KV缓存减半,性能反超!阿里FusedKV揭示K/V不对称共享新范式

大模型处理长文本的能力越来越强,但一个幽灵始终在数据中心徘徊——那就是庞大的键值缓存(Key-Value Cache, KV Cache)。它像一个无底洞,吞噬着宝贵的显存,让长文本推理的成本居高不下。
ArXiv URL:http://arxiv.org/abs/2512.03870v1
人们想了各种办法给KV缓存“瘦身”,比如分组查询注意力(Group-Query Attention, GQA)或者跨层共享缓存。但这些方法往往有个“潜规则”:用性能换效率。
有没有可能打破这个规则,既要显存减半,又要性能更强?
来自阿里巴巴、中科院等机构的最新研究《FusedKV》给出了一个惊人的答案:完全可以!他们提出了一种全新的跨层融合策略,不仅将KV缓存需求直接砍掉50%,模型性能(以困惑度衡量)甚至超越了标准的Transformer。
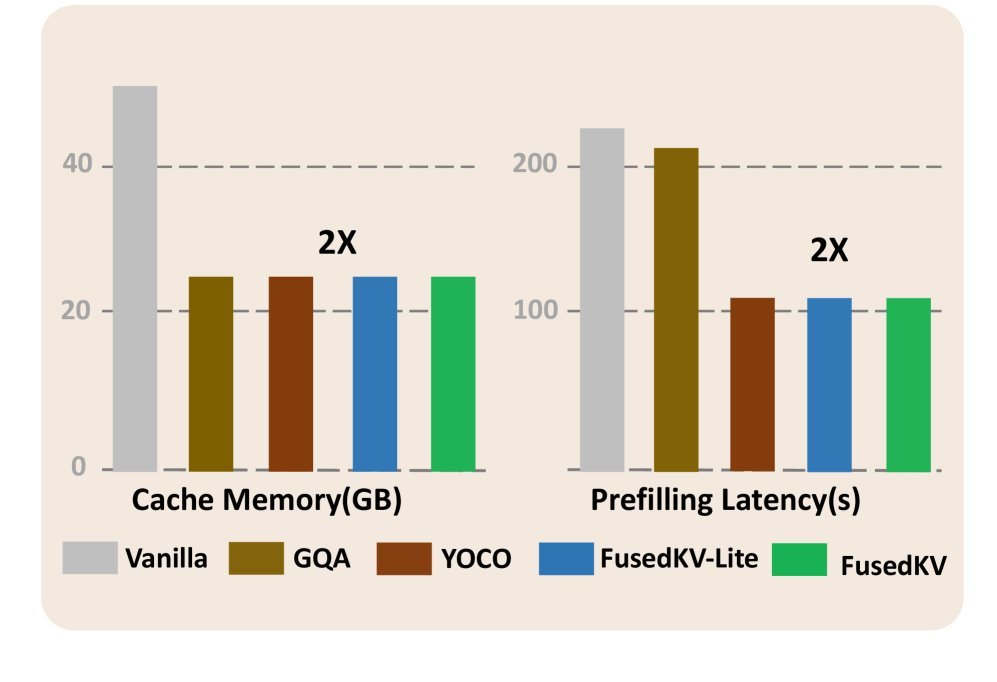
图1:FusedKV(绿色)和FusedKV-Lite(蓝色)在将KV缓存减半、预填充延迟降低近2倍的同时,在1.5B模型上取得了比其他方法更优的预训练损失。
这究竟是如何做到的?
关键发现:K与V的不对称性
传统跨层共享方法(如YOCO、CLA)通常将Key和Value视为一个整体进行复用,但效果总是不尽人意。这篇研究的作者们深入探究了其根源,提出了一个灵魂拷问:Key和Value在Transformer的不同层中,扮演的角色真的相同吗?
