Prompt-R1: Collaborative Automatic Prompting Framework via End-to-end Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2511.01016v1
-
作者: Jiapu Wang; Haoming Liu; Xueyuan Lin; Haoran Luo; Rui Mao; Erik Cambria
-
发布机构: Hainan University; Hong Kong University of Science and Technology; Nanjing University of Science and Technology; Nanyang Technological University; National University of Singapore; Tsinghua University
TL;DR
本文提出了一种名为 Prompt-R1 的端到端强化学习框架,该框架通过训练一个小型语言模型(作为智能体)以多轮交互的方式生成并优化提示,从而与一个大型语言模型(作为环境)协作,以更低的成本和更高的效率解决复杂问题。
关键定义
本文提出或沿用了以下几个核心概念:
- Prompt-R1: 一个基于端到端强化学习的协作式自动提示框架。其核心思想是利用一个小型语言模型作为智能体,通过与大型语言模型的交互来学习如何生成最优的提示序列,以解决复杂任务。
- 智能体 (Agent): 在 Prompt-R1 框架中,由一个小型语言模型(small-scale LLM)扮演。它负责“思考”问题,生成引导性的提示,并根据大型语言模型的反馈进行多轮迭代,最终给出答案。
- 环境 (Environment): 在 Prompt-R1 框架中,由一个大型语言模型(large-scale LLM)扮演。它接收来自智能体的提示,并基于其强大的推理能力生成响应。该大型模型是“即插即用”的,无需额外训练。
- 多轮提示交互 (Multi-Turn Prompt Interaction): 智能体和环境之间进行的一系列“提示-响应”循环。智能体在每一轮都会根据历史交互记录调整其思考和提示,从而逐步引导环境逼近正确答案。
- 双约束奖励 (Double-constrained Reward): 为强化学习过程设计的特定奖励函数,包含两个部分:一是格式奖励 (format reward),确保智能体的输出(思考过程和提示)符合预设的结构和规范;二是答案奖励 (answer reward),评估最终答案的准确性。这种设计确保了模型在追求正确性的同时,也能生成结构良好、逻辑连贯的推理路径。
相关工作
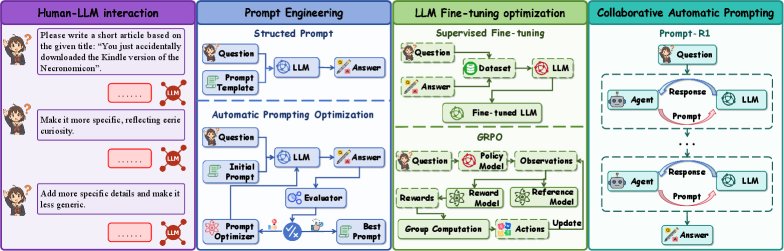
当前提升大型语言模型(LLMs)性能的方法主要包括提示工程、模型微调和基于强化学习的优化。
- 现状 (SOTA):
- 提示工程:如思维链(Chain-of-Thought, CoT)等方法通过设计结构化的提示来激发 LLMs的推理能力,但依赖人工设计。自动提示优化(APO)方法如 OPRO、TextGrad 等则尝试通过算法自动寻找更优的提示。
- 微调优化:如 LoRA 等参数高效微调方法能够使 LLMs 适应特定任务,但对大型模型而言,计算和存储开销巨大。
- 强化学习优化:如 RLHF 和 DPO 等方法利用反馈来对齐模型行为和提升推理能力,但通常直接作用于大型模型本身,训练过程复杂且昂贵。
