Read As Human: Compressing Context via Parallelizable Close Reading and Skimming
像人一样“精读+略读”:RAM长文本压缩框架实现12倍加速

面对动辄几万字的超长文档,人类是如何阅读的?我们通常不会逐字逐句地读完每一个字,而是会快速略读(Skimming)背景信息,一旦发现与目标相关的关键段落,就会立刻切换到精读(Close Reading)模式。
ArXiv URL:http://arxiv.org/abs/2602.01840v1
然而,现有的大语言模型(LLM)在处理长文本时却显得有些“死板”。无论是RAG(检索增强生成)还是长上下文窗口模型,它们往往需要处理海量的冗余信息,这不仅导致了巨大的计算开销,还会因为“迷失在中间”效应而降低回答准确率。
今天为大家解读的这篇论文 RAM (Read As HuMan),由阿里巴巴、清华大学等机构联合提出。它巧妙地模仿了人类的阅读策略,提出了一种并行化的上下文压缩框架。RAM 不仅在长文本任务上超越了现有基线,更在 16K 到 32K 的长输入下实现了高达 12倍 的端到端加速!
为什么要模仿人类阅读?
现有的长文本压缩方法主要分为两类,但都有明显的痛点:
-
任务无关压缩:不管用户问什么,都按统一标准压缩。这容易把关键信息当成废话扔掉。
-
任务感知压缩:虽然会根据 Query(问题)来压缩,但现有方法要么需要一次性加载全部上下文(显存爆炸),要么依赖自回归式的压缩(速度极慢)。
RAM 的核心洞察在于:高效的压缩应当是并行的,且保留形式应当是混合的。
如下图所示,相比于一次性加载(图a)和自回归压缩(图b),RAM(图c)采用了并行处理策略,并根据相关性自适应地决定哪些段落该“精读”,哪些该“略读”。
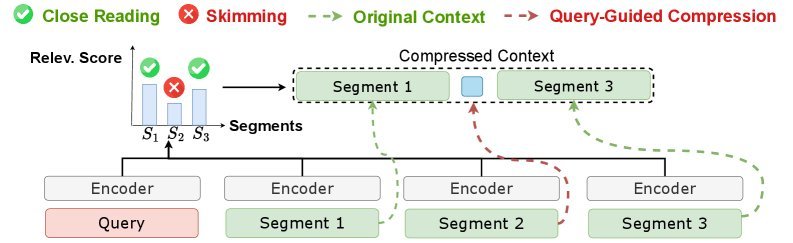
RAM 技术核心:并行编码与混合压缩
RAM 的工作流程非常清晰,主要包含两个阶段:查询感知的并行编码 和 自适应压缩与训练。
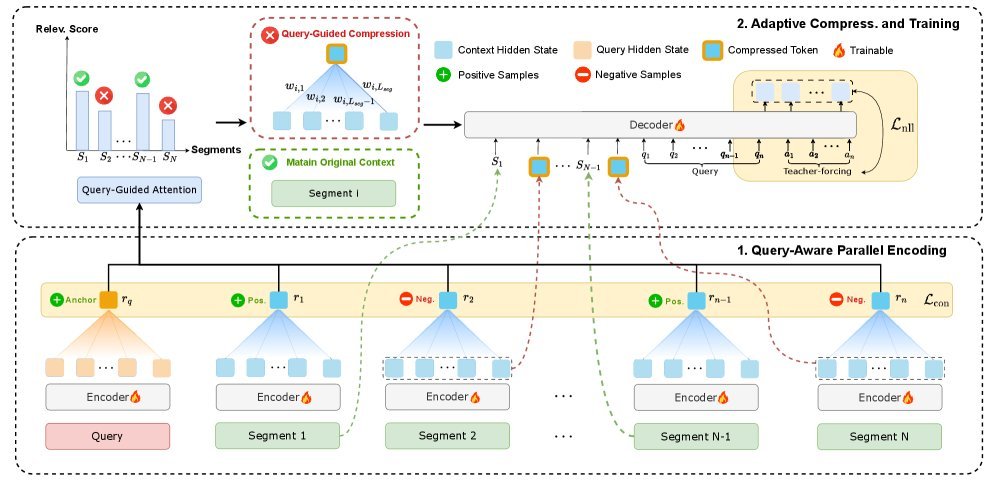
1. 并行分块与相关性计算
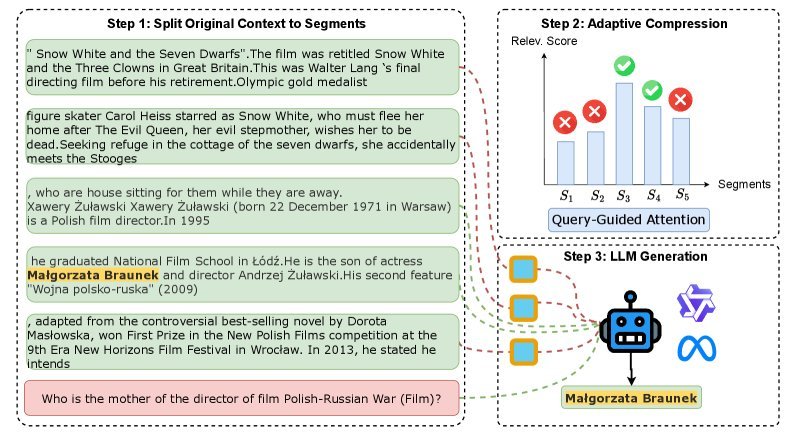
RAM 首先将长上下文 $\mathbf{C}$ 切分为 $N$ 个等长的片段(Segments),记为 ${S_1, S_2, \dots, S_N}$。
与传统方法不同,RAM 不需要让片段之间互相进行复杂的注意力计算,而是将所有片段与用户的查询 $Q$ 一起,并行地 输入到一个共享的编码器中。这直接避免了长序列自注意力带来的 $O(L^2)$ 复杂度噩梦。
对于每个片段 $S_i$,模型会计算它与查询 $Q$ 的相关性分数 $p_i$。这个分数由查询向量 $\mathbf{r}_q$ 和片段向量 $\mathbf{r}_i$ 的余弦相似度经过 $softmax$ 得到:
\[p_{i}=\frac{\exp\left(\mathbf{r}_{q}^{\top}\mathbf{r}_{i}/\tau\right)}{\sum_{j}\exp\left(\mathbf{r}_{q}^{\top}\mathbf{r}_{j}/\tau\right)}\]2. 精读(Close Reading) vs. 略读(Skimming)