通过一个巧妙的实验,他们发现了一个被长期忽视的不对称原则:
-
Value(V):模型顶层(后几层)的Value,其信息主要来源于底层(前几层)。这很符合直觉,因为底层网络负责提取最基础、最原始的文本特征,是“内容”的主要来源。
-
Key(K):而顶层的Key,其信息则更多地来源于底层和中间层。Key的作用更像是“索引”或“查询”,它需要结合浅层的基本信息和中层的抽象语义,来决定在注意力计算中关注哪些内容。
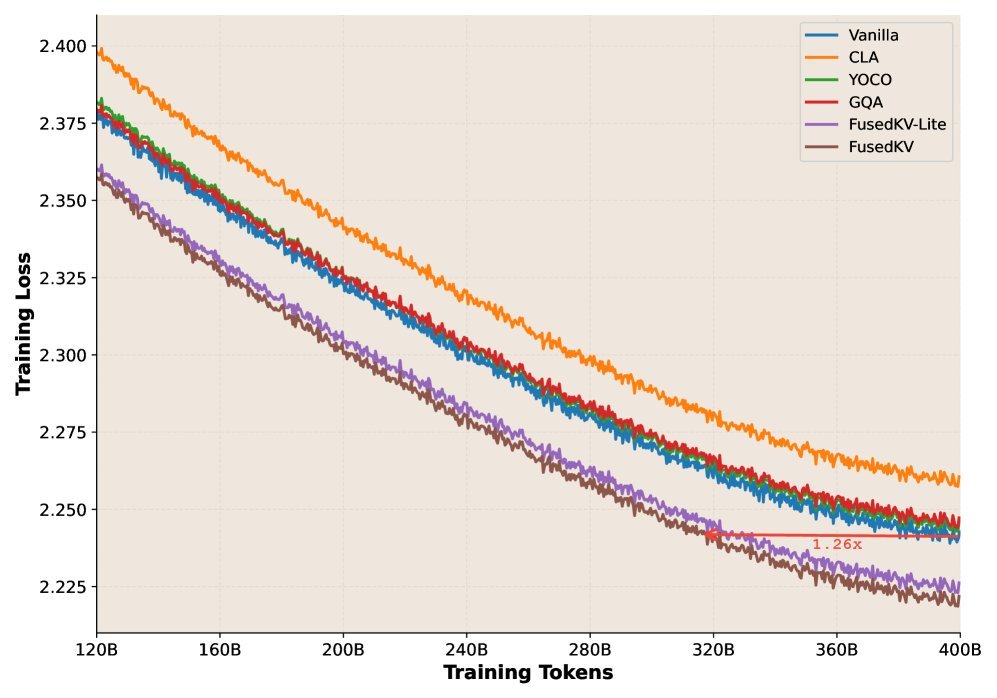
图2:在一个16层模型中,重构顶层8个层的Key(左)和Value(右)的融合权重。可以清晰地看到,Value的权重高度集中在第0-1层,而Key的权重则更多地分布在第6-7层。
这个发现就像捅破了一层窗户纸:简单粗暴地把K和V捆绑在一起跨层共享,无疑会造成信息错配,性能下降也就在所难免。
FusedKV与FusedKV-Lite:优雅的解决方案
基于上述发现,研究者设计了两种全新的架构:FusedKV 和 FusedKV-Lite。
其核心思想是将模型分为两部分:
-
存储层(Storage Layers):通常是模型的下半部分(如前$n$层),它们的KV缓存会被正常计算和存储。
-
重构层(Reconstruction Layers):模型的上半部分($n$层之后),它们的KV缓存不再独立存储,而是通过一个函数从存储层动态“生成”。
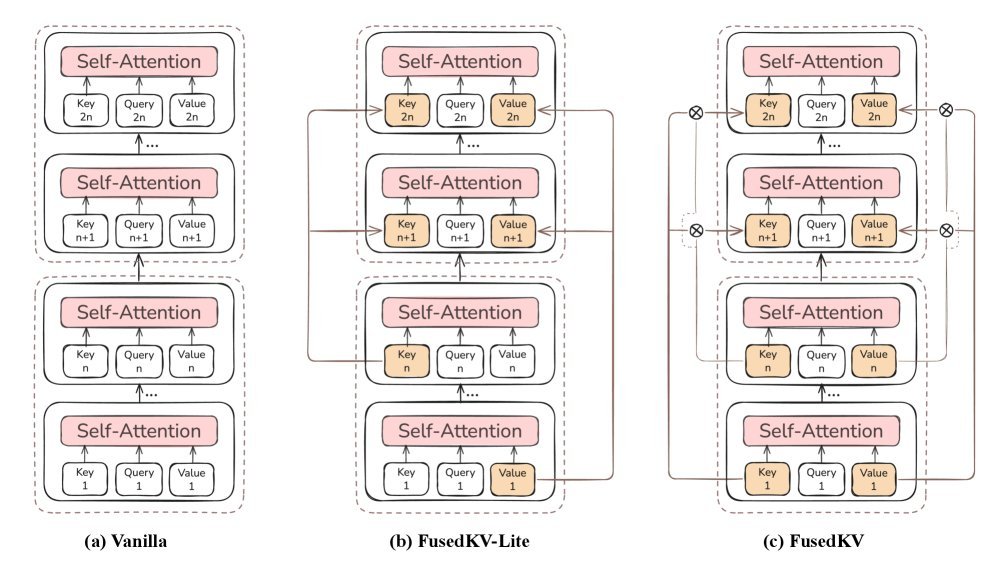
图3:(a) 标准Transformer;(b) FusedKV-Lite,顶层Key复用中间层,Value复用最底层;(c) FusedKV,顶层K/V由最底层和中间层的K/V加权融合而成。
FusedKV-Lite:简单高效
这是最直接的实现方式。对于所有重构层(比如第$i > n$层):
-
它的Key缓存直接复用中间层(第$n$层)的Key缓存。
-
它的Value缓存直接复用最底层(第1层)的Value缓存。
公式表达为:
\[{\mathbf{K}}^{i}={\mathbf{K}}^{n},\quad{\mathbf{V}}^{i}={\mathbf{V}}^{1},\quad i>n\]这种设计完美遵循了K/V不对称原则,且由于只是直接复用,几乎不增加额外的计算和I/O开销,极致高效。
FusedKV:性能更强
为了追求更强的表达能力,FusedKV更进一步。对于重构层:
-
它的Key缓存是最底层和中间层Key缓存的可学习加权融合。
-
它的Value缓存也是最底层和中间层Value缓存的可学习加权融合。
公式表达为:
\[{\mathbf{K}}^{i} ={\mathbf{a}}\_{i,1}\odot{\mathbf{K}}^{1}+{\mathbf{a}}\_{i,n}\odot{\mathbf{K}}^{n},\quad i>n\] \[{\mathbf{V}}^{i} ={\mathbf{b}}\_{i,1}\odot{\mathbf{V}}^{1}+{\mathbf{b}}\_{i,n}\odot{\mathbf{V}}^{n},\quad i>n\]这里的 $\odot$ 表示逐元素相乘,而权重 $a$ 和 $b$ 是可学习的参数。这使得模型可以根据不同层的需要,动态地调整从底层和中层获取信息的比例,从而在保持高效的同时,获得更强的表征能力。