- 关键问题与瓶颈:
- 小型 LLM 的能力局限:小型模型在处理长程依赖和复杂推理任务时表现不佳。
- 大型 LLM 的优化成本:微调大型模型需要巨大的计算资源,而基于 API 的调用方式成本高昂且无法进行自适应优化。
- 协作效率低下:现有方法往往依赖复杂的 API、冗余层或繁琐的提示工程,在动态、多任务环境中降低了协作效率和成本效益。
本文旨在解决上述问题,提出一个资源高效、自适应且可扩展的协作框架,让小型 LLM 能够有效利用大型 LLM 的能力,而无需对大型 LLM 进行微调。
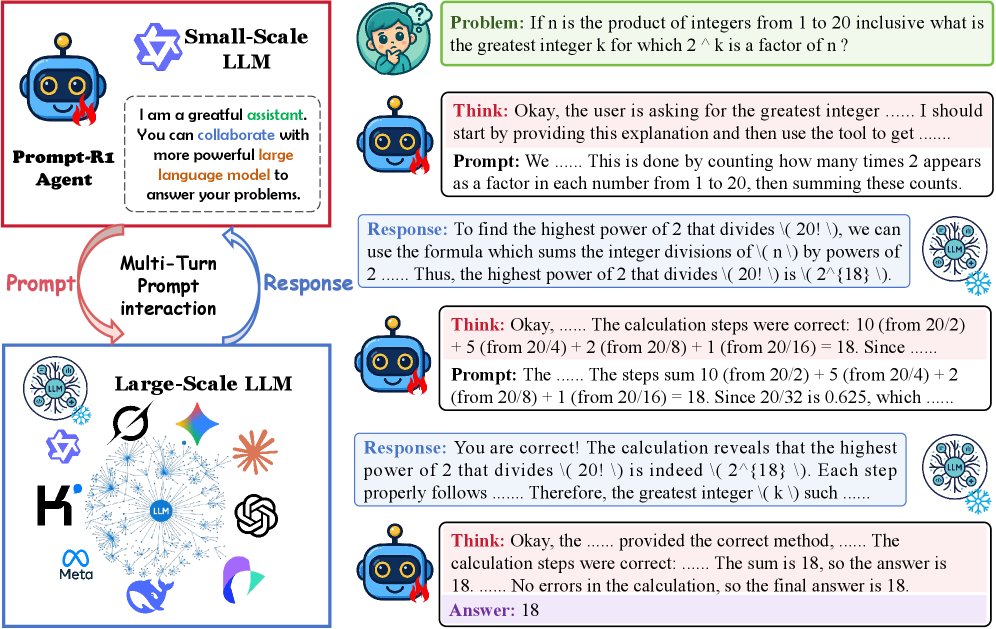
本文方法
Prompt-R1 框架的核心是一个由小型 LLM 扮演的智能体和一个由大型 LLM 扮演的环境之间的协作过程,整个过程通过强化学习进行端到端优化。
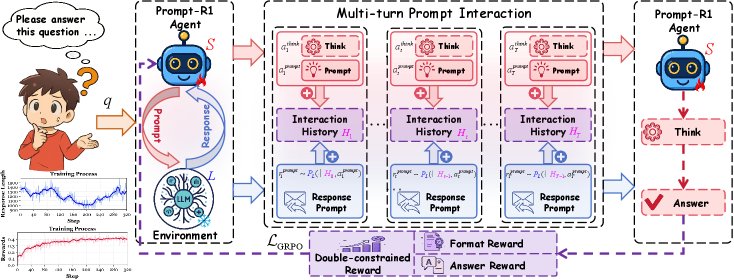
多轮提示交互框架
该框架将问题求解过程建模为智能体(小型 LLM $S$)和环境(大型 LLM $L$)之间的多轮对话。
- 角色定义:
- 智能体 \(S\) (Agent): 负责思考问题 \(q\),生成推理过程 $a_t^{\text{think}}$ 和交互提示 $a_t^{\text{prompt}}$。
- 环境 \(L\) (Environment): 接收智能体的提示,并生成回应 $r_t^{\text{prompt}}$。
- 交互流程:
-
在第 \(t\) 轮,智能体 \(S\) 基于历史交互记录 $H_{t-1}$ 和问题 \(q\) 生成一个动作,该动作包括“思考”和“生成提示”两部分:
\[(a_t^{\mathrm{think}}, a_t^{\mathrm{prompt}}) \sim S(q, H_{t-1})\] -
环境 \(L\) 接收提示 $a_t^{\text{prompt}}$ 并生成回应:
\[r_t^{\mathrm{prompt}} \sim P_L(\cdot \mid H_{t-1}, a_t^{\mathrm{prompt}})\] - 历史记录被更新 $H_t = H_{t-1} \oplus (a_t^{\text{prompt}}, r_t^{\text{prompt}})$,为下一轮交互做准备。
- 这个过程重复 \(T\) 轮,直到智能体决定生成最终答案 \(y\)。
-
双约束强化学习优化
为了让智能体学会如何生成高质量的提示,本文设计了一个基于强化学习的优化策略,其核心是双约束奖励函数和 GRPO 优化目标。
- 创新点:双约束奖励 (Double-constrained Reward) 该奖励 \(R\) 包括两个部分,旨在同时保证生成过程的规范性和最终结果的准确性。
-
格式奖励 $R_{\text{fmt}}$: 用于确保智能体在每一步都生成了非空的思考和提示,并且最终答案的格式正确、内容完整。
\[R_{\mathrm{fmt}}=\min\!\Bigl(\epsilon,\;\alpha\!\sum_{t=1}^{T-1}\!M_{t}+\beta A_{p}+\gamma A_{n}+\delta C_{f}\Bigr)\]其中 $M_t$ 检查中间步骤的完整性,$A_p, A_n, C_f$ 检查最终答案的合规性。
-
答案奖励 $R_{\text{ans}}$: 使用 F1 分数来衡量预测答案 $\hat{a}$ 与标准答案 \(g\) 之间的一致性。
