QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
QwenLong-L1.5:挑战GPT-5,揭秘400万字长文本推理的“后训练”秘籍

长文本模型仅仅意味着“读得更多”吗?
ArXiv URL:http://arxiv.org/abs/2512.12967v1
在当今的大模型竞赛中,将上下文窗口扩展到百万级Token已非难事,但真正的瓶颈在于:当模型面对海量信息时,能否不仅仅是进行简单的“大海捞针”式检索,而是像人类专家一样,跨越数万字甚至数百万字的跨度,进行复杂的逻辑推理和多跳论证?
阿里巴巴通义实验室(Tongyi Lab)最新发布的 QwenLong-L1.5 给出了强有力的回应。这项研究并没有止步于模型架构的微调,而是提出了一套完整的后训练配方(Post-Training Recipe)。通过系统性的数据合成、稳定的强化学习策略以及创新的记忆增强架构,QwenLong-L1.5 在长文本推理基准上平均提升了 9.9 分,性能直逼 GPT-5 和 Gemini-2.5-Pro,更在 400 万 Token 的超长任务中展现了惊人的统治力。
告别“大海捞针”:高质量数据合成流水线
长文本推理训练最大的痛点是什么?是数据的匮乏。现有的数据集往往局限于简单的检索任务(Retrieval),难以训练模型进行深度的多跳推理。
为了解决这个问题,该研究开发了一套系统化的 长文本数据合成流水线(Long-Context Data Synthesis Pipeline)。这套流水线不再满足于生成简单的问答,而是致力于构建需要“多跳锚定”(Multi-hop Grounding)的复杂推理任务。
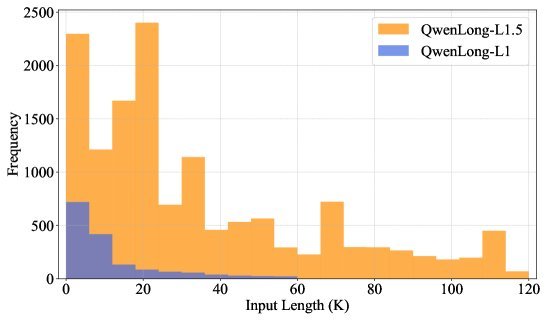
其核心逻辑在于“解构与重组”:
-
深度多跳推理 QA:利用知识图谱(Knowledge Graph)技术,将文档解构为原子事实及其相互关系。通过在图谱上进行随机游走和路径采样,构建出跨越文档不同部分的复杂推理路径,从而生成必须结合多处证据才能回答的难题。
-
语料库级数值推理 QA:针对财经、科研等场景,通过结构化表格数据引擎,将非结构化文档转化为结构化表格,再利用 SQL 执行生成复杂的数值计算和统计聚合问题。
-
多智能体自进化:引入 多智能体自进化(Multi-agent Self-evolve, MASE)框架,让提问者、解答者和验证者三个智能体相互博弈,自动生成并演进出难度逐渐提升的通用长文本推理任务。
这种方法让训练数据从本质上超越了简单的“查找”,迫使模型真正学会“思考”。
驯服不稳定性:长文本强化学习的进阶
有了数据,如何训练又是一个难题。在长文本场景下,强化学习(RL)面临着极大的不稳定性:不同任务的奖励分布差异巨大,且随着序列长度增加,探索与利用的平衡极难把控。
QwenLong-L1.5 引入了两项关键的 RL 创新技术:
-
任务平衡采样与特定优势估计:
传统的随机采样会导致训练批次内的数据分布失衡。该研究采用了 任务平衡采样(Task-balanced Sampling),并配合 任务特定优势估计(Task-specific Advantage Estimation)。简单来说,就是根据不同任务类型的奖励分布特征,分别计算优势函数,消除了奖励偏差,确保模型不会偏科。
-
自适应熵控制策略优化(AEPO):
为了在长序列训练中维持探索性,研究团队提出了 自适应熵控制策略优化(Adaptive Entropy-Controlled Policy Optimization, AEPO)。该算法通过动态调节探索与利用的权衡,有效控制了负梯度的影响,使模型能够在序列长度逐步增加的过程中保持训练的稳定性。
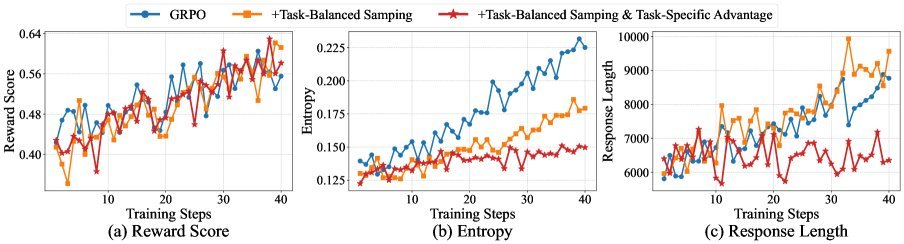
从上图的训练动态可以看出,结合了这两项技术的 RL 策略(红色曲线),在保持奖励增长的同时,极大地稳定了熵值(Entropy)和响应长度,避免了训练崩溃。
突破物理极限:400万 Token 的记忆增强架构
即使是最先进的模型,其物理上下文窗口也是有限的(通常为 128K 或 256K)。当面对 100 万甚至 400 万 Token 的超长任务时,该怎么办?
QwenLong-L1.5 给出的答案是:记忆增强架构(Memory-Augmented Architecture)。
该研究并未强行拉长注意力窗口,而是设计了一个 记忆管理框架(Memory Management Framework)。对于超长任务,模型采用“记忆代理”(Memory Agent)模式:
-
单次推理:在 256K 窗口内,模型利用强大的注意力机制进行直接推理。
-
迭代记忆处理:对于超出窗口的任务,模型通过迭代的方式阅读文本块,动态更新其内部记忆状态 $(m_t, p_t)$,并在最后基于累积的记忆生成答案。
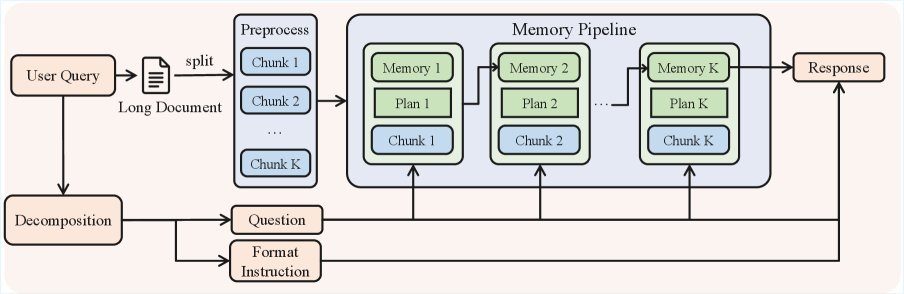
为了让模型同时具备这两种能力,研究团队采用了一种 多阶段融合 RL 训练(Multi-stage Fusion RL Training)范式。先分别训练全上下文推理专家和记忆管理专家,然后通过模型融合技术将其合二为一。
实验结果:硬刚顶流模型
基于 Qwen3-30B-A3B-Thinking 模型,QwenLong-L1.5 的表现如何?
-
综合性能:在六大长文本推理基准测试中,QwenLong-L1.5 平均超越基线模型 9.90 分,性能与 GPT-5 和 Gemini-2.5-Pro 处于同一梯队。
-
超长任务:在 1M 到 4M Token 的超长任务上,得益于记忆代理框架,其表现比仅使用代理的基线高出 9.48 分。
-
泛化能力:这种长文本推理能力的提升,还外溢到了科学推理、工具使用和长对话等通用领域,证明了该后训练配方的普适性。
QwenLong-L1.5 的出现,不仅展示了国产大模型在长文本领域的强劲实力,更重要的是,它为业界提供了一套从数据合成到 RL 训练的可复现、系统化的技术路径。长文本推理,正在从“读完”走向“读懂”。