Power-of-Two Quantization-Aware-Training (PoT-QAT) in Large Language Models (LLMs)
移位代替乘法!LLM推理提速10倍、内存节省87.5%的PoT-QAT技术

随着GPT-4、Llama 3等模型的参数量从几十亿一路狂飙到万亿级别,将这些庞然大物部署在手机、IoT设备等边缘端(Edge Devices)似乎成了一个不可能完成的任务。云端算力虽强,但高昂的成本和网络延迟始终是痛点。
ArXiv URL:http://arxiv.org/abs/2601.02298v1
如何在资源受限的设备上跑通大模型?斯坦福大学的研究团队提出了一项极具创意的解决方案:Power-of-Two Quantization-Aware-Training(PoT-QAT)。这项技术的核心思路非常极客——强行让神经网络的权重变成“2的幂次”(比如 $2^1, 2^{-3}$),从而将昂贵的乘法运算转化为极低成本的“位移”运算。
结果如何?在GPT-2模型上,这种方法实现了 87.5% 的内存节省,推理速度提升了 3-10倍,而精度损失微乎其微。
为什么选择“2的幂次”?
在深度神经网络(DNN)和大型语言模型(LLM)中,计算量最大的部分往往是矩阵乘法。在传统的全精度(Full-Precision)计算中,计算机需要处理复杂的浮点数乘法。
但是,在二进制的世界里,如果一个乘数是2的幂次(例如 $2, 4, 8, 0.5$ 等),乘法运算就可以被简单的位移操作(Bit Shifting)所取代。
-
乘以 $2$ ($2^1$) 等于左移1位。
-
乘以 $0.5$ ($2^{-1}$) 等于右移1位。