\[R_{\text{ans}}=\max_{g\in\mathcal{G}(q)}\mathrm{F1}(\hat{a},g)\] -
门控组合: 这是一个关键设计,只有当格式完全正确时 ($R_{\text{fmt}}=\epsilon$),答案奖励才会被计入总奖励 \(R\) 中。这强制智能体首先学会“说正确的话”,然后才去追求“说得对”。
\[R=\begin{cases}-\epsilon+R_{\text{fmt}}+R_{\text{ans}},&R_{\text{fmt}}=\epsilon,\\ -\epsilon+R_{\text{fmt}},&\text{otherwise},\end{cases}\]
-
-
优化目标: 本文采用基于 GRPO (Group Relative Policy Optimization) 的损失函数,将轨迹级别的奖励转化为 Token 级别的权重,从而实现端到端优化。它通过对一个批次内的奖励进行标准化,计算出优势值 $\hat{A}^{(i)}$,并用其加权策略的对数似然损失。
\[\mathcal{L}_{\mathrm{GRPO}} = \frac{1}{M}\sum_{i=1}^{M}\frac{1}{ \mid u^{(i)} \mid }\sum_{t=1}^{ \mid u^{(i)} \mid }\Bigl[-\hat{A}^{(i)}\log\pi_{\theta}\!\left(w_{t}^{(i)}\mid u^{(i)}_{<t},q\right) + \beta\,\mathrm{KL}(\dots)\Bigr]\]该目标函数鼓励奖励高的轨迹,同时通过 KL 散度约束防止策略偏离初始的参考策略太远。
高效的训练与推理
该框架的最大优点之一是其“即插即用”的特性,实现了训练和推理阶段的解耦。
- 训练阶段: 可以使用任意一个开源的大型 LLM(例如 \(m_train\))作为环境,来训练智能体(小型 LLM)的策略 \(π_θ\)。这个过程可以在本地或私有环境中完成,成本可控。
- 推理阶段: 训练好的智能体可以与任何其他大型 LLM(例如 \(m_test\),可以是闭源的 API 模型如 GPT-4o-mini)协作。这意味着,只需训练一次小型智能体,就能将其能力“迁移”并赋能给多个不同的、更强大的大型模型,大大提高了框架的灵活性和实用性。
实验结论
实验围绕 Prompt-R1 的有效性、泛化性、可迁移性及组件有效性等多个研究问题展开。
- 有效性 (RQ1): Prompt-R1 在八个公开数据集上的表现显著优于基线方法(如 SFT, CoT)和其他自动提示优化方法(如 OPRO, TextGrad)。在多跳推理、数学计算、标准问答和文本生成等多种任务上均取得了最佳性能,尤其在需要复杂推理的多跳问答任务上提升最为明显。
| 方法 | 多跳推理 (F1) | 标准问答 (F1) | 数学推理 (EM) | 文本生成 (SSim) | |||||
|---|---|---|---|---|---|---|---|---|---|
| 任务 | 2Wiki | Hotpot | MusiQue | PopQA | GSM8K | DAPO | BookSum | W.P | 平均 |
| 基线 (GPT-4o-mini) | 39.5 | 45.2 | 34.6 | 60.1 | 55.4 | 51.5 | 60.8 | 63.5 | 51.3 |
