自学习 (Online Self-learning, On-SL):模型生成 P-CoT 和 N-CoT 的解题轨迹,并将两者都正确的样本加入原始数据集中,用于进一步的 SFT。
-
近端策略优化 (PPO):为了解决 P-CoT 优化中奖励稀疏的问题(即只有最终答案正确才有奖励),本文设计了一个辅助奖励函数。该函数利用了 \(C-gen\) 步骤中转换生成的 N-CoT 的有效性来为 P-CoT 提供更密集的反馈信号。
\[R_{f}(s_{T-1},a_{T})=\left\{\begin{aligned} 1,\ \ \ \ &\text{两个答案都正确}\\ 1-\gamma,\ \ \ \ &\text{P-CoT正确, N-CoT为空}\\ \epsilon,\ \ \ \ &\text{P-CoT不正确, 但N-CoT是数字类型}\\ 0,\ \ \ \ &\text{P-CoT为空}\end{aligned}\right.\]当 P-CoT 正确但无法转换为有效的 N-CoT 时,会施加一个惩罚 $\gamma$,这鼓励模型生成更易于理解和转换的 P-CoT。
实验结论
主要性能
实验结果表明,Parrot 框架在 N-CoT 和 P-CoT 两种推理范式上均取得了显著的性能提升,尤其是在 N-CoT 上。
| 模型与方法 | 数据集 | LLaMA2-7B | CodeLLaMA-7B |
|---|---|---|---|
| N-CoT 推理 | |||
| SFT N-CoT | MathQA | 36.21 | 37.11 |
| SFT On-SL | MathQA | 42.13 | 43.14 |
| SFT PPO | MathQA | 45.32 | 47.16 |
| Parrot SFT N-CoT | MathQA | 58.08 | 58.59 |
| P-CoT 推理 | |||
| SFT P-CoT | MathQA | 46.04 | 47.04 |
| SFT On-SL | MathQA | 47.85 | 49.88 |
| SFT PPO | MathQA | 48.91 | 50.41 |
| Parrot SFT P-CoT | MathQA | 46.73 | 49.03 |
| Parrot RL P-CoT | MathQA | 51.24 | 51.62 |
