Prefill vs. Decode Bottlenecks: SRAM-Frequency Tradeoffs and the Memory-Bandwidth Ceiling
打破LLM能效瓶颈:32KB缓存+1.4GHz高频竟是最佳硬件甜点?

在当今的AI时代,数据中心的电力消耗正成为一个巨大的隐忧。据估计,2024年全球数据中心消耗了约415太瓦时(TWh)的电力,而随着大语言模型(LLM)的普及,这一数字预计到2030年将翻倍。
ArXiv URL:http://arxiv.org/abs/2512.22066v1
这就引出了一个价值百万美元的问题:我们该如何设计芯片架构,才能在保证LLM推理速度的同时,最大限度地降低能耗?
来自瑞典乌普萨拉大学(Uppsala University)的研究团队深入探究了芯片SRAM大小与运行频率对LLM推理能效的影响,并得出了一个反直觉的结论:有时候,“快”反而更省电,而“大”未必就好。
LLM推理的两张面孔:Prefill 与 Decode
要理解这项研究,首先得明白LLM推理过程分裂的“人格”。它主要包含两个截然不同的阶段:
-
预填充阶段(Prefill Phase):这是模型“阅读”你输入提示词(Prompt)的过程。它需要处理整个输入序列,进行大量的矩阵乘法运算。这是一个典型的计算密集型(Compute-bound)任务,GPU算力越强,处理越快。
-
解码阶段(Decode Phase):这是模型一个字一个字“吐”出答案的过程。每生成一个新Token,都需要重新加载庞大的模型参数,但每次计算量相对较小。这是一个典型的内存带宽密集型(Memory-bound)任务,速度主要受限于内存搬运数据的快慢。
核心发现:SRAM大小与频率的博弈
研究团队利用OpenRAM(能耗建模)、LLMCompass(延迟模拟)和ScaleSIM(脉动阵列模拟)构建了一套完整的仿真方法,得出了一些极具指导意义的结论。
1. 缓存越大,能耗越高?
很多硬件设计者倾向于增加片上SRAM(缓存)的大小以减少数据搬运。然而,研究发现,SRAM的大小主导了总能耗。
-
随着缓存变大,漏电流导致的静态能耗(Static Energy)显著增加。
-
虽然大缓存可能带来微小的延迟收益,但这完全无法抵消巨大的静态能耗成本。简单来说,为了那一点点速度提升而背负巨大的“待机功耗”,得不偿失。
2. 反直觉:高频反而更省电
通常我们认为,芯片频率越高,动态功耗越大,也就越费电。但在LLM推理中,情况发生了反转:
-
对于计算密集的Prefill阶段:提高频率能大幅缩短执行时间。虽然功率高了,但因为干活快,总的“开机时间”短了,反而降低了总能耗(主要是减少了静态能耗的累积)。
-
对于内存受限的Decode阶段:频率提升在一定范围内有效(约400MHz-600MHz),超过这个“膝点”后,受限于内存带宽,速度不再提升,但能耗也不会像想象中那样飙升,因为计算占比较小。
3. 寻找最佳甜点(Sweet Spot)
研究团队通过能量-延迟积(Energy-Delay Product, EDP)这一指标,寻找速度与能效的最佳平衡点。
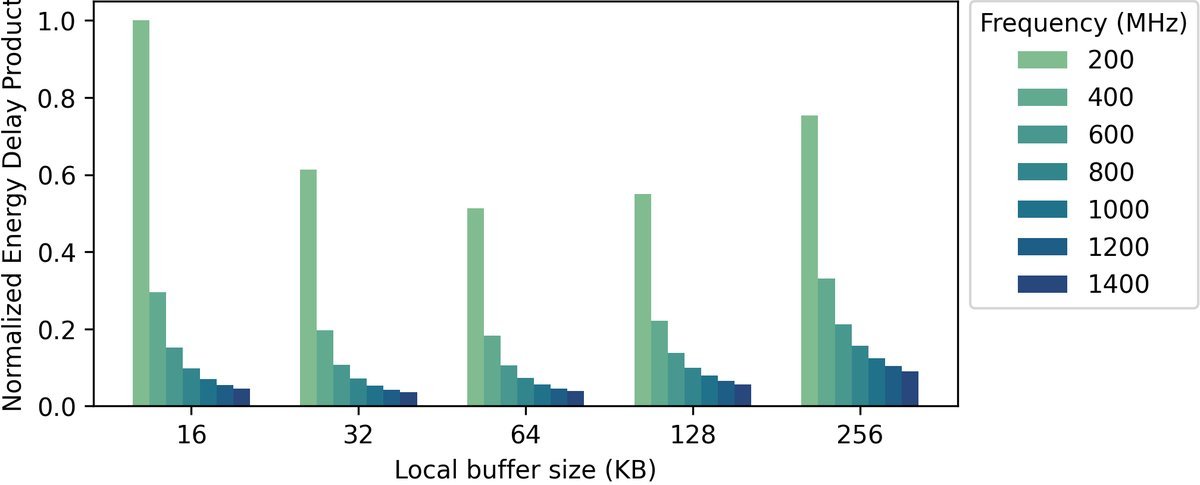
(图:Prefill阶段的能量-延迟积分析,颜色越深代表能效越好)
他们发现了一个最优的硬件配置组合:
-
高运行频率:1200MHz - 1400MHz
-
小SRAM缓存:32KB - 64KB
这个组合在保持低延迟的同时,实现了最高的能效比。这打破了“大缓存即正义”的传统观念。
内存带宽的天花板效应
研究还量化了内存带宽(Memory Bandwidth)作为性能“天花板”的作用。
在Decode阶段,内存带宽决定了性能的上限。通过Roofline模型分析发现:
-
当频率提升到一定程度,工作负载就会撞上“内存墙”。此时再提升计算频率,对性能几乎没有帮助。
-
增加内存带宽(例如从2048 GB/s翻倍到4096 GB/s)可以显著提高性能上限,并改变最佳硬件配置点(例如,带宽翻倍后,64KB缓存可能变得比32KB更优)。
总结与启示
这项研究为未来的AI加速器设计提供了明确的架构建议:对于以LLM推理为主的数据中心芯片,盲目堆砌片上SRAM可能是一种浪费。相反,设计者应该追求更高的计算频率,配合较小的本地缓存(32KB-64KB),并将重点放在提升外部内存带宽上。
在追求极致AI算力的道路上,”小而快”或许才是通往绿色计算的正确方向。