| SFT | 38.3 | 43.5 | 34.2 | 59.9 | 53.9 | 50.1 | 60.1 | 62.4 | 50.3 |
| CoT | 41.8 | 46.0 | 36.1 | 62.1 | 57.2 | 53.0 | 62.9 | 65.0 | 53.0 |
| OPRO | 44.5 | 49.3 | 37.9 | 64.9 | 59.6 | 55.3 | 64.8 | 67.2 | 55.4 |
| TextGrad | 42.1 | 47.7 | 36.8 | 63.5 | 58.1 | 53.7 | 63.3 | 66.0 | 53.9 |
| GEPA | 43.6 | 48.1 | 37.4 | 64.1 | 59.0 | 54.7 | 64.2 | 66.8 | 54.8 |
| Prompt-R1 | 47.6 | 52.3 | 41.2 | 68.2 | 63.4 | 58.6 | 69.3 | 71.7 | 59.0 |
| $\Delta$$\uparrow$ | +8.1 | +7.1 | +6.6 | +8.1 | +8.0 | +7.1 | +8.5 | +8.2 | +7.7 |
- 泛化性 (RQ2): 在四个分布外(OOD)数据集上的测试表明,Prompt-R1 具有很强的泛化能力。即使在未经训练的任务上,其性能也全面超越了其他方法,证明了该框架学习到的“如何提问和协作”的策略是通用的,而不仅仅是针对特定任务的过拟合。
| 方法 | AMBIGQA (F1) | SQuAD2.0 (F1) | TriviaQA (EM) | XSUM (SSim) | 平均 |
|---|---|---|---|---|---|
| 基线 | 35.1 | 65.5 | 73.0 | 39.0 | 53.2 |
| SFT | 34.8 | 64.2 | 72.5 | 38.4 | 52.5 |
| CoT | 36.9 | 67.3 | 75.2 | 41.2 | 55.2 |
| OPRO | 38.8 | 69.8 | 77.8 | 43.5 | 57.5 |
| TextGrad | 37.4 | 68.0 | 76.1 | 41.9 | 55.9 |
| GEPA | 38.1 | 69.2 | 77.0 | 42.8 | 56.8 |
| Prompt-R1 | 41.3 | 71.5 | 80.3 | 45.6 | 59.7 |
| $\Delta$$\uparrow$ | +6.2 | +6.0 | +7.3 | +6.6 | +6.5 |
- 可迁移性 (RQ3/RQ5): 实验证明了 Prompt-R1 的“即插即用”特性。使用开源模型(零成本环境)训练的智能体,可以直接与 GPT-4o-mini 等闭源模型(开销环境)协作,并显著提升其性能。如下图所示,在多个数据集和 LLM 上,配备了 Prompt-R1 智能体的模型性能均得到一致提升,证明了该框架的策略可被成功迁移。
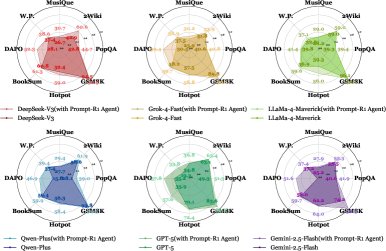

- 最终结论: Prompt-R1 框架通过让一个经过强化学习训练的小型智能体与大型 LLM 协作,成功地提升了在复杂任务上的表现。它不仅在多种任务和数据集上超越了现有方法,还展示了出色的泛化和迁移能力。这一“小模型指导大模型”的模式为高效、低成本地利用和增强现有 LLM 的能力提供了一条新的、有前景的路径。