- N-CoT 性能大幅提升:通过参考 P-CoT 及其精确的中间结果,Parrot 生成的 N-CoT 质量极高。在 MathQA 数据集上,相比于资源密集型的 RL 基线,Parrot SFT 使 LLaMA2 和 CodeLLaMA 的 N-CoT 性能分别提升了 \(+21.87\) 和 \(+21.48\),证明了其高效性。
- P-CoT 性能稳步增强:得益于信息检索子任务和混合训练带来的语义迁移,Parrot 在 P-CoT 上的表现也优于或持平于基线。结合 PPO 后,Parrot RL 相比基线 RL 取得了 \(2.33\) (LLaMA2) 和 \(1.21\) (CodeLLaMA) 的增益,说明了有效的模型初始化和奖励设计的优势。
- 适用性广泛:在 LLaMA-3、Qwen-2.5 等不同模型家族和尺寸上的实验也验证了 Parrot 框架的广泛适用性,并且在所有模型上都观察到了一致的性能提升。
消融分析
- 子任务的重要性:
- \(IR.\) 子任务在复杂数据集(如 MathQA)上对 P-CoT 的提升至关重要,它帮助模型准确识别和利用关键信息。
- \(C-gen.\) 子任务,特别是利用P-CoT的中间结果,是 N-CoT 性能提升的关键。缺少中间结果的监督,N-CoT 性能会大幅下降。
- 混合训练的有效性:混合训练确实将 N-CoT 的语义理解能力迁移到了 P-CoT,提升了 P-CoT 在简单数据集上的性能。
- 辅助奖励的作用:在 PPO 训练中,引入基于 N-CoT 质量的辅助奖励(惩罚)能有效防止模型陷入次优过拟合,使其训练过程更稳定、性能持续提升。
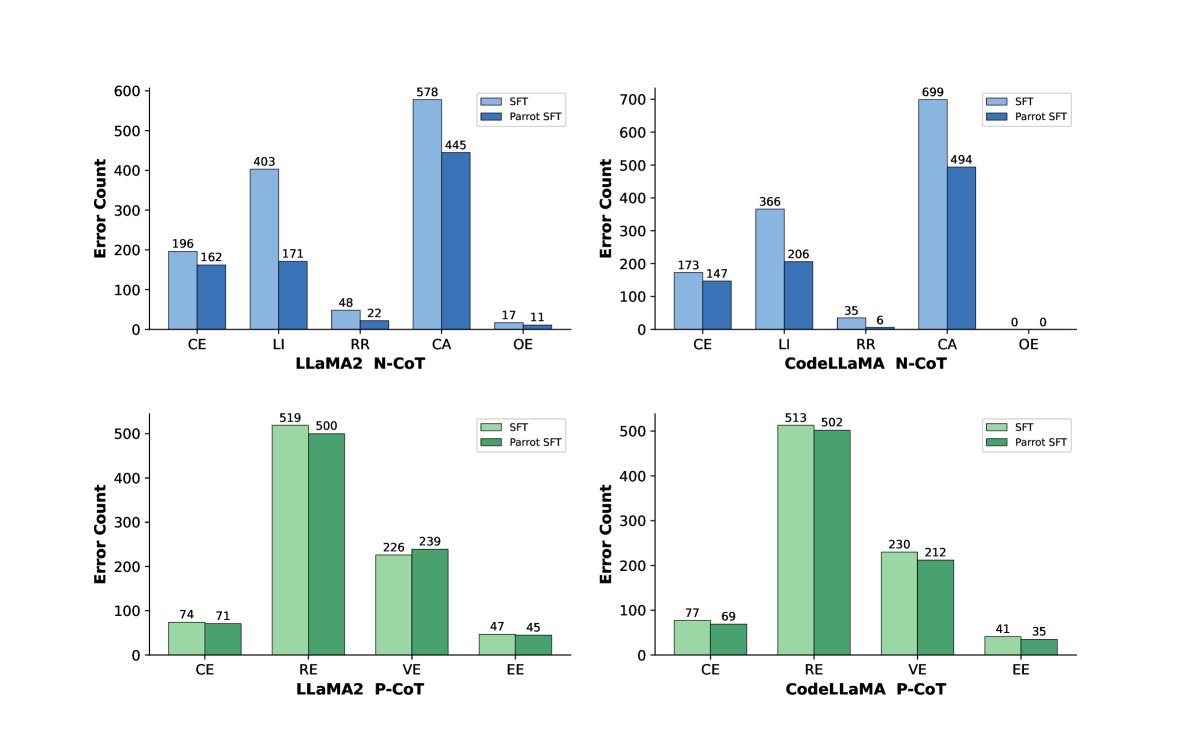
错误分析与数据质量
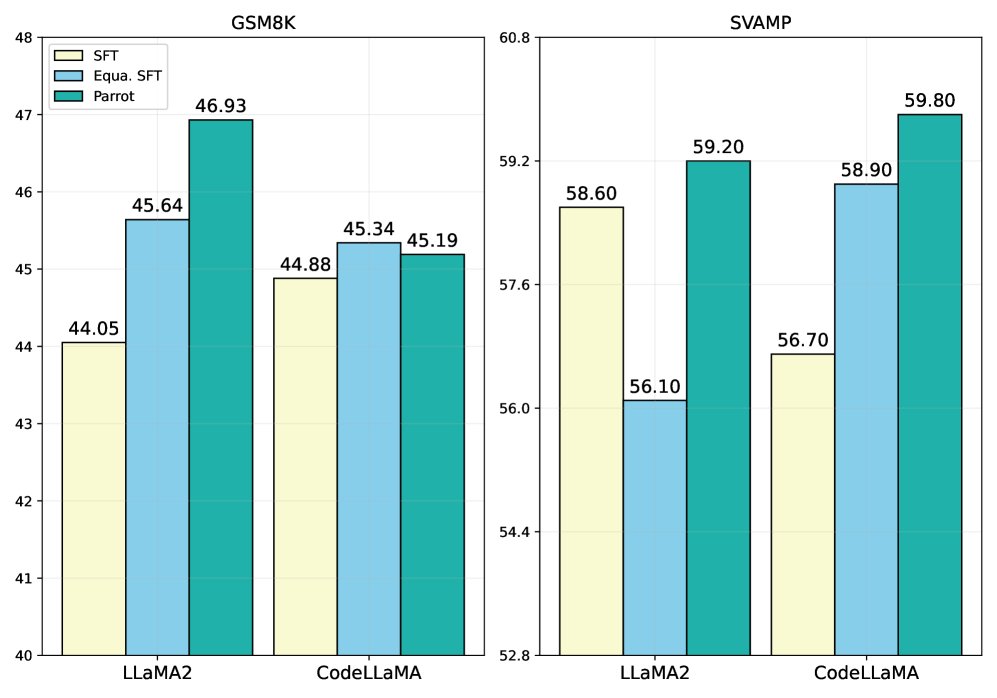
- 错误类型减少:Parrot 显著减少了 N-CoT 中的计算错误和逻辑不一致错误。这得益于 P-CoT 中间结果提供的过程监督。
- 高质量N-CoT数据:实验证明,通过 Parrot On-SL 收集的 N-CoT 数据质量远高于原始数据。使用这些高质量数据进行 SFT,模型性能超过了使用原始数据(即使是扩增后的数据),证明了 Parrot 能够生成优质的训练样本。
综上所述,Parrot 是一个高效且数据利用率高的训练框架,它通过巧妙地设计子任务和训练策略,成功地实现了 N-CoT和P-CoT两种推理范式的相互促进和同步增强。