相比于乘法,位移操作在硬件层面上极其廉价且快速。本文提出的 PoT(Power-of-Two)量化,正是利用了这一特性。它不仅因为只需要存储指数而大幅节省内存,更重要的是,它从根本上降低了计算复杂度。
核心挑战:精度雪崩与QAT的救赎
虽然PoT听起来很美,但它是一种非常“激进”的量化方式。将原本连续分布的权重强行“规整”到最近的2的幂次上,会带来巨大的量化噪声。
如果直接对训练好的模型进行这种量化(即 训练后量化,Post-Training Quantization, PTQ),模型的性能往往会断崖式下跌,变得“胡言乱语”。
为了解决这个问题,研究团队引入了 量化感知训练(Quantization Aware Training, QAT)。
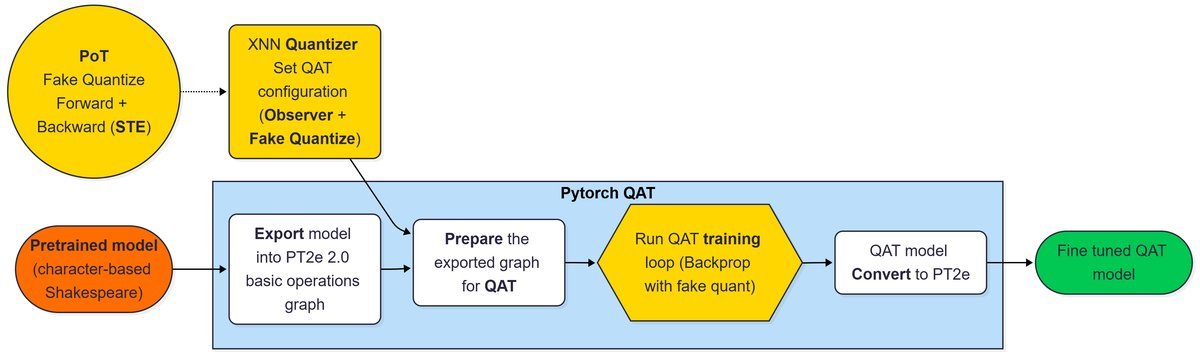
如上图所示,QAT的思路是在训练过程中就模拟量化的效果。模型在“知道”自己会被量化成2的幂次的前提下进行微调(Fine-tuning),从而学会适应这种离散的权重分布。
具体的量化公式如下:
\[y=2^{clip(round(\log_{2}(x/scale)))}\]通过这种方式,模型能够在训练中自我修正,弥补量化带来的精度损失。
实验验证:GPT-2上的惊艳表现
研究人员在 NanoGPT 框架下,使用 GPT-2 124M 参数模型和 OpenWebText 数据集进行了详尽的实验。
1. 训练收敛性
实验对比了不同量化精度的PoT设置(7级、11级、15级)。结果显示,经过QAT微调,模型的训练损失(Training Loss)和验证损失(Validation Loss)都能良好收敛。
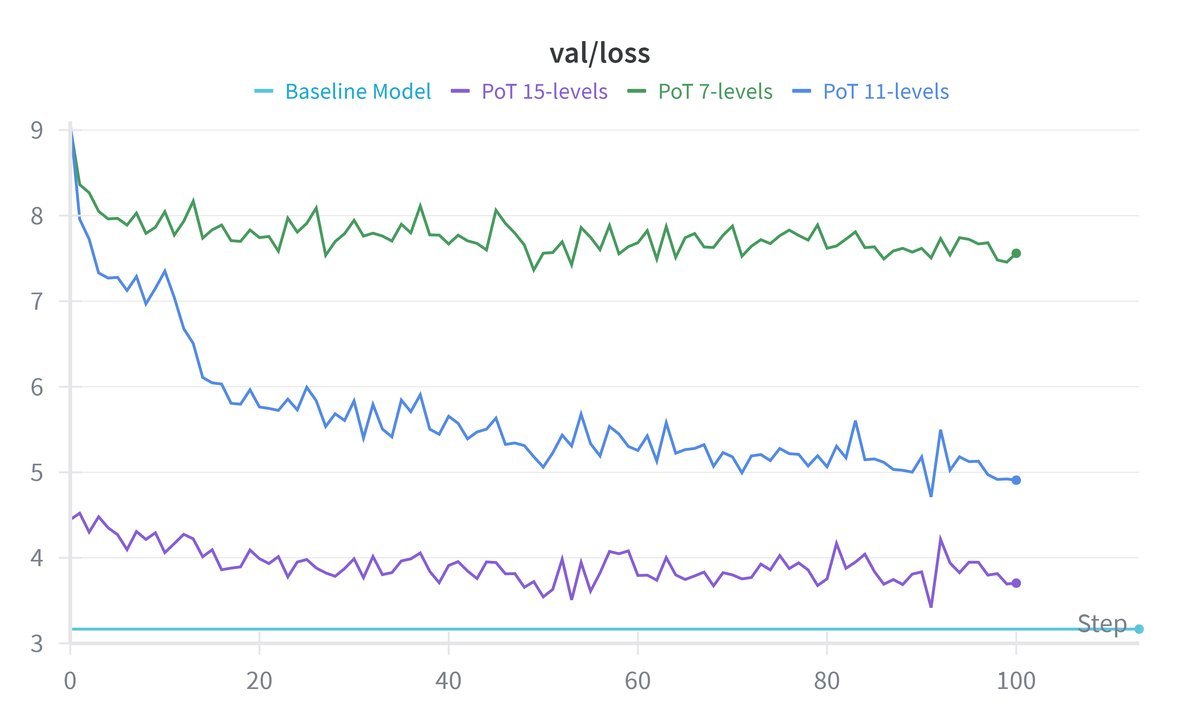