这是 RAM 最精彩的设计。根据计算出的相关性分数,模型会动态决定每个片段的命运:
-
精读(High Relevance):对于相关性最高的 Top-k 个片段,RAM 会完整保留其原始文本 Token。这样做的好处是最大程度保留了关键信息的语义细节和可解释性。
-
略读(Low Relevance):对于相关性较低的片段,RAM 不会直接丢弃(防止丢失全局语境),而是将其压缩为一个紧凑的摘要向量(Summary Vector)。
压缩公式如下,其中 $w_{i,t}$ 是基于查询相关性的权重:
\[\mathbf{c}_{i} =\sum_{t=1}^{L_{\text{seg}}}w_{i,t}\,\mathbf{h}_{i,t}\]最终,解码器的输入是一个混合表示:由显式的文本 Token(来自精读片段)和隐式的向量 Embedding(来自略读片段)拼接而成。这种设计既保留了人类可读的自然语言格式,又极大地压缩了无关信息的长度。
3. 对比学习优化决策边界
为了让模型更聪明地判断“什么是重点”,研究团队引入了一个对比学习目标(Contrastive Learning Objective)。
通过构建正样本(包含答案的片段)和负样本(不含答案的片段),模型被训练去最大化查询与正样本片段的相似度,同时最小化与负样本的相似度。这使得 RAM 在区分“该精读”还是“该略读”时更加果断和准确。
实验结果:速度与效果的双赢
研究团队在 HotpotQA、NaturalQuestions 等多个问答和摘要基准上进行了测试,并在 LLaMA-3.1-8B 和 Qwen3-4B 两个基座模型上验证了效果。
1. 性能全面超越基线
如下表所示,在 4倍 和 8倍 的压缩率下,RAM 几乎在所有数据集上都取得了最优(Bold)的成绩。特别是在 NaturalQuestions 数据集上,RAM 的表现显著优于 LongLLMLingua 等强力基线。
(注:表格数据展示了 RAM 在不同数据集上的 EM 和 F1 分数,均优于对比方法)
2. 惊人的推理加速
效率是 RAM 的杀手锏。由于采用了并行编码和激进的“略读”策略,RAM 在处理长文本时表现出极高的效率。
实验数据显示,在平均长度 16K、最大长度 32K 的输入场景下,RAM 实现了高达 12倍 的端到端速度提升。这意味着原本需要处理几秒钟的长文档任务,现在可以在毫秒级完成。
3. 强大的长度外推能力
虽然 RAM 仅在最大 20K 长度的数据上进行训练,但在 NarrativeQA(测试长度达 32K)上的表现依然出色。这证明 RAM 并非死记硬背位置信息,而是真正学会了基于语义的相关性判断,具备良好的泛化能力。
总结
RAM 框架为长文本处理提供了一个优雅且高效的解法。它没有暴力地截断文本,也没有盲目地压缩所有信息,而是像人类专家一样,懂得在“精读”与“略读”之间灵活切换。
RAM 的核心贡献在于:
-
并行化架构:解决了长文本压缩的计算瓶颈。
-
混合表示:结合了文本的可解释性和向量的高压缩比。
-
对比学习:强化了模型对关键信息的捕捉能力。
对于正在构建 RAG 应用或长文档分析工具的开发者来说,RAM 提供了一个值得借鉴的新范式:有时候,读得快且读得好,关键在于懂得“略过”什么。