值得一提的是,研究者还从数学上证明了这种融合操作与广泛使用的旋转位置编码(RoPE)是兼容的,确保了模型的位置信息不会在融合过程中被破坏。
实验效果:不仅省,而且强
理论再好,也要看疗效。FusedKV在一系列从332M到4B参数规模的模型上进行了严苛的测试,结果令人振奋。
1. 性能超越基线
在多个模型规模的实验中,FusedKV不仅成功将KV缓存减半,其验证集损失(Validation Loss)始终低于标准的Transformer模型。这意味着在相同的训练量下,FusedKV学得更好、性能更强。
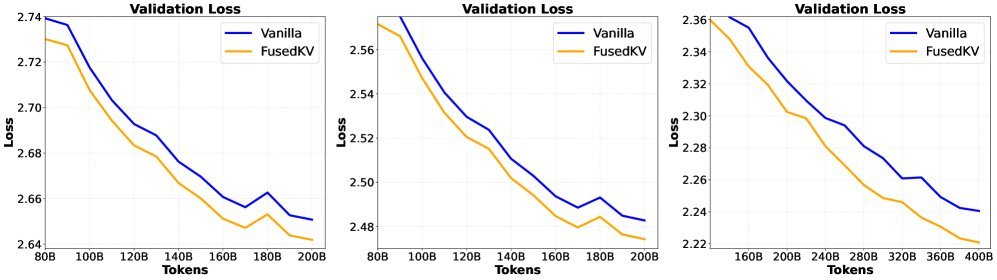
图6:在332M、650M和1.5B模型上,FusedKV(绿色)的验证损失持续低于标准模型(蓝色)。
2. 推理速度优势
-
首字延迟(TTFT):由于重构层无需计算和写入KV缓存,FusedKV和FusedKV-Lite的预填充(Prefilling)阶段延迟相比标准模型降低了约50%,让你更快看到第一个字的输出。
-
后续字延迟(TPOT):在解码阶段,FusedKV-Lite的I/O开销与标准模型相当,速度几乎无损。FusedKV虽然因融合操作有轻微的I/O增加,但在计算密集型场景下(如使用GQA),这点开销可以被有效隐藏,速度依然媲美基线。
3. 良好的扩展性
研究还发现,随着模型参数从332M增长到4B,FusedKV相比标准模型展现出更优的扩展效率(Scaling Law)。这意味着模型越大,FusedKV的优势可能越明显,这对于未来更大规模模型的研发极具吸引力。
梯度流动的启示
为什么FusedKV能取得如此优异的性能?研究者通过可视化梯度发现,FusedKV和FusedKV-Lite在训练过程中,其浅层网络(如第1层)的梯度范数明显大于基线模型。
更大的梯度意味着更强的参数更新信号。这表明,FusedKV的融合机制促进了梯度更有效地回传到模型的初始几层,加速了这些“地基”层的学习和收敛,从而为整个模型的层次化特征学习打下了更坚实的基础。
总结
FusedKV这项研究的价值远不止于提出一个KV缓存压缩工具。它揭示了Transformer内部信息流动的深刻洞见——Key和Value在功能上的不对称性。
基于这一发现,FusedKV和FusedKV-Lite巧妙地设计了跨层共享机制,实现了KV缓存减半、预填充加速一倍,同时模型性能反超标准Transformer的“三赢”局面。它为设计内存高效且性能卓越的大模型架构开辟了一条全新的道路,证明了“鱼与熊掌”亦可兼得。在追求更大、更长上下文能力的今天,FusedKV无疑为大模型的实际部署和应用注入了一剂强心针。