从上图的验证损失曲线可以看出,虽然量化初期会有性能下降,但随着训练进行,PoT 15-levels(对应 $[-2^7, 2^7]$)的性能几乎追平了全精度基线(Baseline)。
2. 困惑度(Perplexity)的大幅改善
困惑度是衡量LLM预测下一个Token能力的指标,越低越好。实验数据表明,相比于不重新训练的PTQ方法,经过QAT训练后的PoT模型表现出了巨大的提升。
- 对于15级PoT,QAT后的困惑度相比PTQ提升了 66%。
3. BERT-Score:几乎无损的语义理解
为了更接近人类的判断,研究者还使用了 BERT-Score 来评估生成文本的质量。
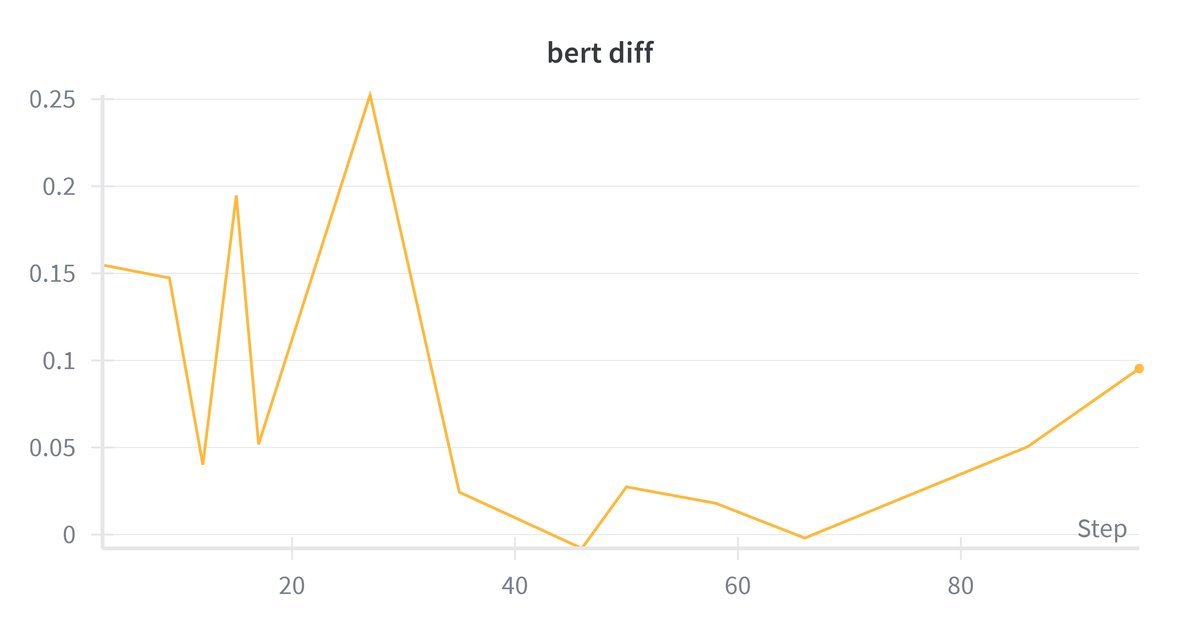
上图展示了量化模型与基线模型在BERT-Score上的差异。随着训练步数的增加,两者之间的差距迅速缩小。最终,量化模型与全精度GPT-2的BERT-Score差异仅为 0.0019,相当于仅有 1% 的性能损失。这意味着量化后的模型在生成文本的语义质量上,与原版几乎难以区分。
总结:边缘端AI的加速器
这项研究证明了 PoT-QAT 在大语言模型压缩领域的巨大潜力。让我们看看最终的收益账单:
-
内存节省:约 87.5%(从32-bit浮点压缩到4-bit左右的指数表示)。
-
速度提升:推理速度预计加快 3-10倍(得益于位移代替乘法)。
-
精度保持:在GPT-2上仅有 1% 的BERT-Score损失。
对于希望将LLM装进手机、智能眼镜或其他边缘设备的开发者来说,这种“移位代替乘法”的思路,无疑提供了一条极具吸引力的高效部署路径。未来的工作将进一步在Llama和Qwen等更大规模的模型上验证这一技术。